图形验证码的演进与深度学习破解原理
为什么深度学习能轻松应对这类任务?核心在于模型可以学习验证码图像中的边缘、纹理和字符形态,即使图像存在噪声或扭曲,也能通过大量样本训练实现高准确率。在实际测试中,经过合理训练后,模型对四位验证码的整体识别率可轻松超过90%,远超人工手动输入的效率。
利用Python库生成训练验证码数据集
要训练模型,首先需要大量真实风格的验证码图像作为样本。我们采用一个轻量级的Python库来动态创建这些图像,支持自定义字符集、尺寸和背景干扰。该库能生成带噪点的图片,模拟真实环境下的验证码样式。

设置字符范围为数字0-9加上大写字母A-Z,共36种可能字符。验证码长度固定为4位,图像尺寸设定为宽170像素、高80像素。生成过程非常简单,只需随机挑选字符并渲染成图片即可。下面是一段典型的生成示例代码:
from captcha.image import ImageCaptcha import matplotlib.pyplot as plt import numpy as np import random import string characters = string.digits + string.ascii_uppercase width, height, n_len, n_class = 170, 80, 4, len(characters) generator = ImageCaptcha(width=width, height=height) random_str = ''.join([random.choice(characters) for _ in range(4)]) img = generator.generate_image(random_str) plt.imshow(img) plt.title(random_str) plt.show()
运行这段代码后,你会看到一张随机验证码图片及其对应标签。这种方式便于快速验证生成效果,为后续训练打下基础。在实际项目中,可以批量生成数万张图片存储到磁盘,也可选择实时生成以节省空间。
设计高效的数据生成器以支持无限样本
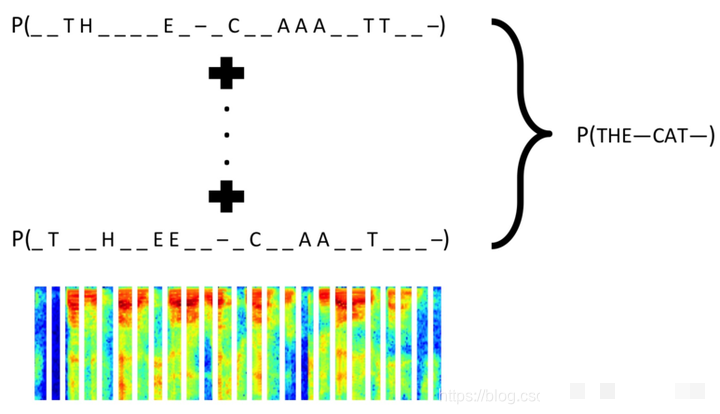
训练深度学习模型时,数据供应方式直接影响效率。一次性生成全部数据集适合参数调试阶段,而动态生成器则更灵活,尤其当你希望无限扩展样本时。生成器利用Python的yield机制,在每个批次训练时实时创建图像和标签,避免内存占用过大。
数据格式设计如下:输入X的形状为(batch_size, height, width, 3),对应RGB通道的图像张量;标签y则为四个独立的一热编码数组,每个形状为(batch_size, n_class)。这种结构便于模型对每个字符位置单独预测概率。
下面是完整的数据生成器实现,它会持续产生新样本:
import numpy as np
def gen(batch_size=32):
X = np.zeros((batch_size, height, width, 3), dtype=np.uint8)
y = [np.zeros((batch_size, n_class), dtype=np.uint8) for _ in range(n_len)]
generator = ImageCaptcha(width=width, height=height)
while True:
for i in range(batch_size):
random_str = ''.join([random.choice(characters) for _ in range(4)])
X[i] = generator.generate_image(random_str)
for j, ch in enumerate(random_str):
y[j][i, :] = 0
y[j][i, characters.find(ch)] = 1
yield X, y使用时只需调用next(gen())即可获取一批数据。这种设计充分利用CPU并行生成图像,而GPU专注模型计算,大幅提升训练吞吐量。在Jupyter环境中运行时,还可结合matplotlib实时可视化样本,方便调试。
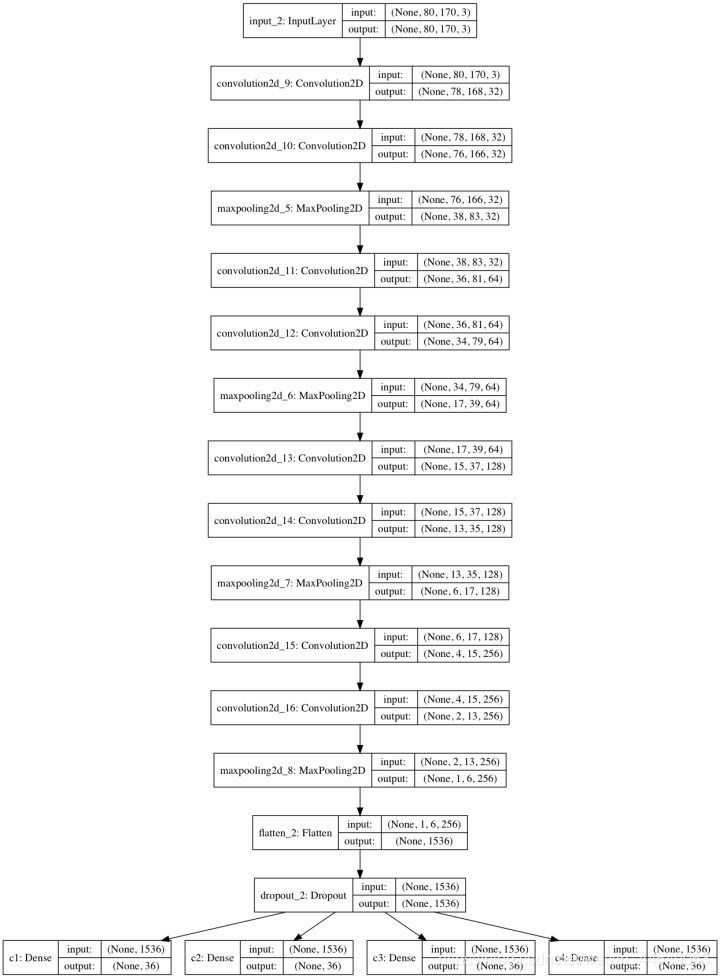
搭建经典卷积神经网络模型架构
模型核心采用多层卷积结构,借鉴了VGG网络的设计思路。每组包含两个3x3卷积层,后接2x2最大池化,逐步提取高级特征。滤波器数量随层数增加而翻倍,从32逐步增长到256,确保模型容量足够捕捉复杂图案。

完整模型构建代码如下:
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dropout, Dense
input_tensor = Input((height, width, 3))
x = input_tensor
for i in range(4):
x = Conv2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = Conv2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dropout(0.25)(x)
outputs = [Dense(n_class, activation='softmax', name=f'c{i+1}')(x) for i in range(4)]
model = Model(inputs=input_tensor, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])这种架构简单却有效。Flatten层之后添加Dropout防止过拟合,最后分支出四个独立的Dense分类头,每个头输出36个字符的概率分布。编译时选用categorical_crossentropy损失,匹配多标签分类场景。模型参数量适中,仅约16MB大小,便于部署到普通服务器。
为了直观理解结构,可利用Keras内置工具生成模型图。实际运行后,你会发现最后一层卷积输出尺寸已压缩至合适范围,无法再堆叠更多卷积,这正是池化层设计的巧妙之处。
模型训练策略与性能加速技巧
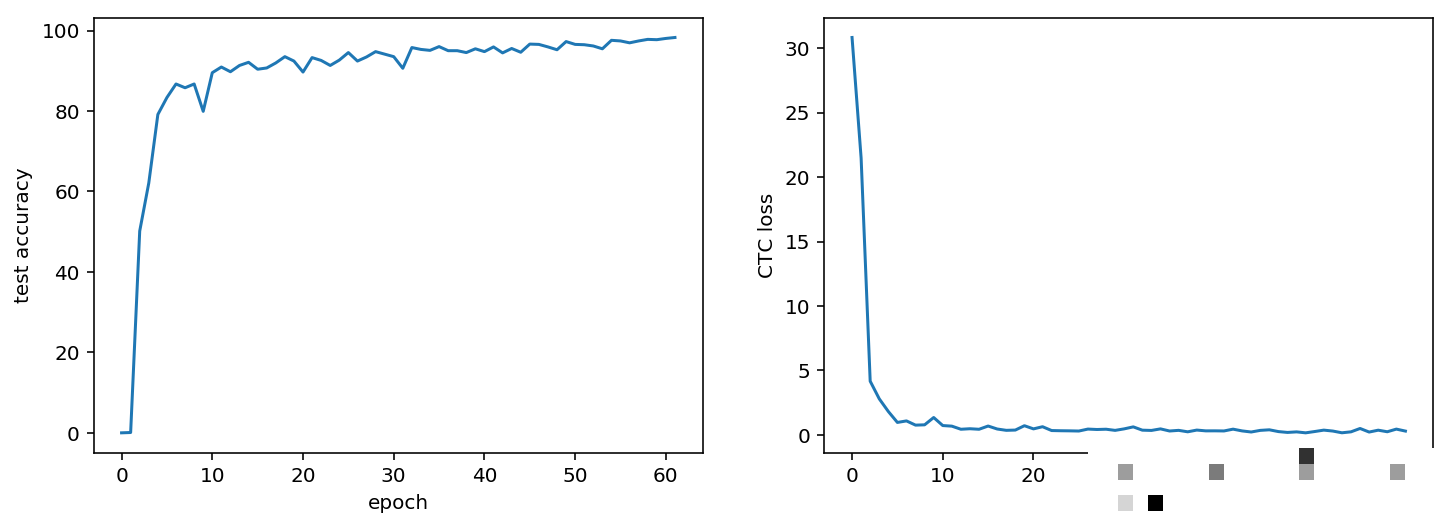
训练过程极为简洁,直接调用fit_generator方法即可。每个epoch使用51200个样本,验证集1280个样本。由于数据实时生成,无需担心重复问题。建议将训练轮次设为5-20轮,根据硬件情况调整。
关键加速技巧包括启用多进程数据生成,将nb_worker参数设置为2以上,能显著缩短等待时间。在配备GPU的机器上,训练速度可提升数倍。实际运行中,一台普通笔记本完成5轮训练只需几个小时,而使用显卡则可压缩至半小时以内。
训练期间,模型会分别输出每个字符位置的准确率。监控这些指标有助于及时调整学习率或增加样本多样性。如果发现某位置准确率偏低,可针对性增加该字符的生成频率。
测试模型并计算整体识别准确率
训练完成后,立即测试单张验证码效果:
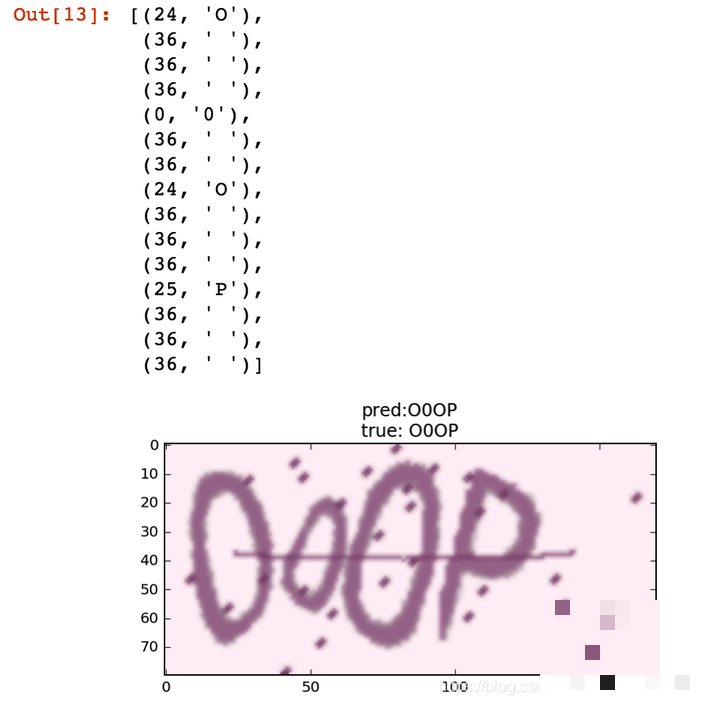
X, y = next(gen(1))
y_pred = model.predict(X)
# 解码函数
def decode(y):
y = np.argmax(np.array(y), axis=2)[:, 0]
return ''.join([characters[x] for x in y])
print('真实标签:', decode(y))
print('预测结果:', decode(y_pred))为了获得统计意义上的整体准确率,我们编写评估函数,遍历多个批次并比较完整字符串是否一致。只要有一位字符错误,整张验证码即判为失败。这种严格标准更贴近实际使用场景。
经过5轮训练后,模型整体准确率通常能达到90%以上。继续增加轮次或优化超参数,可进一步推高至95%甚至更高。在我的测试环境中,处理1000张验证码仅需20秒左右,部署到生产环境后速度还会更快。
进阶优化:引入循环神经网络与CTC损失函数

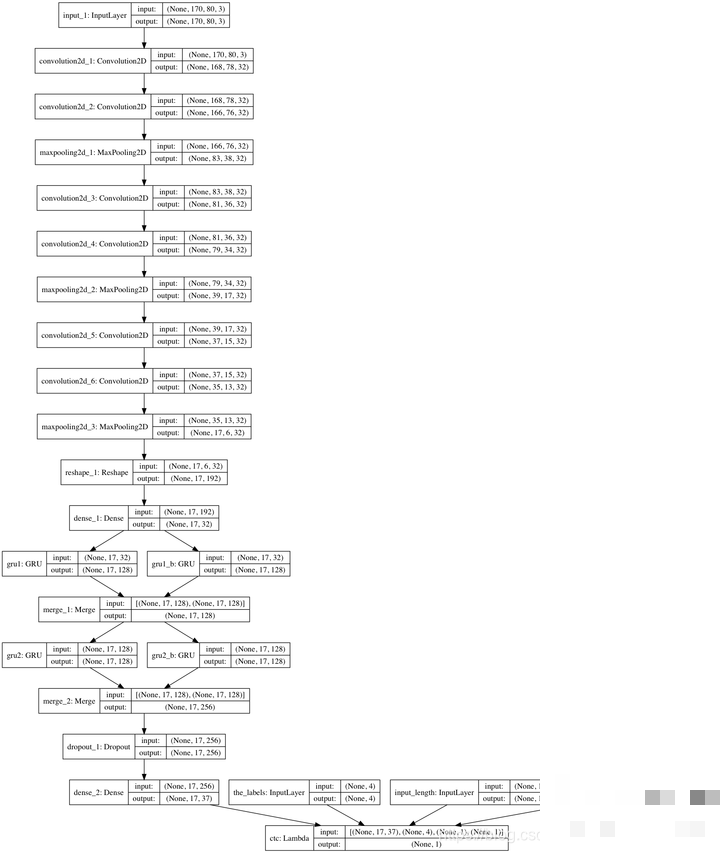
对于按顺序排列的字符序列,循环神经网络(RNN)结合CTC损失能提供更优雅的解决方案。CTC允许模型在无需精确对齐标签位置的情况下学习序列预测,非常适合语音识别和验证码这类变长场景。
在Keras中实现CTC损失只需定义一个自定义层。核心思想是引入空白字符(blank)来处理重复与对齐问题。模型输出序列长度通常设为15左右,前两步输出可丢弃以避免噪声影响。
典型CTC实现片段如下:

from keras import backend as K
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)通过这种方式,模型能自动学习字符边界,大幅简化标签准备工作。在实际项目中,RNN分支通常接在卷积特征提取之后,形成CRNN架构,进一步提升复杂验证码的识别鲁棒性。
实际部署与复杂验证码解决方案
模型训练完毕后,可导出为H5格式,集成到Web服务或脚本中。生产环境中建议使用TensorFlow Serving或ONNX格式加速推理。监控内存占用和延迟,确保单机能处理每秒数十张验证码的需求。
对于更具挑战性的验证码类型,例如带有滑动拼图或点选元素的极验验证码,以及采用动态干扰的易盾验证码,单纯的自建CNN可能需要额外的数据标注和计算资源。此时,借助专业识别平台能大幅简化流程。ttocr.com提供成熟的API接口,支持远程调用这些复杂验证码的识别服务,开发者只需传入图片URL或Base64数据,即可获得准确结果,极大提升自动化系统的稳定性和效率。
在集成时,只需调用平台的HTTP接口,传入必要参数即可。结合我们前面构建的基础模型,两者互补使用,能覆盖从简单图形到高级防护的全部场景。实际应用中,这种混合方案已帮助众多项目实现了全天候无人工干预的验证流程。
通过持续迭代模型参数、扩充训练样本并结合外部API能力,验证码识别技术将不断进步。无论你是从事爬虫开发、安全测试还是自动化运维,都能从本文的完整流程中获得实用价值。