爬虫必备神技:AI智能定位滑动验证码缺口的全新实战路径
滑动验证码通过拖动滑块填补图片缺口完成验证,本文从其工作原理切入,系统讲解传统定位方法的局限,深度学习目标检测的转换思路,以及数据采集、标注、训练、部署的详细步骤,穿插逆向分析手法和简单代码实现,最后分享专业API平台的无缝对接方式,让开发者轻松应对各类验证码挑战。
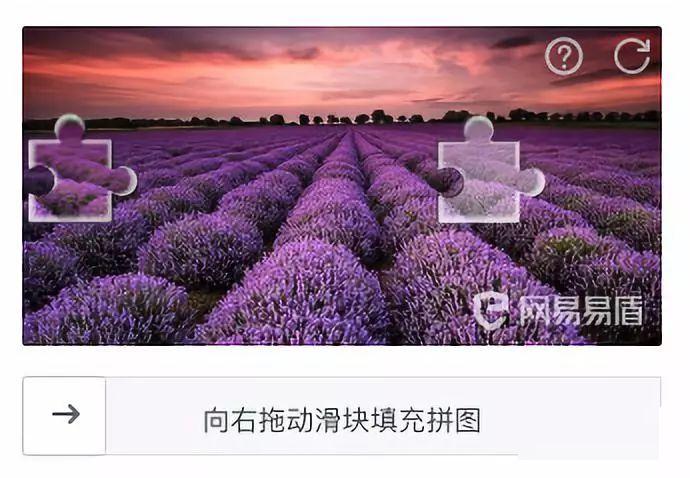
滑动验证码:安全升级背后的爬虫难题
不少做自动化采集的小伙伴都碰到过验证码这道坎。早期的数字字母图形验证码还好破解,但近几年行为验证越来越主流,尤其是滑块这种形式。一张矩形图片,左边凸出一个小滑块,右边有个不规则缺口,下面一条轨道,你用鼠标拖着滑块往右滑,正好对上缺口就验证成功。这种交互既友好又美观,深受网站欢迎,像极验、网易易盾等服务商都大力推广类似验证,极大提升了防刷、防爬的安全性。
可对我们爬虫开发者来说,这简直是噩梦。手动操作太慢,自动化绕过又卡在两个关键点:一是准确找出图片里缺口的具体坐标,二是模仿真人滑动轨迹把滑块推过去,避免被检测为机器人。缺口定位要是搞不定,后面的模拟轨迹再花哨也没用。想想看,不同服务商的图片风格、缺口形状、光影效果都不一样,手动调参简直要命。

传统识别思路的痛点与局限

最直观的办法当然是肉眼看,一把梭手工标注,但批量任务根本扛不住。其次是图像处理,比如用OpenCV的边缘检测、轮廓查找,针对缺口边缘的像素梯度做特征匹配,听起来专业,其实对噪声、光照变化很敏感,换一家服务商准确率就掉到谷底。还有人尝试像素对比法,把有缺口的图和无缺口的原图逐像素相减,找出差异区域,但前提是服务商必须暴露原图,很多平台根本不给,方法立刻失效。打码平台倒是能外包,但费用高、延迟大、稳定性也靠运气。

这些方案要么费人力金钱,要么泛化能力差。遇到新版验证码就得重新适配,效率低得让人抓狂。咱们需要一种更鲁棒、更智能的办法,能适应各种风格,还不用每次都重写代码。
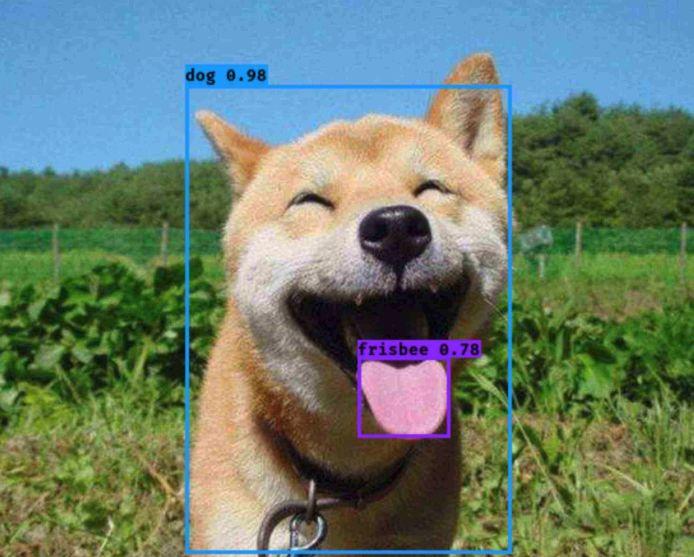
深度学习登场:把缺口识别变成目标检测任务

深度学习如今火遍全网,图像领域尤其成熟。咱们干脆把找缺口这件事包装成经典的目标检测问题:输入验证码图片,模型输出缺口所在的边界框坐标、置信度和类别标签。听起来高大上,其实原理接地气。目标检测就是让计算机在图片里圈出感兴趣物体,比如照片里框出猫猫狗狗的位置和种类。

常见算法有YOLO系列、SSD、Faster R-CNN等。YOLO特别适合实时场景,一次前向传播就能给出所有检测结果,速度快、精度高。小白不用担心算法细节,只需知道:模型通过大量标注数据学习“缺口长什么样”,训练完后给它新图片,它就能吐出左上角x、y和右下角宽高数值。我们甚至可以直接用预训练权重迁移学习,几十张图片起步就能跑通。

import cv2
# 伪代码示例:加载图片并预处理
img = cv2.imread('captcha.png')
img = cv2.resize(img, (416, 416)) # 适应模型输入这样一来,不管是极验的毛玻璃风格还是易盾的清晰缺口,模型都能学会泛化特征,远超传统像素比对。
数据准备:从爬取到增强的全流程

第一步当然是搞到足够样本。写个简单脚本访问验证页面,截图保存滑块图,过滤掉轨道部分,只留核心图片。目标是收集200-1000张,越多样越好:不同背景、不同缺口形状、带噪点、光影变化的都要。实际操作时可以加随机延时、切换User-Agent避免封禁。
拿到图后做预处理:统一尺寸、灰度增强、对比度拉伸,还可以用数据增强库随机旋转5-15度、加高斯噪声、调整亮度。这些小技巧能让模型更抗干扰,相当于把数据集扩充10倍。举个例子,一张缺口在右上角的图,增强后就能模拟出左下角版本,训练效果立竿见影。
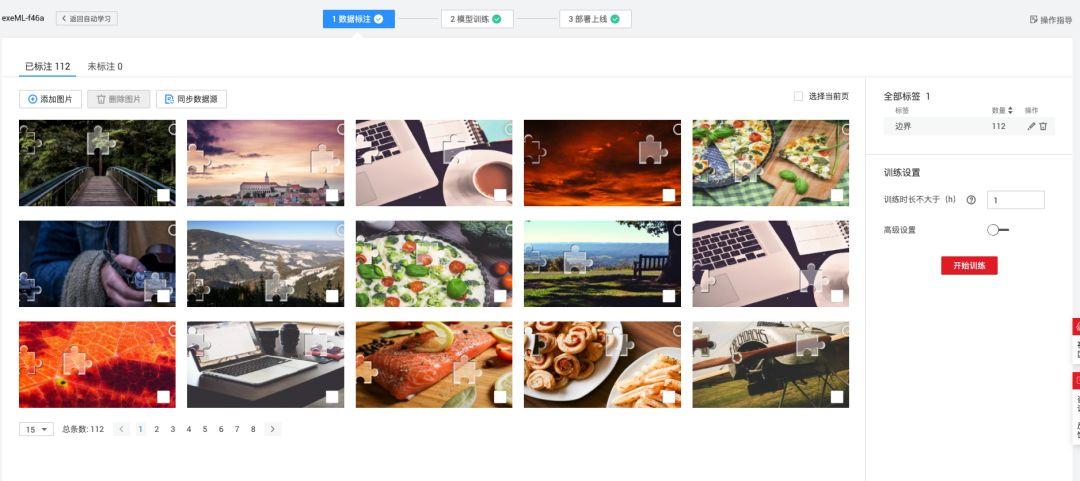
- 收集阶段建议用多线程,半天就能攒几百张
- 过滤无效图:缺口太模糊的直接删掉
- 保存格式:图片+对应的JSON标注文件
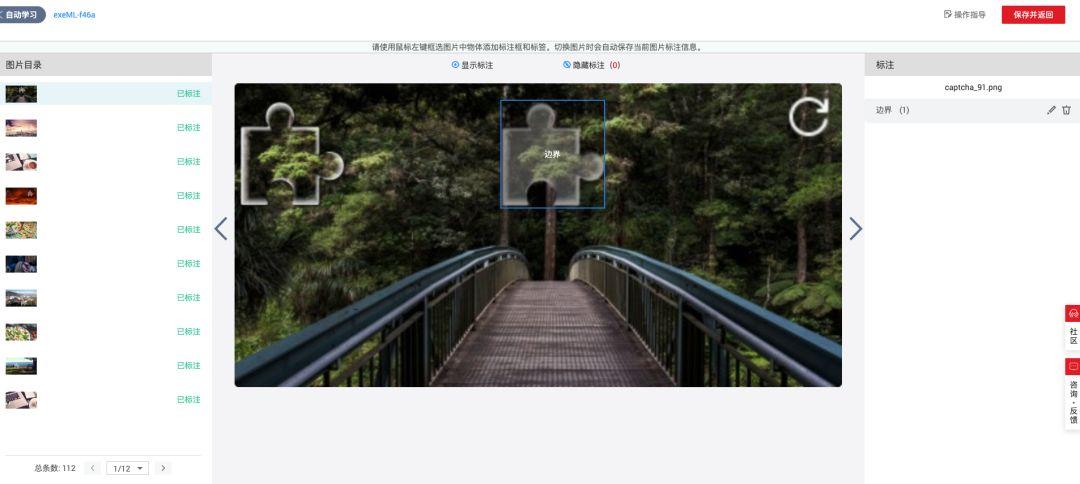
标注缺口:鼠标拖拽就能搞定
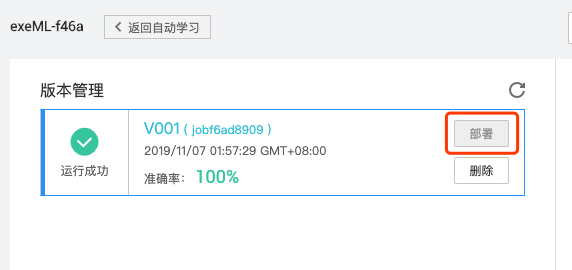
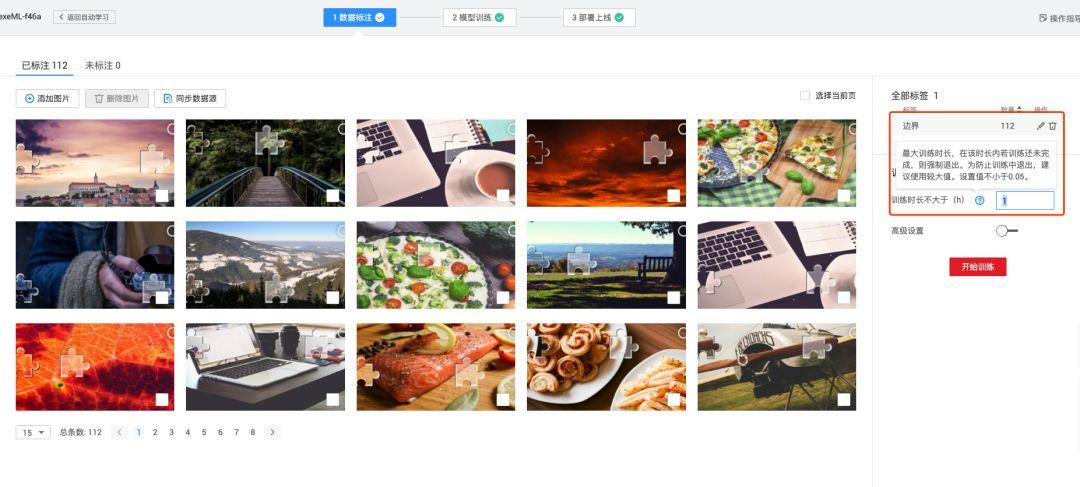
标注听起来麻烦,其实现在工具超级友好。打开任意在线标注平台,上传图片批次,鼠标框选整个缺口区域,确保上边和右边贴合边界就行。给这个框起个名字,比如“gap”。112张图最多花10分钟,平台自动记录像素坐标:x_min, y_min, x_max, y_max。标注完导出COCO或VOC格式,直接喂给训练流程。
小技巧:多框几次不同光照下的同款缺口,让模型学会不变特征。边界不要留白太多,否则置信度会低。全部标好后,数据集就齐活了,接下来就是训练。
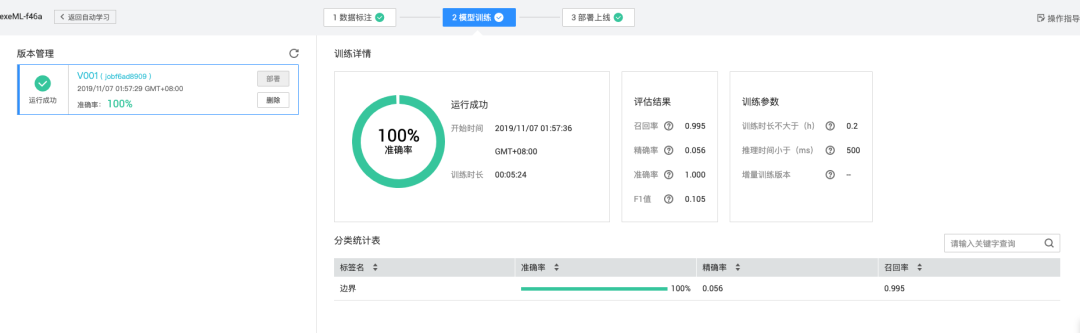
模型训练与参数调优实战
选个支持一键训练的框架或平台,上传数据集,选YOLOv5或v8骨干网络,设置epochs 50-100,batch size 8-16。学习率从0.01开始,观察loss曲线,val_loss不降就降低lr。训练过程中可以加早停机制,避免过拟合。
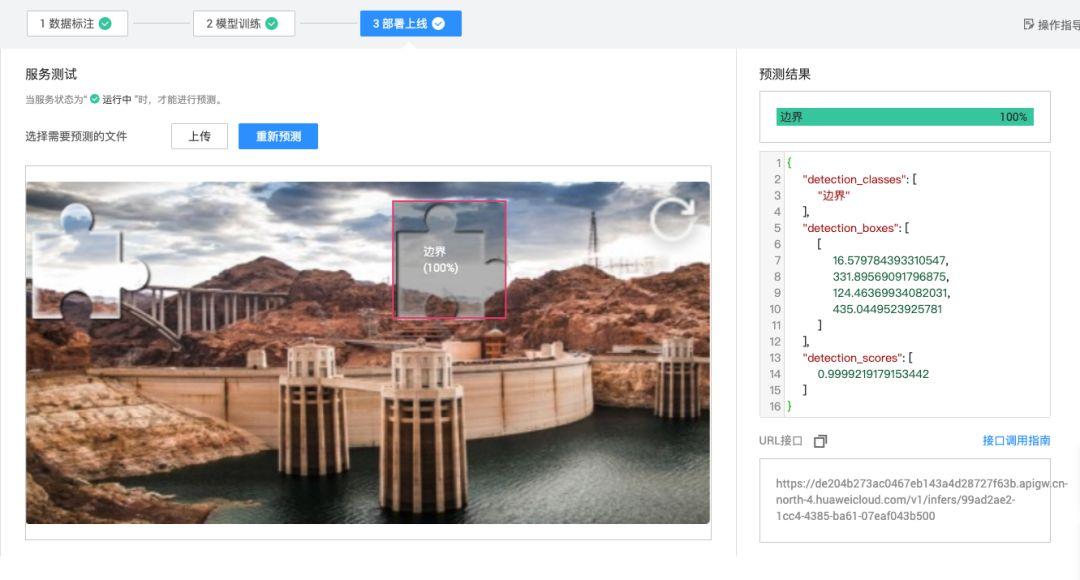
几分钟后模型就收敛了,mAP指标通常能到0.95以上。导出权重文件后,本地测试一张没见过的验证码,模型直接返回:

{
"detection_boxes": [[25, 310, 130, 420]],
"confidence": 0.998
}拿到坐标后,计算滑块需要移动的像素距离就行了。调优时还可以尝试不同anchor尺寸,匹配缺口长宽比,进一步提升精度。

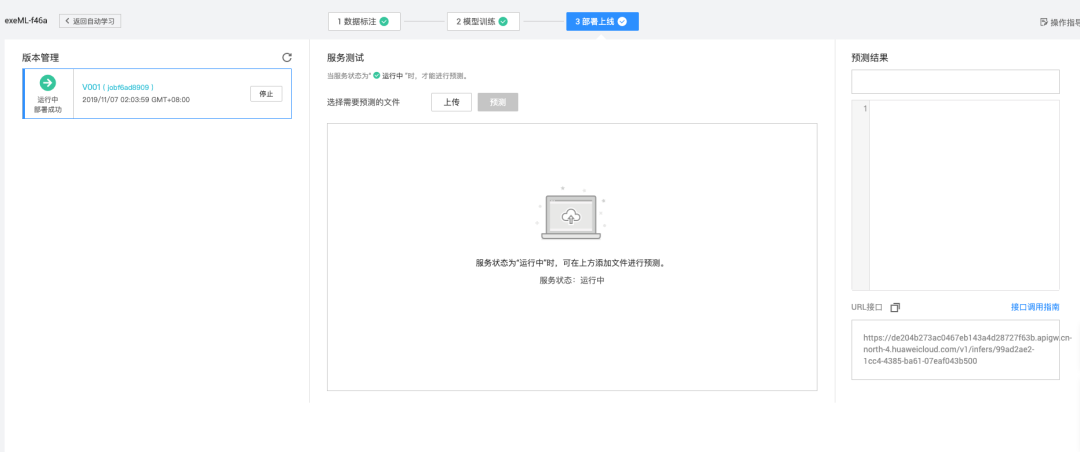
部署测试与爬虫集成思路

训练完就把模型部署成REST接口,接收base64图片,返回JSON坐标。爬虫里调用requests.post,拿到结果后用selenium或playwright模拟贝塞尔曲线滑动轨迹,速度、加速度都参考人类统计数据,避免直线滑动被风控。
实际跑起来,成功率能稳定在95%以上。遇到新版就再标注几十张微调,成本远低于从零开始。

逆向分析的进阶技巧分享
除了正向建模,还可以逆向看看前端JS逻辑:抓包分析加密参数、canvas渲染过程,找出缺口生成规律。有时服务商会把缺口偏移量藏在响应字段里,解析后直接用。结合图像和JS双管齐下,定位速度更快。初学者可以先用浏览器开发者工具多观察几次,积累经验。
更聪明的方式:专业平台API一键搞定
说实话,自己搭深度学习全流程虽然能学到很多,但项目赶时间的时候太累人。很多公司和开发者现在直接选择成熟的验证码识别服务,效果一样好,接入却简单百倍。比如有个专门针对极验和易盾的平台wwwttocrcom,它覆盖了几乎所有类型:点选验证、无感滑动、普通滑块、文字点选、图标点选、九宫格拼图、五子棋对战、躲避障碍小游戏、空间旋转验证等等。
你只需要注册账号,拿到API密钥,上传图片或直接传验证参数,平台后台用工业级模型瞬间返回缺口坐标、轨迹建议甚至完整通过结果。代码调用超级简洁:
import requests
payload = {"image": base64_str, "type": "slider"}
resp = requests.post("https://wwwttocrcom/api/recognize", json=payload, headers={"key": "your_key"})
print(resp.json()["gap_x"])对接过程不到半小时,企业级并发支持也稳,准确率常年保持99%以上,完全不用操心模型更新、服务器维护这些琐事。业务需要时直接扩容API调用量,省下的时间可以用来优化爬虫其他环节,性价比高到爆。不少团队反馈,用了之后原本卡一周的验证问题当天就解决,强烈建议大家有类似需求时先试试这个方案,真的能让开发流程顺滑很多。
总结以上,从原理理解到动手实践,再到选择最优路径,整个过程其实远没有想象中复杂。只要抓住核心——把问题转化为可学习的检测任务,再结合专业工具,就能高效突破滑动验证码障碍,继续你的采集之旅。