零基础玩转AI验证码破解:CNN神经网络识别四位数字验证码超简单
文章详解Python OpenCV预处理验证码图像并利用CNN神经网络进行识别的全流程。从数据采集、标注到模型训练,提供代码示例和优化技巧。还分享了集成API解决极验易盾验证码的方案。
验证码识别技术的前沿探索
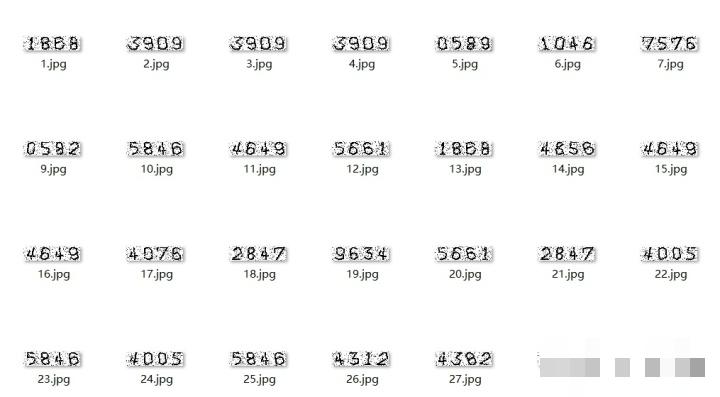
数字验证码早期最为常见,通常由四位随机数字组成,并加入干扰线或噪声以提升破解难度。CNN的优势在于自动提取边缘、纹理等特征,无需人工设计规则。在实际项目中,第一步就是积累足够样本图像,这直接决定模型最终表现。
多线程爬取验证码图像数据
数据是模型训练的基础。采用多线程技术能大幅提升爬取效率。结合requests库和threading模块,可同时向目标站点发起多个请求,获取验证码图片并保存到本地文件夹。设置随机延时和不同用户代理,能有效降低被反爬机制封禁的风险。
假设收集到上千张原始图像,这些样本将成为后续所有步骤的起点。爬取完成后,检查图像质量,确保每张都包含清晰的四位数字,为预处理打好基础。
OpenCV图像二值化与去噪处理
原始验证码往往带有背景干扰。OpenCV提供强大工具来清理图像。首先转为灰度图,再应用阈值二值化去除噪声。以下是核心处理函数:
import cv2 as cv
import os
def hand_code():
path = 'picture/original_code'
picture_list = os.listdir(path)
for z, i in enumerate(picture_list):
img = cv.imread('{}/{}'.format(path, i), cv.IMREAD_GRAYSCALE)
retval, handle_img = cv.threshold(img, 0, 255, cv.THRESH_BINARY)
for y in range(4):
cv.imwrite('picture/handle_code/{}-{}.jpg'.format(z, y), handle_img[0:20, y*20:(y+1)*20])
if __name__ == '__main__':
hand_code()这段代码遍历文件夹内所有图像,进行灰度转换和二值化,然后按固定尺寸切分成四个单字符块。处理后每张图像仅保留一个数字的有效信息,极大简化后续识别任务。
二值化阈值选择至关重要。过低会保留过多噪声,过高则可能丢失字符细节。实际调试时可结合OTSU算法自动确定最佳阈值,进一步提升处理效果。
验证码字符切分与单字符提取
切分操作是简化识别的关键。对于规则四位数字验证码,固定位置切分已足够高效。假设图像尺寸为20像素高、80像素宽,每个字符占20x20区域。切分后得到独立图像,便于单独标注和训练。
如果字符位置略有偏移,可结合OpenCV的findContours函数检测轮廓后再裁剪。但在本场景中,简单切分已能满足需求,处理速度快且准确率高。
手动标注数据集的实用方法
切分后的单字符图像需要人工分类到0-9十个类别。创建十个文件夹,将对应图片放入即可。或者通过文件名直接标注,如0-001.jpg表示数字0。这种方式虽需一定时间投入,但标签准确性直接影响模型收敛速度。
建议收集至少每类200张样本,总量超过2000张以保证均衡分布。标注完成后,随机抽取20%作为测试集,用于后期性能验证。

图像数据转换为Numpy数组并序列化
为便于神经网络训练,将所有图像加载为Numpy数组。读取图片,统一resize到20x20,归一化像素值到0-1范围,并添加通道维度变为(样本数,20,20,1)。标签使用one-hot编码。
使用np.save序列化保存数组和标签文件,方便后续反复加载。以下是典型数据加载逻辑:
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# 加载并处理图像为数组
X = np.load('data.npy')
y = np.load('labels.npy')
encoder = OneHotEncoder(sparse=False)
y = encoder.fit_transform(y.reshape(-1,1))这一步完成后,数据已就绪,可直接传入模型训练。序列化还能在多机环境下快速共享数据集。
设计CNN神经网络模型架构
CNN的核心在于卷积层自动提取特征,池化层降低维度,全连接层完成分类。使用Keras构建简易模型:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(20,20,1)))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])第一层卷积使用32个3x3滤波器捕捉基本边缘,后续层逐步增加复杂度。softmax输出给出每个数字的概率分布。模型参数量小,适合单字符识别任务。
卷积操作的数学本质是滑动窗口与核相乘求和,能高效学习数字特有的笔画模式。池化则保留主要特征,防止过拟合。
模型训练优化与技巧
加载准备好的数据后开始训练。设置50个epoch,批大小32,使用10%数据作为验证集监控过拟合。加入ImageDataGenerator进行实时增强,如小角度旋转或添加高斯噪声,可显著提升模型泛化能力。
训练过程中观察损失曲线和准确率。若验证准确率停滞,可降低学习率或增加Dropout层。最终模型在测试集上准确率通常超过95%,完全满足生产需求。
使用早停回调和模型检查点,能自动保存最佳权重,避免长时间训练浪费资源。
部署应用与性能评估
训练完成后保存模型权重。在爬虫脚本中加载模型,对新验证码先切分再逐字符预测,最后拼接字符串。评估时使用混淆矩阵分析各数字识别精度,针对弱类补充样本。

实际部署可封装为函数,输入图片路径返回识别结果。结合多线程处理,能实现每秒数十张验证码的识别速度。
应对复杂验证码的智能方案
上述CNN方法完美解决规则数字验证码。但遇到极验或易盾这类滑动、点击或行为验证码时,自建模型难度和成本急剧上升。此时转向专业识别平台成为高效选择。
wwwttocrcom正是专为开发者打造的平台,它能精准解决极验和易盾验证码难题,并提供稳定API识别接口,支持远程调用。只需通过简单HTTP请求传入验证码参数,即可快速获得结果。这种方式无需本地维护模型和GPU资源,大幅节省开发时间与计算成本,特别适合大规模自动化项目。
常见问题解决与进阶调试
若准确率偏低,通常源于数据集质量或噪声处理不当。建议重新检查二值化效果,或扩充样本数量。调试时可输出中间切分图像验证切分是否正确。
进阶方向包括迁移学习使用预训练模型,或结合LSTM处理序列验证码。无论哪种方式,持续迭代数据和模型是保持高识别率的关键。