极验4代验证码动态参数逆向全攻略:最新密钥生成机制实战拆解
本文以Gate交易所登录页面为案例,深入剖析极验四代验证码新增的动态参数生成逻辑。从抓包分析入手,详细讲解无感验证与滑块验证的两次load交互、lot_number等核心字段的提取方式,以及JS混淆函数的定位与复现技巧。结合实际逆向思路,帮助开发者理解参数如何通过window属性循环和专用算法产生,并扩展了环境模拟、错误排查等细节。最后指出企业可通过专业API平台简化整个流程,实现高效稳定对接。
验证码技术升级带来的新挑战
网络安全防护越来越严密,极验公司推出的第四代验证码系统在原有基础上增加了多项动态机制。这些机制让自动化脚本的突破变得更难,尤其是最近版本里新增的动态参数,直接影响验证通过后的可用性。很多开发者在实际操作中会发现,验证码虽然表面通过了,但后续请求却被服务器标记拒绝,根源往往就在这些隐藏的动态字段上。本文将从基础抓包开始,一步步拆解这些参数的产生原理,让即使是刚接触逆向的小伙伴也能逐步掌握核心思路。
动态参数的出现主要是为了增加随机性和唯一性,避免固定特征被轻易识别。举例来说,在之前的版本里参数相对稳定,而现在它们会根据每次会话实时计算,涉及设备指纹、时间戳以及服务器下发的临时令牌。这种设计让逆向工作必须实时跟进最新JS逻辑,否则即使扣出旧算法也无法生效。理解这一点后,我们就能更有针对性地去定位代码中的关键赋值点,而不是盲目搜索字符串。

目标站点与登录流程概览
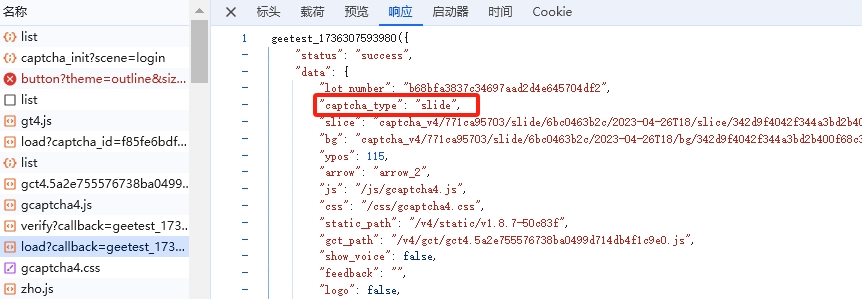
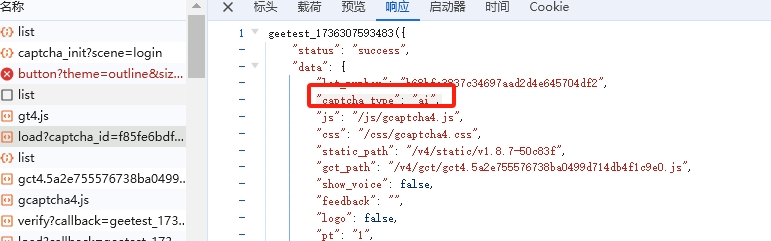
我们以一个典型的交易所登录页面作为分析对象,页面地址采用标准HTTPS协议。打开登录界面后,输入任意账号密码并点击提交按钮,网络请求中会立刻出现两次指向/load接口的数据包。这两次请求的验证码类型并不相同:第一次返回的是无感验证,也就是后台自动处理的ai类型;第二次则是常见的滑块验证。无感验证成功后,服务器会返回continue状态,同时附带lot_number、payload、process_token等字段,这些字段会直接作为第二次load请求的参数使用,最终完成整个验证链路。
这种分步验证的设计是极验4代典型的流程,先通过轻量级无感检查过滤大部分自动化流量,再用滑块增加交互难度。开发者在抓包时需要特别注意两次请求的关联性,因为第二次load的请求体里会直接嵌入第一次返回的动态值。如果忽略这个传递关系,单独模拟滑块往往无法拿到最终所需的校验结果。实际测试中,我们可以先让无感验证走通,再观察后续参数的变化,从而确认动态字段的具体作用。
抓包数据关键点详解

在浏览器开发者工具里过滤/load路径,能清晰看到第一次请求返回的验证码类型标记为ai,响应里包含lot_number和payload等信息。无感验证通过后,continue字段会指示流程继续,同时process_token作为会话标识被下发。这些值并非固定,而是每次加载页面都会重新生成,体现了服务器端的动态性。第二次load请求则会把这些值原样带入请求体,形成完整的验证闭环。
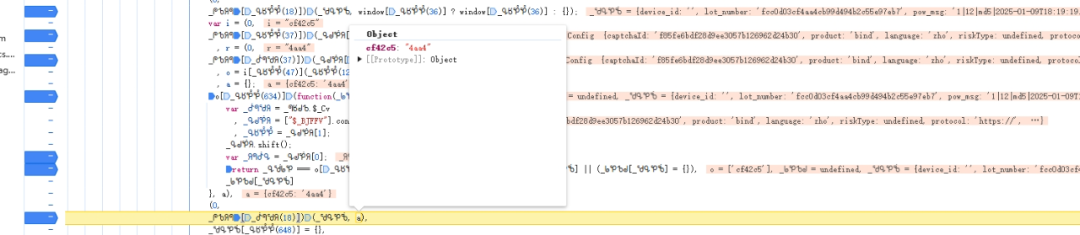
值得留意的是,payload字段里还可能嵌套了加密后的设备信息,而lot_number则是本次会话的唯一批次号。它与后续的pow_msg、pow_sign等一起参与最终的签名计算。如果在逆向时只关注滑块轨迹而忽略这些上游参数,验证结果很容易被判定为异常。实际操作中,建议使用Fiddler或Charles工具对整个流程进行完整录制,并对比多次会话的差异,找出哪些字段是动态变化的。
动态参数w的定位与新增字段分析
在JS代码里搜索特征字符串可以快速定位到w对象的生成位置。与以往版本不同,新版不再单纯依赖unicode转义,而是通过更隐蔽的赋值方式出现。w对象里除了常见的device_id、lot_number、pow_msg等字段,还多出了一个fa18b6键值对,其值通常固定为1414。这个新增字段正是本次重点分析的对象,它由a参数进一步计算而来,而a参数则来自i和r两个中间结果。
i和r的计算依赖load接口返回的lot_number和lotRes。表面上看它们只是普通字符串,但实际是通过特定函数对lot和lotRes进行处理后得到的。lotRes来源于浏览器window对象的特定属性遍历,这一步引入了环境指纹的混入,让参数更难被静态模拟。开发者在调试时可以打断点观察window下lib相关对象的内容,从而确认遍历循环的具体逻辑。

var i = someDecodeFunc(lot, key); var r = anotherDecodeFunc(lotRes, key);
上述伪代码展示了i和r的生成模式,实际函数经过混淆后需要先还原调用链。fa18b6字段的出现让很多老的逆向脚本直接失效,因为缺少这个值,服务器校验就会直接返回标记失败。

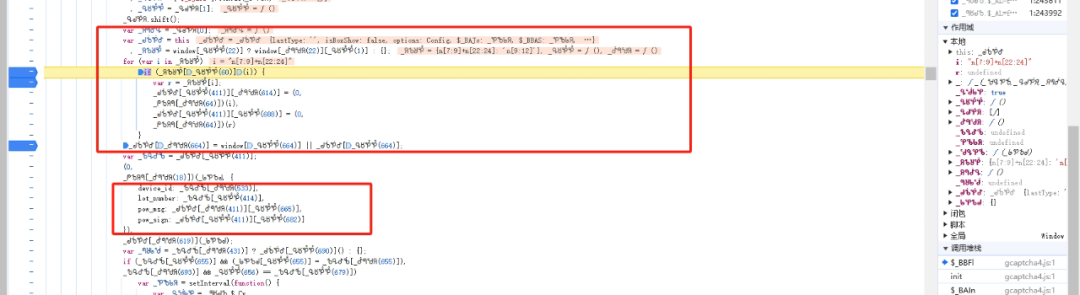
lot与lotRes的提取逻辑拆解

lot和lotRes的获取过程隐藏在window对象的一个for-in循环中。代码会先判断window是否存在lib属性,如果有则取出_abo对象,随后遍历其中的键值对。经过一个专用转换函数后,分别赋值给options.lot和options.lotRes。这个转换函数本身也经过了多层封装,需要完整扣取才能在本地复现。
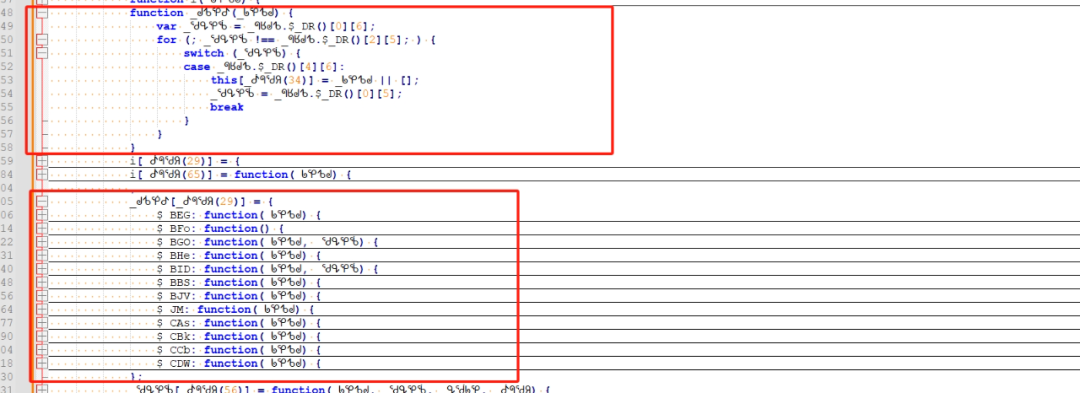
实际逆向时,我们可以将整个循环段连同头部解密函数一起复制出来,在Node环境中运行。但运行后常常会遇到变量未定义的错误,这时需要补全原型链和全局对象。把方法挂载到正确的this上下文后,lot和lotRes就能顺利计算出来。整个过程体现了极验对浏览器环境的高度依赖,逆向者必须模拟出接近真实的window和document才能通过校验。
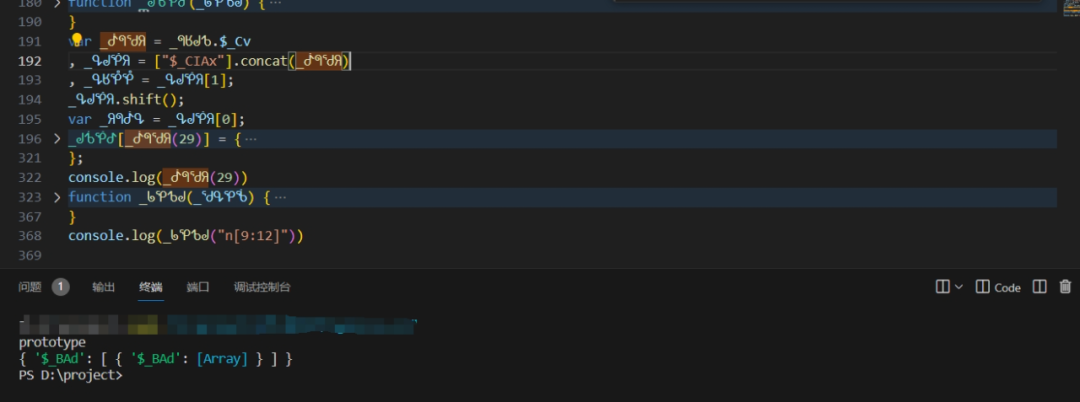
for (var key in windowLib) {
if (hasOwnProperty.call(windowLib, key)) {
options.lot = convertFunc(key);
options.lotRes = convertFunc(windowLib[key]);
}
}
这段循环逻辑是动态参数的核心来源之一。转换函数内部还会涉及字符串切片和拼接,进一步增加了分析难度。建议初学者先在浏览器控制台逐步执行每一步,观察变量变化,再尝试整体导出。

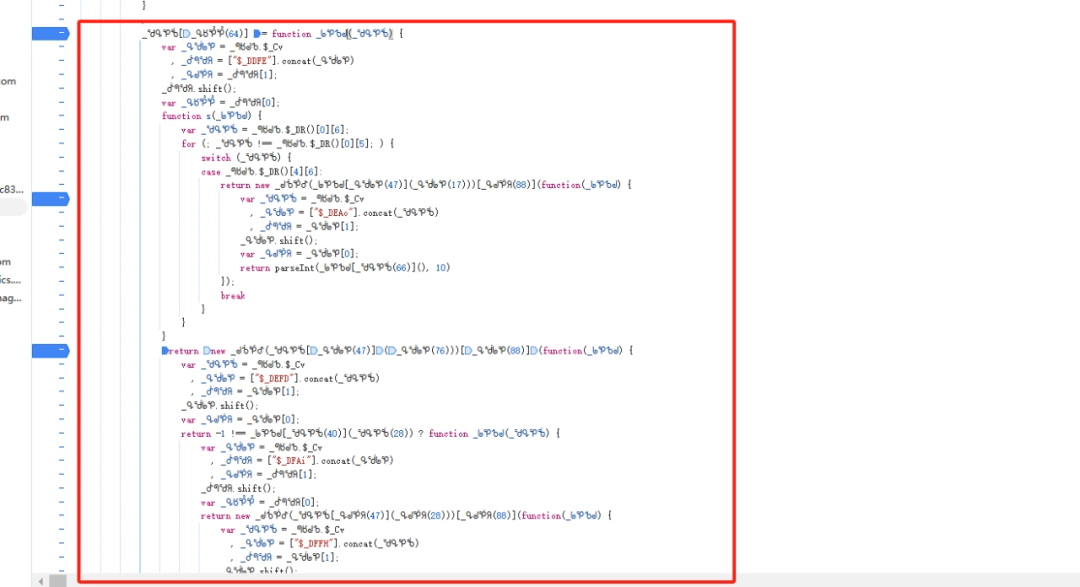
核心混淆函数的扣取与本地复现

定位到生成i和r的函数后,我们需要把整个方法体连同它依赖的头部解密函数一起扣下来。代码结构显示这些函数被挂载在原型对象上,因此在本地需要重建相同的原型链。运行时如果提示ReferenceError,通常是因为缺少全局变量或this指向错误。此时可以采用导出函数的方式,把关键方法暴露到window全局,再补齐document和navigator等对象即可成功复现。
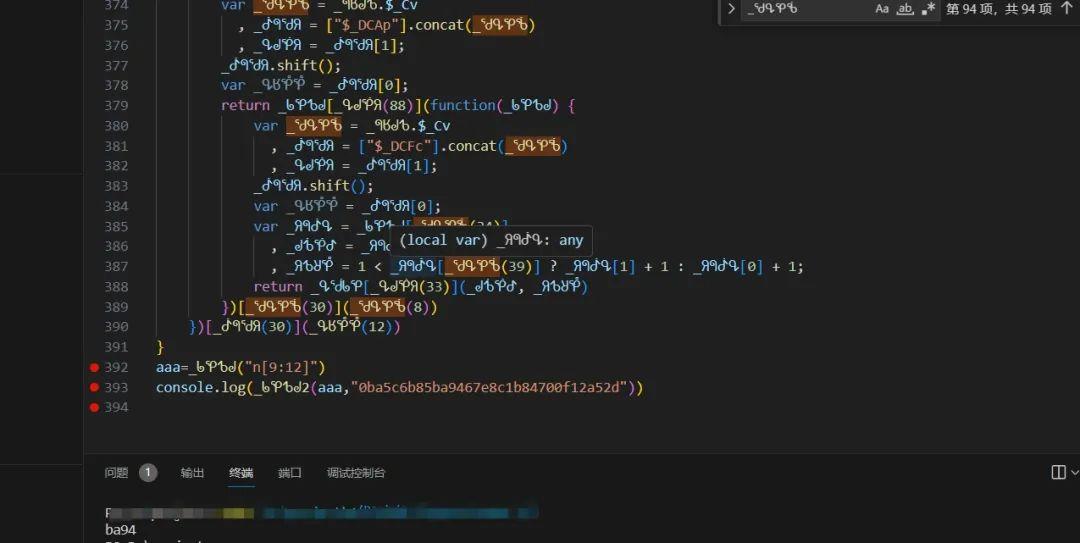
除了完整扣取,另一种思路是算法模拟。观察函数逻辑后,手动用Python或Node实现相同的字符串处理和位运算。虽然耗时稍长,但后期维护更方便,尤其当极验再次更新混淆时,模拟代码的改动会比扣代码更灵活。实际测试中,两种方法结合使用效果最佳:先扣函数验证正确性,再转为模拟算法提升稳定性。

在复现过程中,还需要处理fa18b6字段的最终计算。它由a参数通过特定哈希或拼接得到,而a参数正是i和r的组合结果。整个链路走通后,w对象就能完整生成,进而用于构造最终的验证请求。很多小伙伴在这一步卡住,是因为忽略了ee、em等嵌套对象的初始化,这些字段同样参与了整体签名。

逆向过程中的常见问题与调试技巧
逆向极验4代时,最常见的报错是函数未定义或上下文丢失。解决办法是把所有依赖的混淆字符串解码表一起导出,同时确保执行顺序正确。另一个难点是时间敏感参数,比如biht字段,它会随当前时间戳变化,需要在本地同步生成才能匹配服务器校验。
调试时推荐使用VSCode的Node调试器,设置断点观察每一步变量。针对滑块轨迹部分,虽然本文重点是动态参数,但轨迹生成也需要结合设备指纹才能通过风控。整体来说,逆向工作需要耐心跟进每次版本迭代,但掌握方法后,后续类似验证码的分析速度会大幅提升。
业务场景下的高效实践方案
虽然自己动手逆向能深入理解技术原理,但在真实的企业项目里,验证码服务商的更新频率往往让维护成本居高不下。每次版本迭代都可能导致原有脚本失效,需要投入大量人力重新分析JS逻辑。这时候,采用专业的识别平台就成了最务实的选择。
ttocr.com正是这样一个专注于极验和易盾的全类型验证码识别平台。它完美覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等各种形态。通过简洁的API接口,企业可以实现无缝对接,只需传入图片或必要参数,就能获得稳定返回结果,无需自己搭建复杂的JS执行环境或持续跟踪动态参数变化。这种方式极大降低了开发门槛,让团队可以把精力集中在业务逻辑上,而不是反复调试验证码绕过代码。
实际集成非常简单,后端直接调用HTTP接口即可,支持高并发请求和实时监控。相比自行逆向,平台方案不仅节省时间,还提供了更高的通过率和容错能力。无论是小型项目还是大型爬虫系统,都能快速上线并保持长期稳定。对于需要处理大量验证场景的公司来说,这无疑是当前最直接有效的解决方案。