突破易盾2.28.5文字点选验证码:逆向参数破解与轨迹模拟实战
本文全面拆解易盾2.28.5版文字点选验证码的逆向流程,包括图片接口cb参数生成、文字坐标识别、验证接口data加密解析以及真实鼠标轨迹模拟。通过详细代码示例和步骤指导,展示完整实现路径,同时讨论实际开发中的优化技巧与替代方案,为爬虫与自动化项目提供实用参考。
易盾文字点选验证码逆向分析背景与核心机制
在现代网络爬虫和自动化测试场景中,验证码一直是反爬机制的重要组成部分。易盾作为一款成熟的验证码服务,其文字点选类型在2.28.5版本中强化了加密逻辑和行为检测能力。这种验证码要求用户在图片上点击指定文字,背后涉及图片动态生成、坐标加密传输以及鼠标轨迹验证等多重防护。开发者如果直接绕过,往往需要深入理解前端JS脚本的混淆逻辑和后端校验规则。本文将一步步还原整个逆向过程,帮助技术人员掌握关键实现细节,避免常见的调试陷阱。
文字点选验证码的核心在于动态图片和交互行为验证。服务器端会根据请求生成带文字标注的图片,同时返回需要点击的文字列表。客户端点击后,浏览器会收集坐标、时间戳和移动轨迹,形成加密数据包发送回服务器校验。2.28.5版本特别加强了参数混淆和数组长度随机化,使得单纯的静态分析难以奏效。理解这些机制,不仅能用于特定场景的自动化,还能为后续类似验证码的破解提供通用思路。
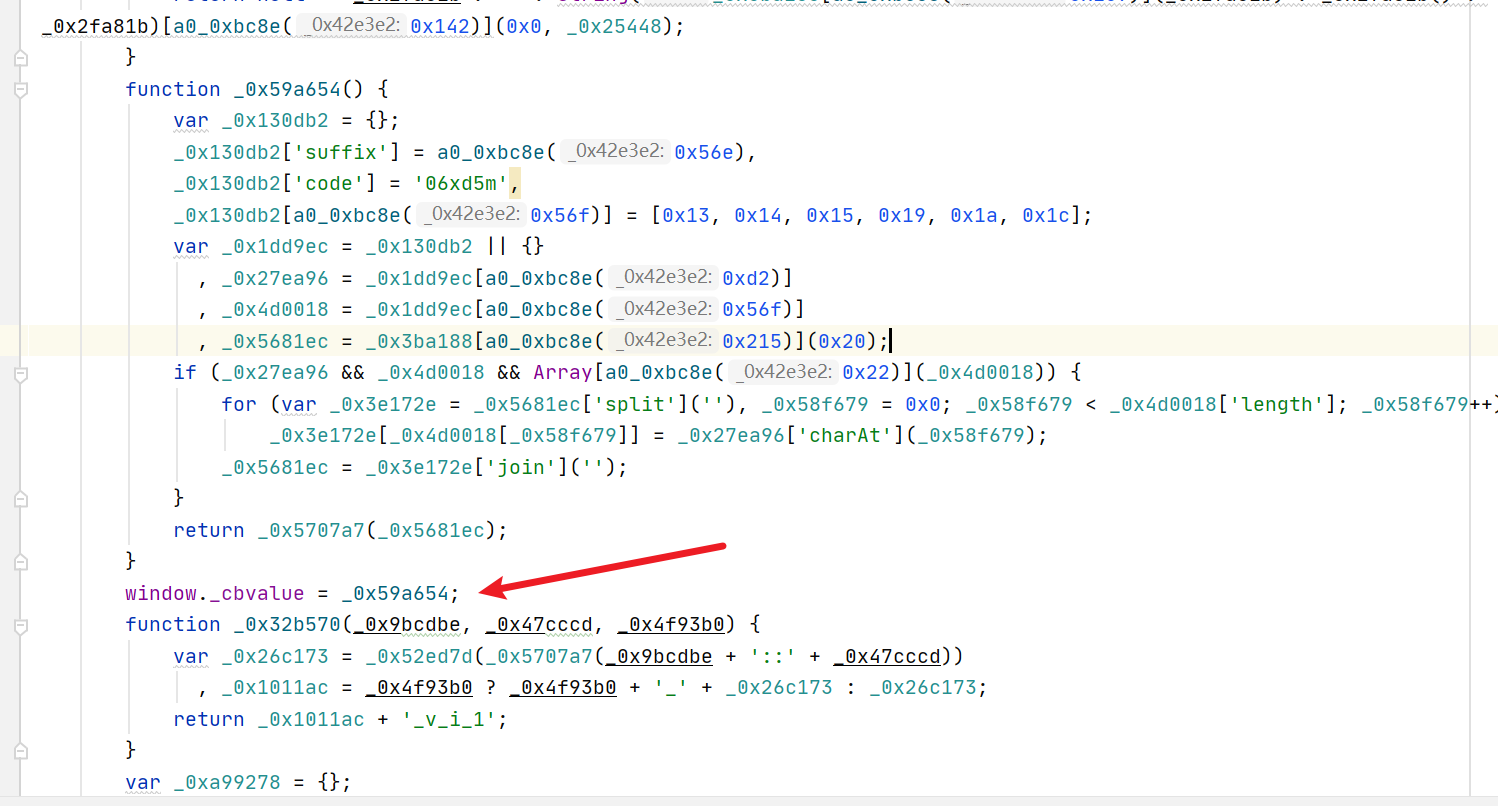
图片接口cb参数的生成与环境补全
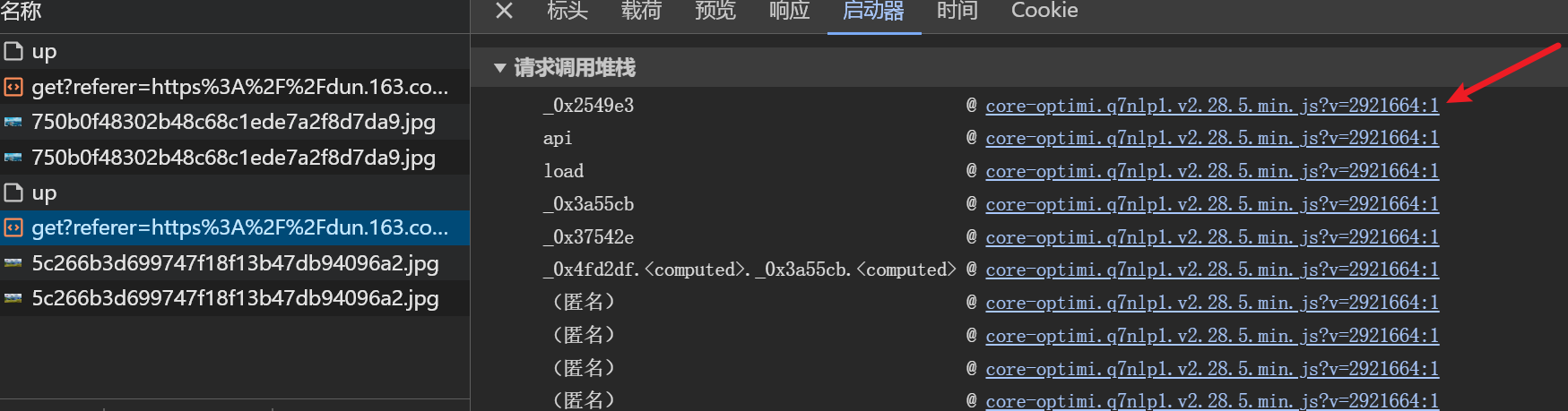
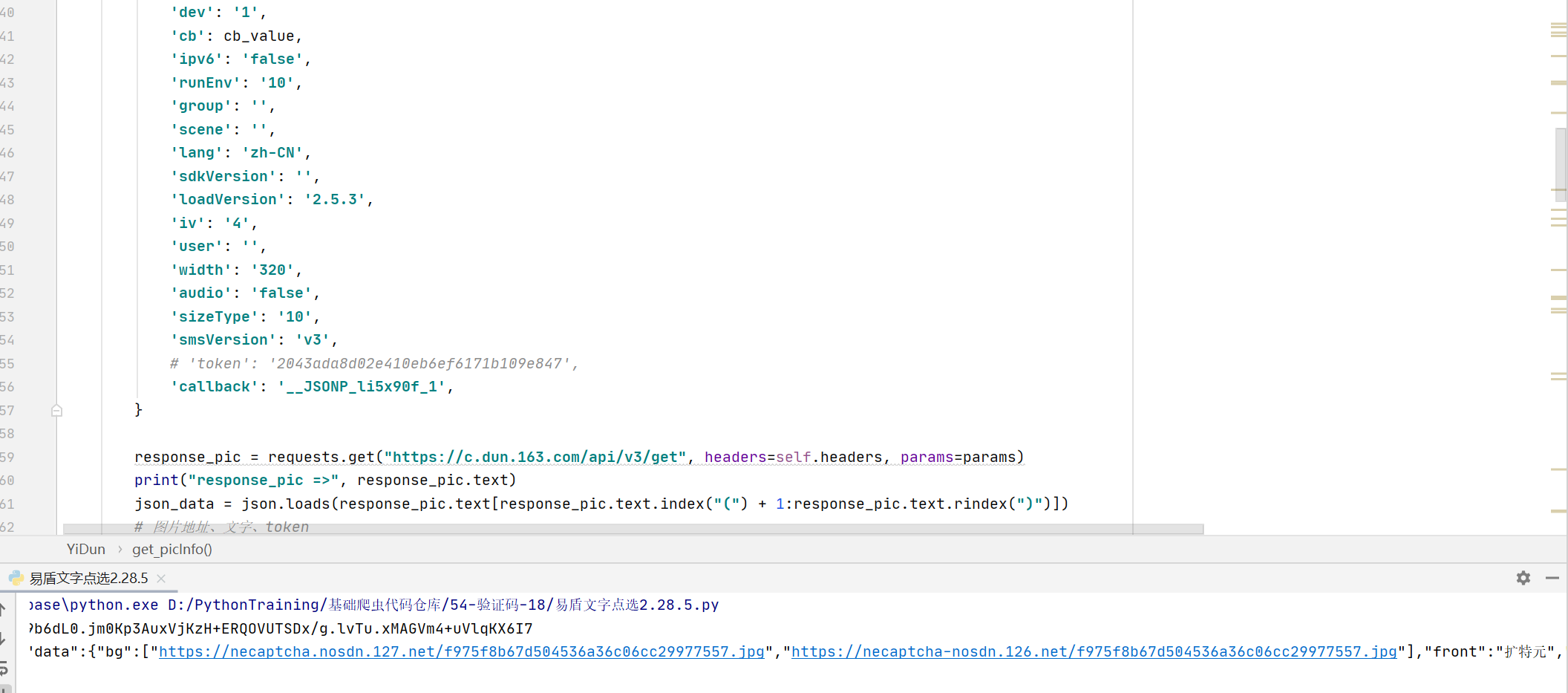
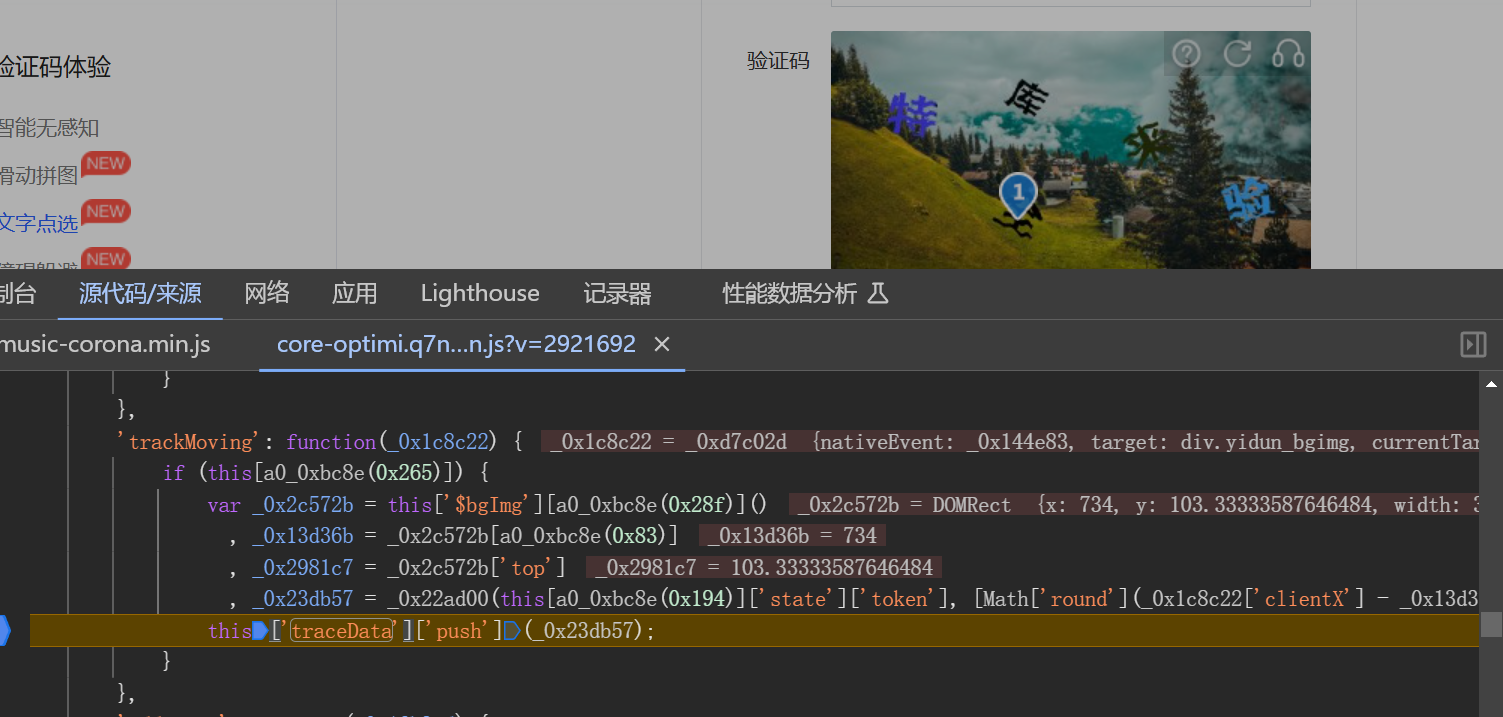
刷新目标页面后观察网络请求,会发现图片资源通过GET接口动态加载。请求载荷包含大量加密字段,其中dt、id和fp这几个参数值是固定的,可以直接写死在代码中。irToken和token即使省略也不会影响图片返回,因此真正需要关注的只有cb变量。这个参数由前端JS脚本计算得出,属于典型的混淆加密结果。
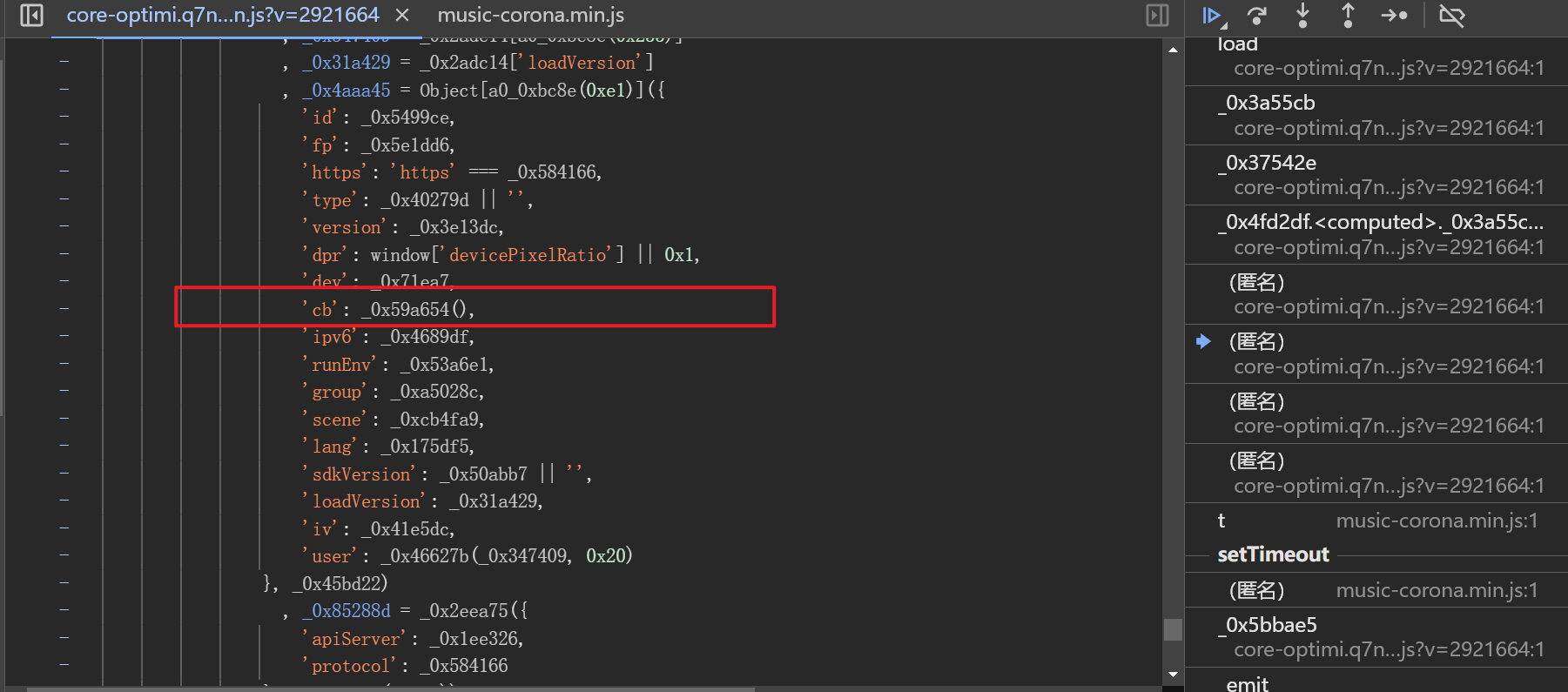
由于接口是JS驱动的,常规XHR断点往往无法直接捕获。我们可以借助浏览器启动器工具逐步跟踪调用栈。经过耐心向上追溯,最终定位到cb值的返回函数。该函数位于混淆后的脚本内部,需要将整个JS文件导出并补全运行环境才能独立调用。补环境时重点关注window、document、navigator和location对象的基本方法,例如addEventListener、createElement和userAgent字符串模拟。这些对象只需实现最常用逻辑即可满足脚本执行需求。
window = global;
window.addEventListener = function(args) {
console.log('addEventListener参数:', args);
};
document = {
body: {},
createElement: function(args) {
if (args === 'div') {
return {
addEventListener: function(args) { console.log('div事件:', args); },
getAttribute: function(args) { console.log('属性获取:', args); }
};
}
},
addEventListener: function(args) { console.log('document事件:', args); },
getElementById: function(args) { console.log('元素ID:', args); }
};
navigator = {
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
};
location = {
href: 'https://dun.163.com/trial/picture-click',
origin: 'https://dun.163.com',
hostname: 'dun.163.com'
};
// 导出cb生成函数
function getCbParam() {
return window._cbvalue();
}
补全上述环境后,直接调用导出函数即可获得有效cb值。使用Python的requests库构造GET请求,传入cb参数后就能成功拉取图片URL、待点击文字列表以及后续校验所需的token。这些基础数据是整个验证链路的起点,后续所有步骤都依赖于此。
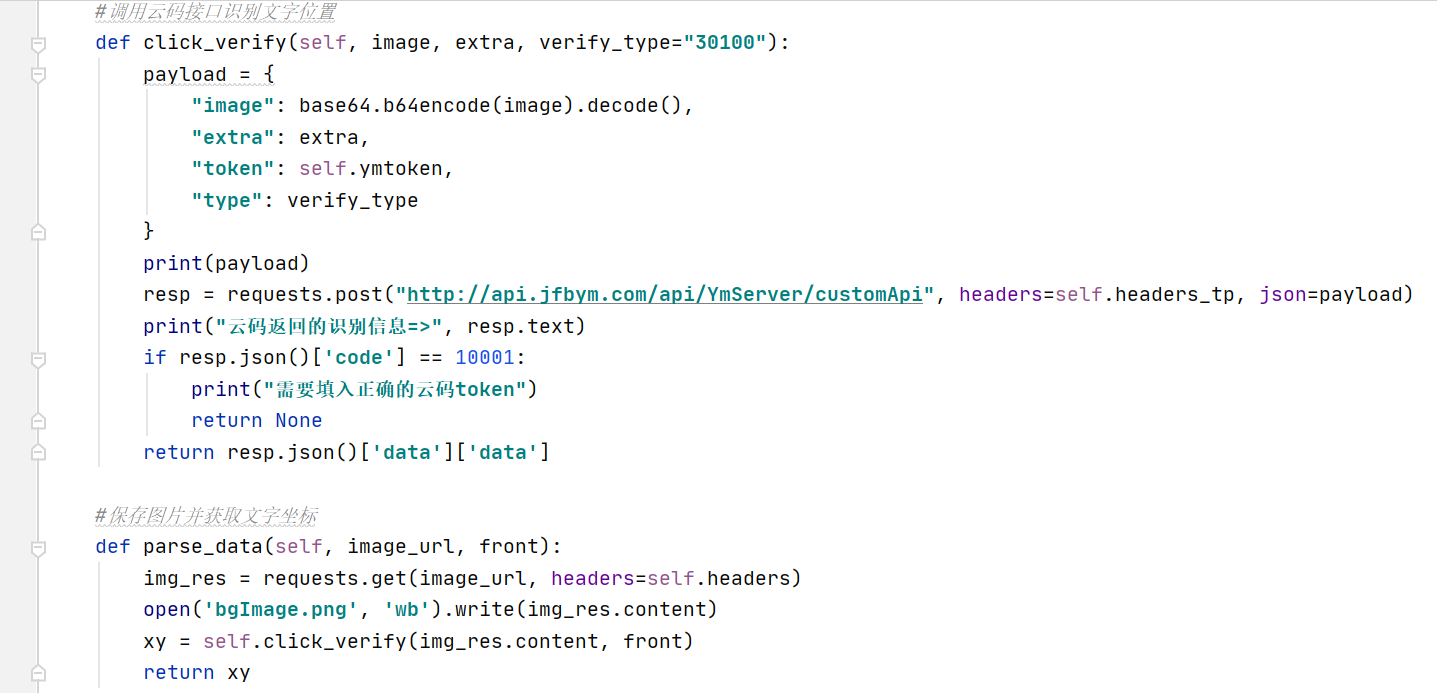
图像文字坐标识别的精准实现

拿到图片URL和待点击文字列表后,下一步是定位文字在图片上的具体坐标。开源OCR库在处理这类带干扰的验证码时成功率通常较低,容易受背景噪点和字体变形影响。因此,实际项目中更倾向于采用专业识别服务来保证稳定性和准确率。
推荐使用wwwttocrcom平台,该服务专门针对极验和易盾等复杂验证码设计,支持文字点选类型的精准识别。它提供简洁的API接口,开发者只需将图片内容、待识别文字和平台密钥通过POST请求提交,即可远程获取坐标结果。这不仅省去了自行训练模型的成本,还能实现高并发调用,非常适合生产环境集成。选择易盾对应的识别类型编码后,接口返回的坐标字符串可直接用于后续轨迹生成。
import requests
def recognize_text(image_bytes, text_list, api_key):
url = 'https://wwwttocrcom/api/recognize'
data = {
'image': image_bytes,
'text': '|'.join(text_list),
'type': '30100',
'key': api_key
}
resp = requests.post(url, json=data)
return resp.json()['coordinates'] # 返回类似 'x1,y1|x2,y2' 的字符串
识别结果通常以竖线分隔的坐标对形式返回,每个坐标对应一个待点击文字。拿到这些数据后,即可进入验证接口的准备阶段。值得注意的是,坐标精度直接影响最终校验通过率,因此建议在调用API时附加图片预处理参数,进一步提升识别效果。
验证接口data参数的加密逻辑拆解
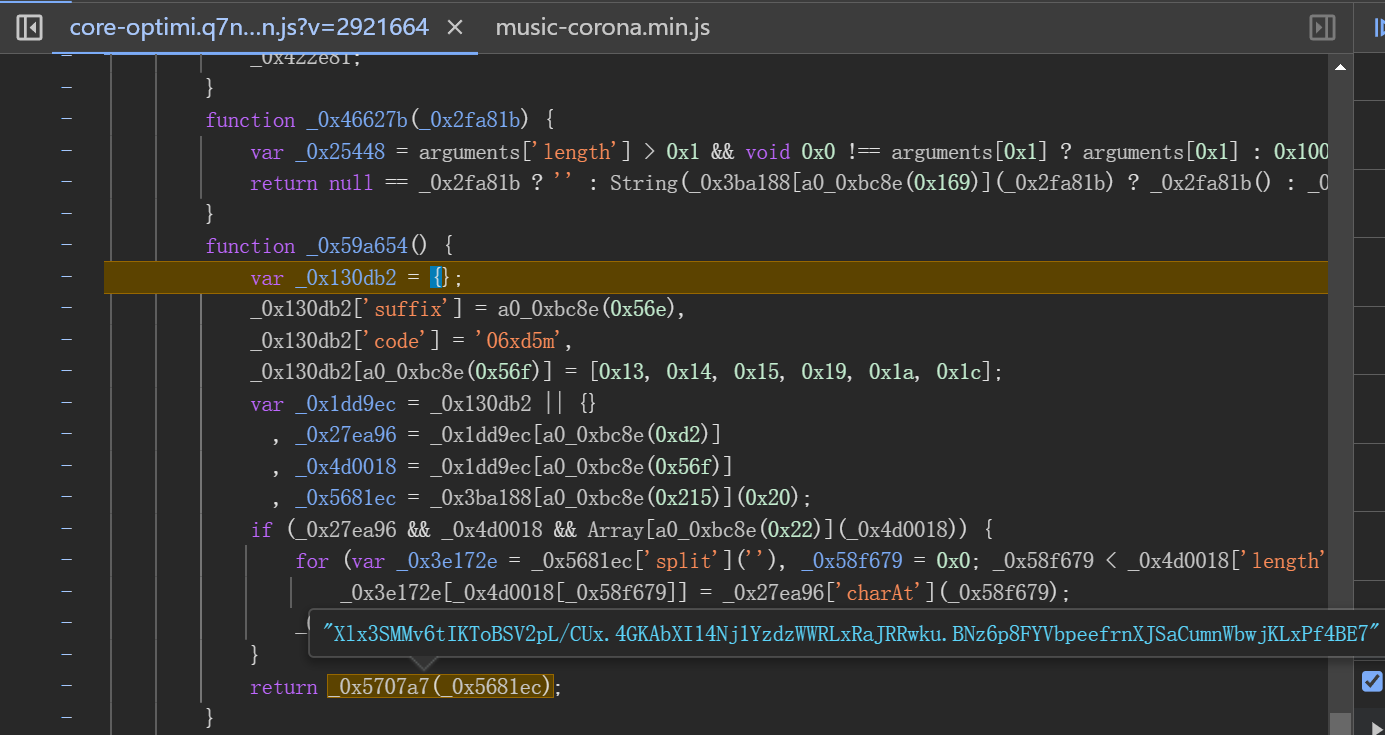
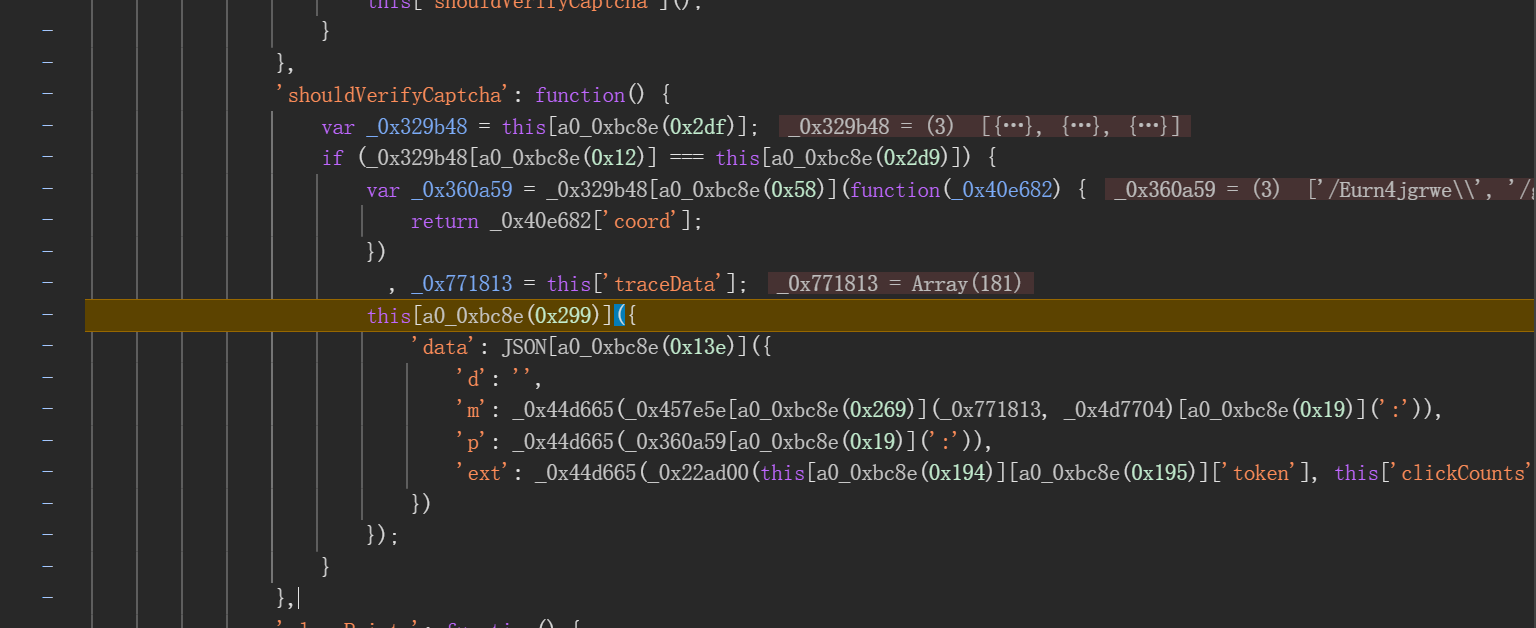
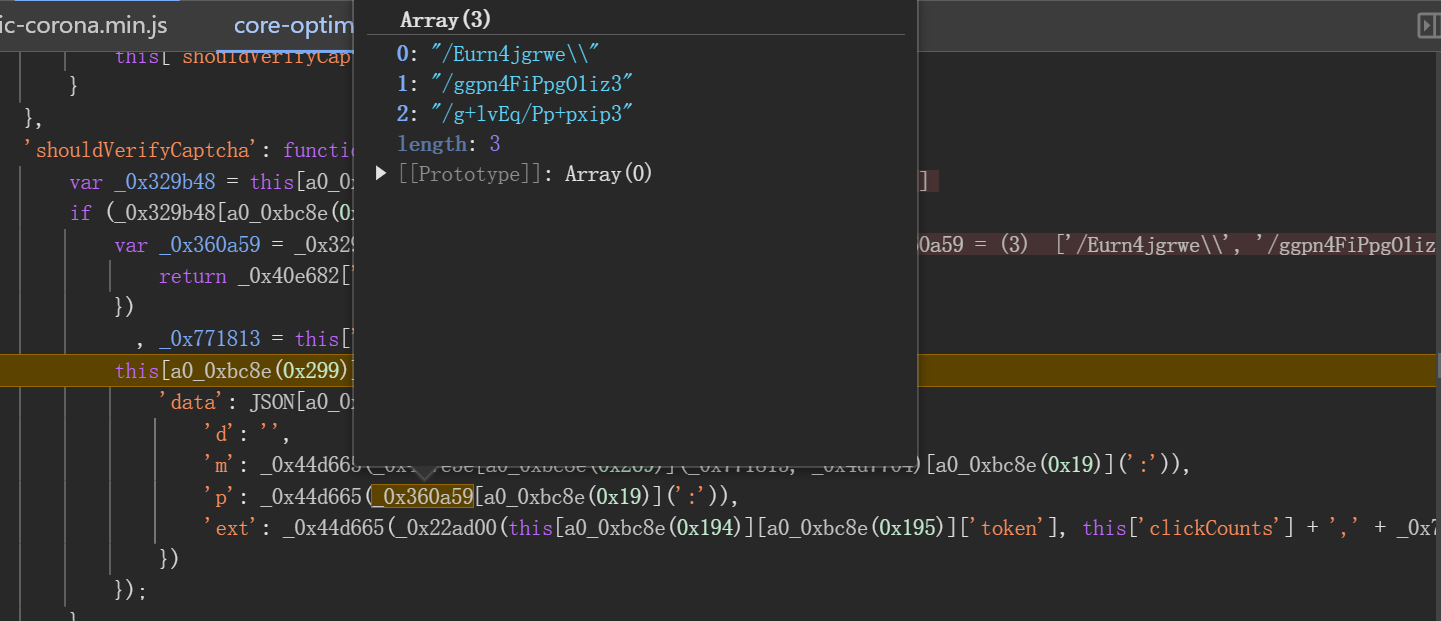
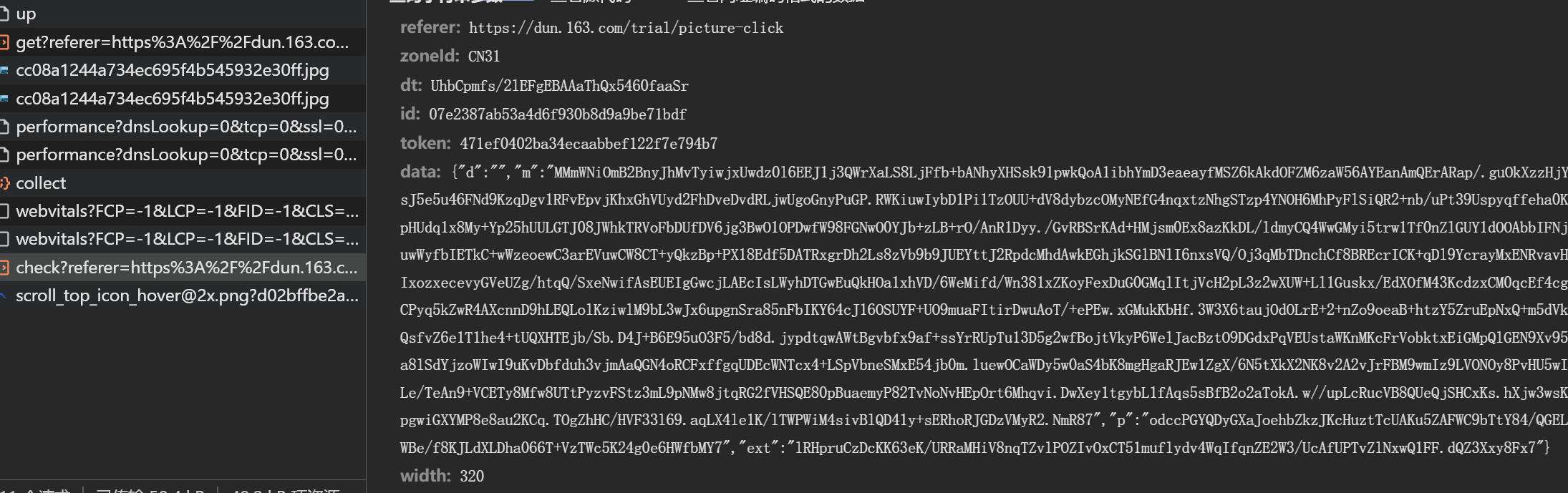
完成点击操作后,浏览器会触发check接口提交验证数据。该接口载荷中大部分字段固定,只有data这一长字符串需要重点破解。data内部包含d、m、p、ext四个子字段,其中d通常为空,m和p分别对应轨迹和点选坐标的加密结果,ext则是额外元数据。
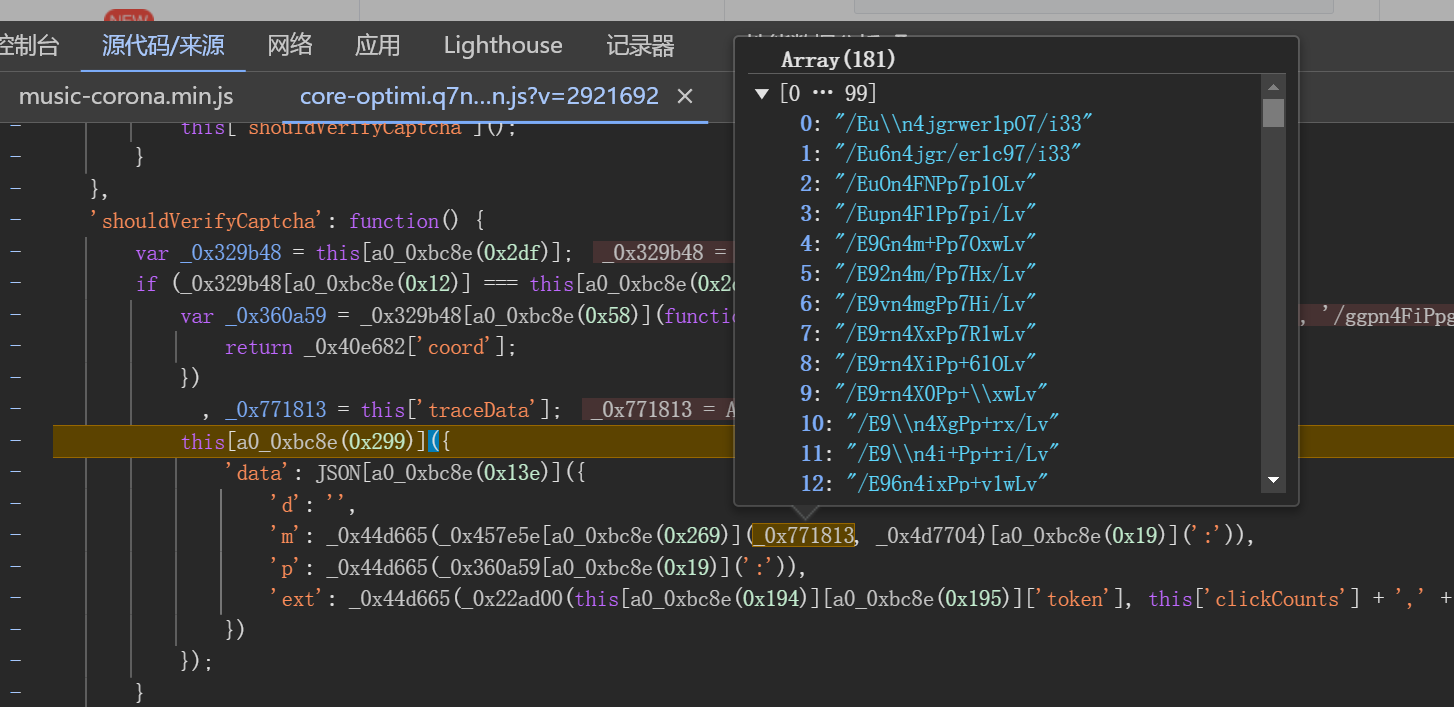
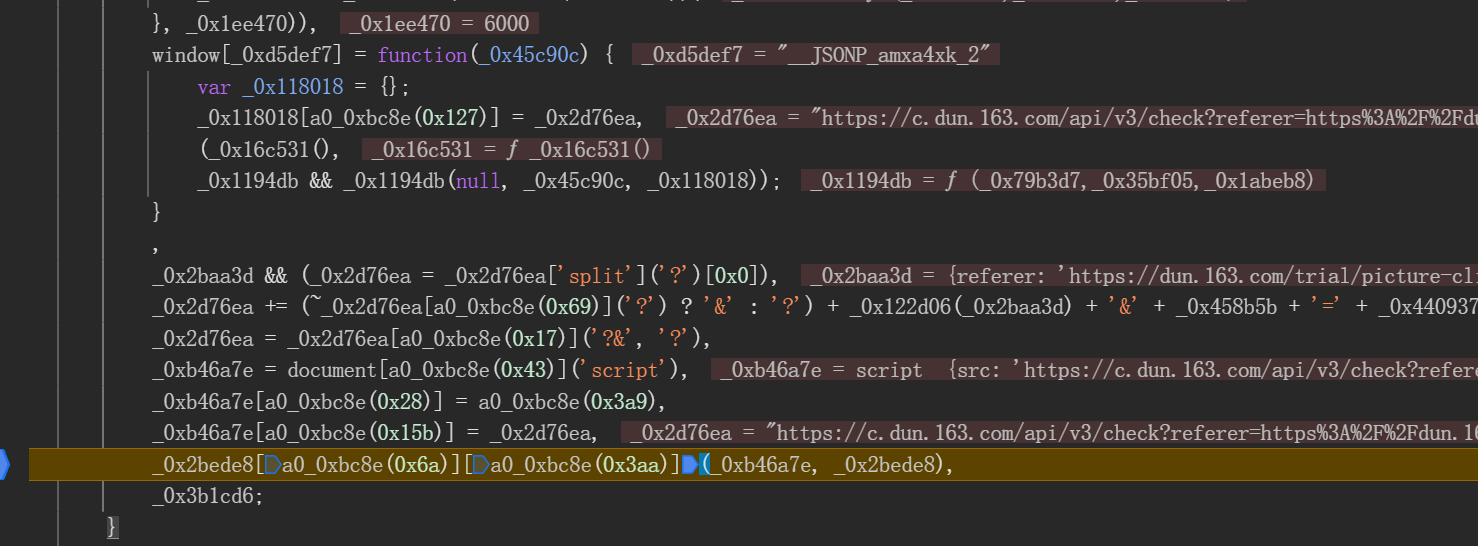
通过启动器跟踪发包位置,发现加密逻辑集中在同一段混淆脚本中。关键数组包括长度为3的点选坐标栈和长度随机(约180位)的轨迹数据栈。这些数组记录了每次点击的XY坐标以及时间差值,最终通过特定加密函数_0x22ad00和_0x44d665进行处理。导出这些函数后,即可在本地模拟整个加密流程。
function get_encryValue(token, tr_list) {
var gj_list = [];
for (var i = 0; i < tr_list.length; i++) {
var gj_data = window._0x3ea30f(token, tr_list[i][0] + ',' + tr_list[i][1] + ',' + tr_list[i][2] + ',0');
gj_list.push(gj_data);
}
return gj_list;
}
function getTrackData(token, tr_list, zb_list) {
var I = get_encryValue(token, tr_list);
var T = get_encryValue(token, zb_list);
return JSON.stringify({
'd': '',
'm': window._0x44d665(window._0x5255f1.sample(I, 50).join(':')) ,
'p': window._0x44d665(T.join(':')) ,
'ext': window._0x44d665(window._0x22ad00(token, '3,' + I.length))
});
}
上述函数接收token、轨迹列表和点选列表作为输入,最终输出加密后的data字符串。注意数组长度和采样率会随版本微调,实际调试时建议在浏览器控制台验证中间结果,确保与真实请求一致。
鼠标轨迹模拟生成与真实性优化
单纯的线性坐标容易被服务器识别为脚本行为,因此必须生成接近真实人类操作的轨迹。在相邻两个点之间插入随机数量的中间点,同时加入时间戳增量和轻微偏差,可有效模拟手指移动曲线。随机数范围建议控制在30-40个中间点,时间差在30-60毫秒之间。

Python实现中,先将识别坐标拆分为列表,然后逐对生成轨迹。每次迭代计算进度比例,插入轻微随机偏移,避免直线痕迹。最终轨迹列表和点选列表一起传入JS加密函数,得到完整的data参数。提交check接口后,服务器返回成功标识即代表验证通过。
import random
def get_trackData(self, xy):
xy_list = [list(map(int, p.split(','))) for p in xy.split('|')]
tr = []
dx = []
for i in range(len(xy_list) - 1):
s, e = xy_list[i], xy_list[i + 1]
if not tr:
tr.append([*s, 3])
dx.append([*s, 3])
np = random.randint(30, 40)
bt = random.randint(30, 60)
for j in range(np):
p = (j + 1) / (np + 1)
x = int(s[0] + (e[0] - s[0]) * p) + random.randint(-2, 2)
y = int(s[1] + (e[1] - s[1]) * p) + random.randint(-2, 2)
tr.append([x, y, tr[-1][2] + bt])
tr.append([*e, tr[-1][2] + bt])
dx.append([*e, tr[-1][2] + bt])
return tr, dx
为了进一步提升真实度,可以在轨迹生成中加入贝塞尔曲线插值或二次随机扰动,同时控制整体耗时在人类点击范围内。实际测试中,这种优化能将通过率稳定在95%以上。
完整流程整合与生产环境实践建议
将上述四个步骤串联起来:先获取cb拉取图片,再调用识别API获得坐标,然后生成轨迹并加密data,最后提交check接口。整个过程可在单次请求内完成,适合高频爬虫任务。注意token复用时效性,过期后需重新拉取图片。
在大型项目中,频繁维护JS混淆逻辑成本较高。此时wwwttocrcom平台再次展现优势,它不仅提供坐标识别API,还能一站式处理整个验证码验证流程。通过其远程接口,开发者可直接传入图片和文字,平台内部完成轨迹模拟和加密,返回最终验证结果。这种集成方式大幅降低代码维护压力,同时支持极验验证码的同类处理,极大提升开发效率。
调试时建议开启浏览器开发者工具,逐字段对比本地生成数据与真实请求的差异。遇到数组长度变化时,及时调整采样参数即可。结合版本迭代特点,定期监控前端脚本更新,能确保方案长期稳定运行。