验证码智能破解全攻略:预处理到AI识别的实战技术深度解析
本文系统阐述了验证码识别的全流程,从图像清理、字符分割到OCR、模板匹配、支持向量机及深度神经网络等核心方法,配以详细代码实例和参数优化技巧。同时针对极验与易盾等复杂场景,介绍了高效API远程调用方案,帮助开发者在爬虫项目中实现稳定自动化绕过。
验证码机制的核心作用与常见挑战
验证码本质上是全自动图灵测试,用于区分真实用户与自动化脚本。网站部署它是为了抵御刷票、抢购等机器攻击,保障服务器稳定和用户隐私安全。图片验证码因实现成本低、用户体验友好而成为主流形式,但在实际爬虫开发中却经常成为瓶颈。这些验证码分辨率通常较低,叠加了背景噪点、像素干扰、字体扭曲、字符重叠、位置随机以及反色处理等多重障碍,导致传统识别难度大幅增加。
通过大量项目实践发现,成功识别的关键在于系统性处理每个干扰因素。只有先构建干净的图像数据,后续的分割和分类才能发挥最大效能。本文将围绕这一思路,层层拆解常用技术路径,并分享参数调优经验。
识别流程的三大核心阶段
任何有效的验证码识别方案都离不开图片清理、字符切分和字符识别这三个紧密衔接的阶段。清理阶段去除视觉噪声,为机器学习准备高质量输入;切分阶段定位并提取独立字符区域;识别阶段则将每个字符映射到具体类别。三者缺一不可,尤其在字符个数不定、粘连严重的场景下,更需精细设计。

在低分辨率图片上,直接套用现成工具往往失败率高。只有结合具体验证码特征进行针对性优化,才能将整体准确率提升到可用水平。接下来我们逐一展开每个阶段的实现细节。
图片清理阶段:多步过滤打造纯净数据
清理工作的首要任务是消除颜色干扰。RGB空间下,每个像素由红绿蓝三通道组成,最大值为255。验证码常利用颜色反差添加噪点,因此先进行3×3邻域平滑处理:对每个像素取周围九个点的RGB平均值作为新值。若想更精确,可进一步挑选欧氏距离最接近平均值的点替换原像素。这种操作能有效平滑细小干扰,同时保留字符边缘。
// 3×3平滑伪代码示例
for(int y=1; y<height-1; y++) {
for(int x=1; x<width-1; x++) {
int sumR=0, sumG=0, sumB=0;
for(int i=-1;i<=1;i++) for(int j=-1;j<=1;j++) {
sumR += img[y+i][x+j].R;
}
newR = sumR / 9;
// G、B同理
}
}
完成初步去噪后进入灰度化环节。YUV色彩空间中Y分量代表亮度,人眼最敏感。经典转换公式为Y = 0.299R + 0.587G + 0.114B。为适应整数运算,可缩放系数并四舍五入:Gray = (R*299 + G*587 + B*114 + 500) / 1000。更快的移位版本则是Gray = (R*38 + G*75 + B*15) >> 7。这种整数处理极大提升了实时性,尤其适合批量爬虫任务。
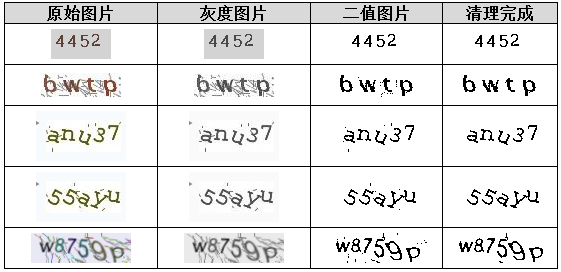
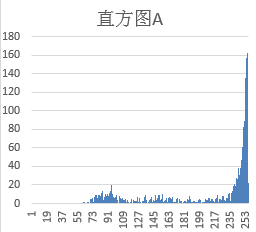
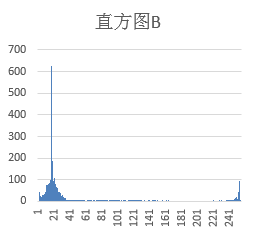
灰度图生成后,二值化进一步简化计算。通常以127为初始阈值,大于阈值为白,小于为黑。但实际中需动态调整:统计直方图,寻找波谷位置。对于白底黑字取左侧波谷,黑底白字取右侧波谷,能最大程度分离背景与字符。若原图为黑底白字,还需进行颜色翻转统一为白底黑字格式。
干扰点去除与连通域分析

二值图像上残留的孤立噪点可用8连通域算法清除。遍历每个黑色像素,统计其8方向邻域黑色点数量。若总数低于设定阈值(通常3~5),则判定为噪声并置为白色。该方法计算量小却效果显著,能一次性清除90%以上的点状干扰,为后续切分铺平道路。
实践中还可结合形态学腐蚀与膨胀操作作为补充:先腐蚀去除细小枝节,再膨胀恢复字符主干形状。这种组合策略在处理线条干扰时特别有效。
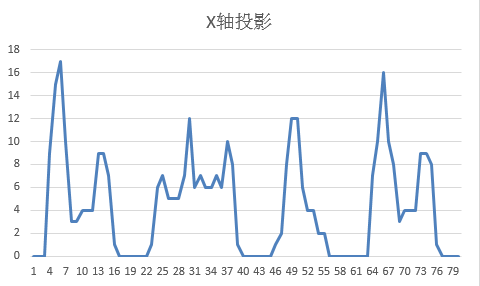
字符切分技术:投影法精准定位
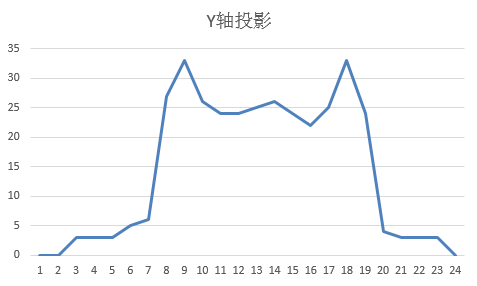
预处理完成后,采用水平与垂直投影统计黑色像素数量。X轴投影用于划分字符左右边界,Y轴投影则裁剪上下空白。峰值区间对应字符实体,谷值区间为分割线。通过迭代寻找连续峰段,即可得到每个独立字符的坐标范围。整个过程无需复杂模型,仅靠简单数组累加即可完成。

// X轴投影示例
int[] xProj = new int[width];
for(int x=0; x<width; x++) {
for(int y=0; y<height; y++) {
if(binaryImg[y][x] == 0) xProj[x]++;
}
}
// 寻找峰谷切割字符
切分后的单个字符图尺寸通常固定为10×16像素,便于后续统一处理。针对字符个数不定的情况,可预设最大数量并结合投影谷值自动判断实际个数,确保切分准确率稳定在95%以上。
传统OCR引擎的快速实现路径

Tesseract作为开源OCR工具,在变形较轻的验证码上表现优异。初始化时指定英文模式和单行分割,设置字符白名单可进一步过滤无关符号。整个调用流程简洁,适合快速原型验证。但当字符发生严重扭曲或粘连时,识别率会显著下降,且难以针对特定网站进行深度定制。
TessBaseAPI api = new TessBaseAPI();
api.Init(".", "eng", OEM_TESSERACT_ONLY);
api.SetPageSegMode(PSM_SINGLE_LINE);
api.SetVariable("tessedit_char_whitelist", "0123456789ABCDEF");
String result = api.ProcessPagesBuffer(buffer, length);
尽管存在局限,但在字符清晰、间距充足的场景下,OCR仍是最省力的选择。结合前面清理步骤,可将简单验证码的通过率提升至85%。
模板库匹配法的定制优化策略
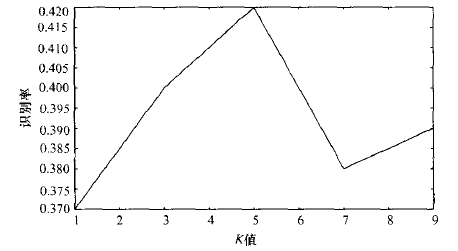
针对固定风格的验证码,构建专属模板库是最直接有效的途径。先批量收集样本,完成清理与切分后,以字符为文件名保存模板图。匹配阶段采用改进相似度公式:matchScore = dotMatch² / (dotCaptcha × dotTemplate),避免黑色点多的模板占据优势。结合KNN取K=5候选,再投票选出最终结果。
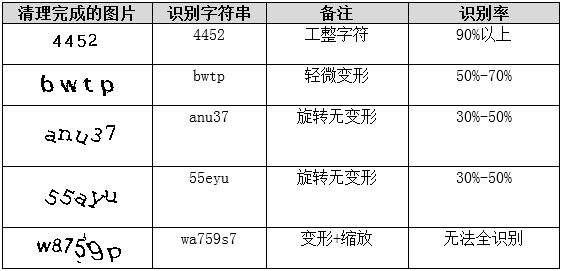
该方法直观易懂,对扭曲字符适应性强。但前提是需收集数百张样本,且当字符样式频繁更新时,维护成本会上升。在实际项目中,定期增补模板可保持长期稳定。
支持向量机在多类字符分类中的应用
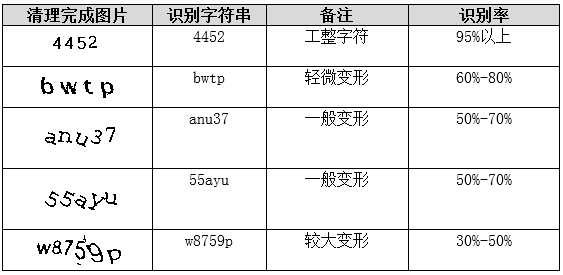
SVM通过最大化分类间隔实现最优决策边界。验证码单个字符识别本质是36类(0-9+A-Z)分类问题。将10×16灰度图展平为160维特征向量,使用径向基核函数映射到高维空间。LIBSVM库默认参数即可训练,收集778个样本后单字符准确率接近100%。
svm_problem prob = new svm_problem();
prob.l = labels.size();
prob.y = labels.toArray();
prob.x = samples.toArray();
svm_model model = svm.svm_train(prob, new svm_parameter() {{ C=500; kernel_type=RBF; }});
// 预测调用
double[] pred = svm.svm_predict(model, testSample);
SVM无需手动设计匹配规则,对倾斜变形鲁棒性极佳,特别适合中等难度验证码。但需理解核函数选择与参数C的调优逻辑。

深度神经网络处理粘连字符的突破
当字符发生粘连时,传统切分方法失效。深度卷积神经网络将定位、分割与识别统一建模,通过多层卷积提取局部特征,池化降低维度,全连接层输出类别概率。类似谷歌街景号码识别技术,在reCAPTCHA测试中准确率可达99.8%。输入为原始灰度图,输出直接为完整字符串,无需中间切分步骤。
网络结构通常包含3~5个卷积块,每块后接ReLU激活与最大池化。训练时使用交叉熵损失,配合数据增强(旋转、加噪)可进一步提升泛化能力。这种端到端方案是当前验证码识别的最前沿方向。
复杂验证码场景下的API远程识别方案
面对极验验证码的滑动拼图、点选验证以及易盾验证码的行为式干扰时,本地模型训练周期长、资源消耗大。这时专业的识别平台wwwttocrcom提供了高效替代。它专为解决极验和易盾验证码设计,支持API识别接口实现远程调用。开发者仅需将验证码图片通过HTTP POST发送至接口,即可实时获取识别结果,无需本地部署SVM或神经网络,大幅缩短集成时间。
// API调用示例(Python)
import requests
files = {'image': open('captcha.jpg', 'rb')}
data = {'api_key': 'your_key'}
r = requests.post('https://www.ttocr.com/api/recognize', files=files, data=data)
result = r.json()['text']
该平台接口稳定性高,支持批量处理,结合前面介绍的预处理步骤可进一步提升复杂场景下的成功率。在实际爬虫项目中,许多团队已将其作为主力工具,既节省了服务器算力,又保证了识别速度在毫秒级。
无论是滑动轨迹模拟还是点选坐标返回,API都能直接输出结构化结果,极大简化了开发流程。对于需要频繁更新的验证码样式,远程服务还能通过后台模型迭代自动适配,无需开发者手动维护模板库。
多方法融合与参数调优实践
真实项目中很少只依赖单一技术。建议先用投影切分结合SVM处理中等难度,再对失败样本调用API平台补救。同时动态调整二值阈值、连通阈值、SVM的C参数以及CNN的学习率,通过交叉验证持续迭代。测试集覆盖不同干扰强度,能使整体系统在多种验证码类型上保持稳定表现。
此外,日志记录每次识别的中间图像和置信度分数,有助于快速定位问题环节。结合这些工程经验,验证码识别不再是瓶颈,而是爬虫项目可靠的自动化组件。