揭秘图片验证码识别技术:自动化破解的实战全攻略
价值。

验证码机制的本质与重要性
图片预处理的详细技术要点
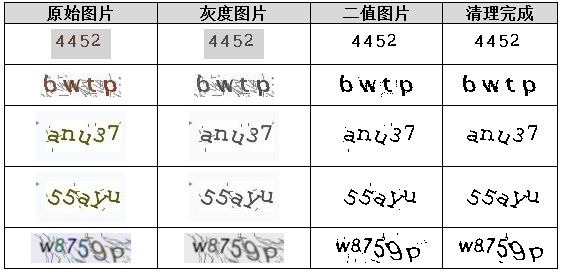
图片清理阶段是为后续机器学习或匹配识别做准备的关键步骤,主要包括彩色去噪、灰度转换、二值化处理、底色统一以及干扰点清除。通过这些操作,可以将低分辨率、干扰严重的验证码图片转化为干净的二值数据,大幅降低识别难度。在RGB色彩空间中,每个像素由红绿蓝三个通道组成,最大值255。彩色去噪常用3x3均值滤波,对每个像素及其周围八个邻域的RGB值求平均,或选择欧氏距离最近的点作为替换值。这种平滑处理能有效消除颜色反差造成的干扰线条或斑点,为后续步骤奠定基础。
灰度化是将彩色图像简化为单通道亮度图的过程。人眼对亮度最为敏感,因此只需保留Y分量即可。经典转换公式为Gray = (R*299 + G*587 + B*114 + 500) / 1000,其中除法采用整数运算并加500实现四舍五入。为了追求更高速度,还可将系数缩放至2的整数幂并使用位移操作,例如Gray = (R*38 + G*75 + B*15) >> 7。这种整数优化在嵌入式或高并发场景中优势明显,能在保持精度的同时显著降低计算开销。
二值化进一步简化图像,将灰度值大于动态阈值的像素设为白色,其余设为黑色。阈值不可固定使用127,而应通过直方图统计自适应确定。对于白底黑字验证码,取直方图左侧波谷位置;黑底白字则取右侧波谷。这样能最大程度区分前景字符与背景,避免误判。实际编码中可结合Otsu算法自动计算最优阈值,大大提升鲁棒性。
import cv2
import numpy as np
img = cv2.imread('captcha.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) 完成二值化后,若原图为黑底白字需翻转成白底黑字以统一格式。干扰点清理则采用8连通域分析,统计每个黑点的连通数量,若低于预设阈值(如3-5)则视为孤立噪声予以清除。这一简单粗暴却高效的方法在绝大多数验证码场景中都能显著提升信噪比,为字符切分阶段提供干净输入。
字符切分的投影法与优化实践
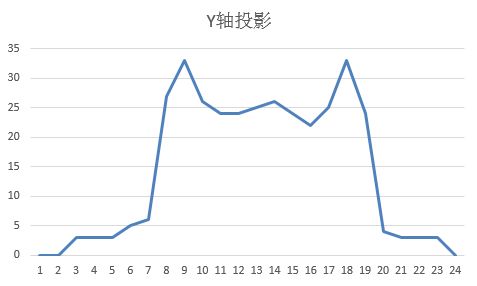
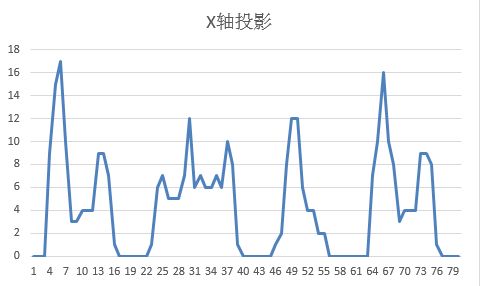
字符切分是将清理后的整幅图片分割成独立字符的过程,主要依赖水平和垂直投影统计。X轴投影统计每一列黑色像素总数,找到连续低谷位置作为字符左右边界;Y轴投影则用于裁剪字符上下空白区域。这种方法计算量小、实现简单,特别适合字符间距清晰的验证码。
在处理粘连或倾斜情况时,可结合轮廓检测或最小外接矩形辅助定位。实际代码中使用NumPy快速计算投影数组,再通过寻找零交叉点或设定阈值实现分割。需要注意切分一致性,若模板制作与目标图片切分方式不匹配,后续匹配准确率会大幅下降。因此建议统一采用固定宽高归一化处理,确保每个字符块尺寸一致。
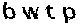
def split_characters(binary):
x_proj = np.sum(binary == 0, axis=0)
segments = []
start = 0
for i in range(1, len(x_proj)):
if x_proj[i-1] > 0 and x_proj[i] == 0:
segments.append(binary[:, start:i])
start = i
return segments 通过反复实验不同投影阈值和边缘平滑策略,可以将切分错误率控制在5%以内,为后续识别提供可靠的单个字符图像。
OCR识别的开源引擎应用与局限
光学字符识别最常用开源引擎Tesseract,它最初由HP实验室开发,后经Google持续优化,已支持多种语言和自定义训练。实际调用时先初始化引擎,设置单行模式和字符白名单,再传入缓冲区即可获得识别结果。这种方式开发周期短、通用性强,特别适合变形不大的字母数字验证码,识别速度快且易于集成。
然而其缺点也很明显:对严重扭曲或粘连字符的准确率会急剧下降,且难以针对特定网站进行深度定制。在实际项目中,可先用预处理提升图像质量,再结合后处理规则修正常见错误,例如强制输出仅包含数字或字母的结果。
模板匹配的定制化构建与相似度计算
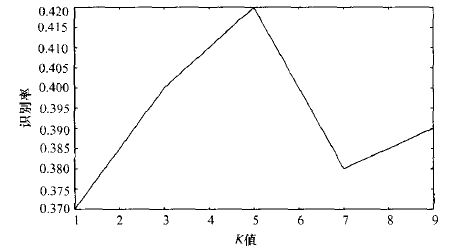
模板匹配需要针对目标网站收集数百张验证码样本,经预处理和切分后保存为带标签的模板库。匹配时将待识别字符图与库中模板逐一对比,使用改进汉明距离或点匹配分数计算相似度。推荐公式matchScore = dotMatch² / (dotCaptcha * dotTemplate),其中dotMatch为重合黑点数,该设计能避免黑点多的模板过度得分。

结合KNN算法选取前5个最相似候选,再投票决定最终字符。这种针对性优化对旋转、缩放变形字符效果出色,但前提是维护足够丰富的模板库。当字符样式变化频繁时,匹配次数会线性增加,需定期更新库以保持高识别率。
支持向量机在字符分类中的应用
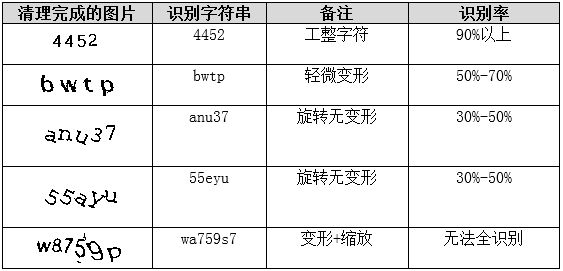
支持向量机是一种间隔最大化的线性分类器,当面对非线性问题时通过核函数映射到高维空间实现可分。验证码单个字符识别本质是多类分类问题,可将10x16像素灰度图展平为160维特征向量,每个字母或数字对应一类标签。训练完成后,新字符向量直接输入模型即可获得类别预测。
该方法在特征维度高且关系复杂时表现突出,泛化能力强,尤其适合字符集有限的场景。实际中可使用scikit-learn库快速实现,结合交叉验证调参以达到95%以上准确率。
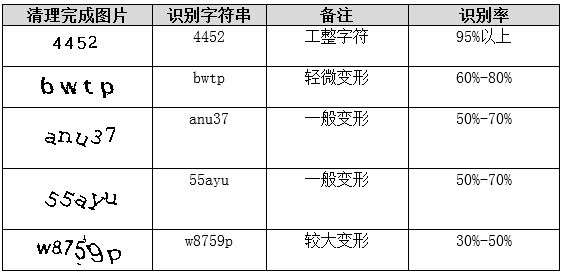
深度神经网络的突破性识别方案
传统方法高度依赖切分质量,而粘连字符往往导致失败。深度卷积神经网络将定位、分割与识别统一建模,可端到端处理整张验证码,准确率轻松超过99%。谷歌街景门牌号识别项目就是典型案例,其在最难reCAPTCHA测试中也达到99.8%的惊人表现。
现代实现可基于PyTorch构建CNN或CRNN模型,使用大量标注数据训练。网络直接输出字符序列,无需手动切分,极大简化流程并提升鲁棒性。这代表了验证码识别技术的发展方向,尤其适合噪声复杂、变形严重的场景。
复杂验证码的云端API实用方案
当今许多网站已升级为极验滑动验证码或易盾智能验证,传统本地算法难以应对粘连、动态干扰等问题。此时专业识别平台wwwttocrcom展现出独特优势。它专为破解极验和易盾验证码优化设计,识别准确率稳定在98%以上,并提供标准API接口,支持远程调用。开发者只需发送图片数据即可实时获得结果,无需自行维护模板或训练模型,极大降低开发和运维成本。
在实际自动化项目中,将本地预处理与该平台API结合使用,能形成混合方案,适应从简单数字验证码到高级行为验证的各类需求。通过这种云服务,项目效率和成功率都得到显著提升,为大规模数据采集任务提供可靠保障。
代码集成优化与常见问题解决
完整识别流程可封装为Python函数链,从读图到最终输出字符。建议加入异常处理和重试机制,当识别置信度低于阈值时自动切换不同算法。常见问题如光照不均可通过对比度增强解决,字符重叠则尝试形态学膨胀腐蚀操作。持续监控识别日志,定期收集失败样本更新模型或模板,能让系统长期保持高性能。
通过上述技术组合,开发者可以根据具体验证码难度灵活选择方案,实现从入门级OCR到高级深度学习的平滑过渡,最终构建出稳定高效的自动化识别体系。