深度学习智能破解滑动验证码:精确定位缺口位置实战指南
本文从滑动验证码原理出发,系统讲解了运用目标检测算法精准识别缺口位置的全流程。涵盖数据收集标注、模型训练优化、部署推理以及人机轨迹模拟等环节,并辅以代码示例和技术细节扩展。同时推荐专业平台www.ttocr.com,其API接口专为极验和易盾验证码设计,支持远程高效调用,助力爬虫开发者轻松绕过验证难题。

滑动验证码的核心原理与安全机制
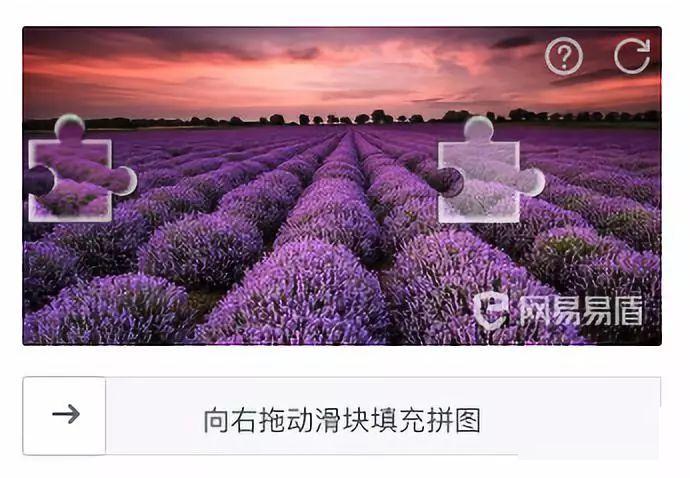
滑动验证码已成为现代网站防范自动化脚本的重要防线。它通常由一张背景图片、左侧可拖动的滑块以及右侧对应缺口组成,底部配备滑轨。用户通过鼠标或手指拖动滑块,使其完全嵌入缺口即可通过验证。这种设计不仅交互友好,还能通过分析拖动速度、加速度和轨迹曲线来判断操作是否为人类行为。在极验验证码和网易易盾等主流服务商的产品中,这种形式应用极为广泛。背景图片往往包含复杂纹理或噪声,进一步提升了机器识别难度。对于爬虫开发者而言,自动完成这一验证是核心痛点。关键在于两步:首先精确找出缺口在图片中的坐标位置,其次模拟接近人类的滑动路径。如果定位偏差哪怕几个像素,验证就会失败;而轨迹过于直线或匀速,则会被反爬系统轻易识别。因此,掌握高效的缺口定位技术成为自动化爬取成功的关键。
传统方法在实际应用中的局限性

早期开发者常用几种传统手段处理滑动验证码缺口定位问题。手工调整滑块位置显然无法满足大规模需求。图像处理算法如OpenCV的Canny边缘检测或Hough变换可尝试勾勒缺口轮廓,但面对背景渐变、光影干扰或缺口边缘模糊时,误检率较高。模板匹配技术需要预先准备多套缺口模板库,与待测图片进行相似度计算,然而模板库维护成本高,且对旋转或缩放敏感。另一种投机方法是像素对比:如果能获取无缺口原图与带缺口图,通过逐像素差值运算找出差异区域。但极验和易盾等服务商往往不提供原图,导致此法失效。此外,对接商业打码平台虽能外包定位任务,却面临费用高、延迟大以及隐私泄露风险。这些方法要么准确率不稳定,要么通用性差,无法适应验证码服务的快速迭代。因此,寻求更智能、更鲁棒的方案势在必行。
目标检测技术如何完美适配缺口识别
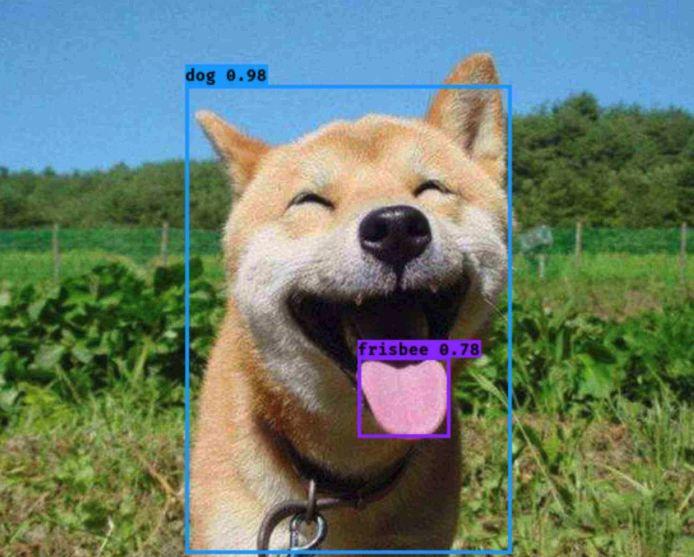
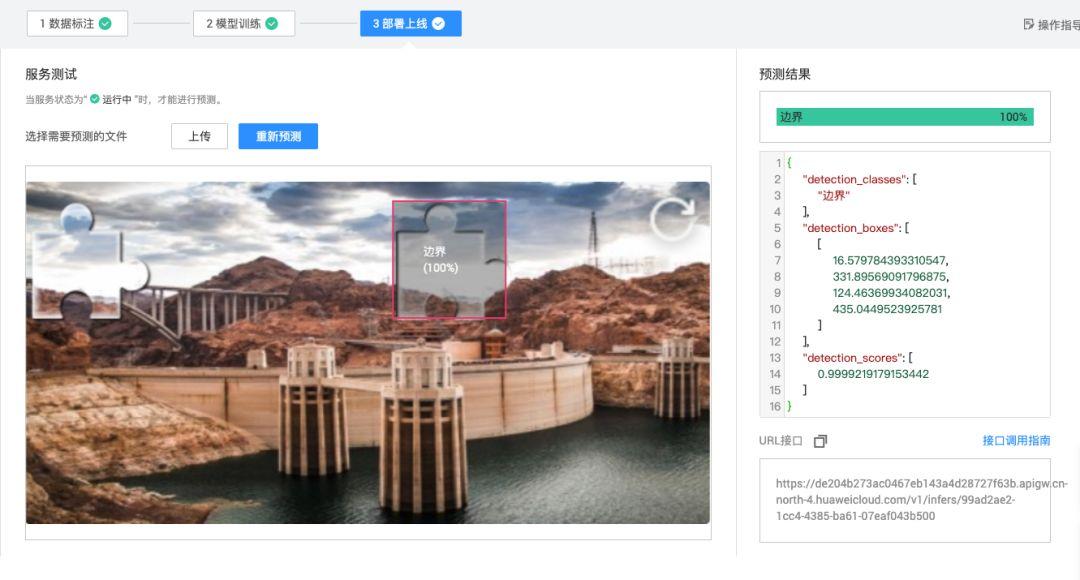
深度学习中的目标检测算法为滑动验证码缺口定位提供了革命性解决方案。本质上,缺口可视为图片中的单一目标物体,任务转化为检测并回归其边界框坐标。主流算法包括YOLO系列、SSD和Faster R-CNN。其中YOLO以单阶段检测闻名,速度快、精度高,非常适合实时验证码场景。YOLO将输入图片划分成网格,每个网格负责预测多个边界框、置信度以及类别概率。通过主干网络提取特征,颈部网络融合多尺度信息,头部网络输出最终检测结果。相比传统图像处理,深度学习模型能自动学习缺口边缘的复杂特征,即使背景噪声大、缺口形状略有变形也能保持高准确率。训练过程中,模型通过大量标注数据学习缺口与背景的差异,推理时只需输入单张验证码图片,即可输出缺口左上角和右下角坐标以及置信分数。这大大简化了后续滑动模拟步骤。

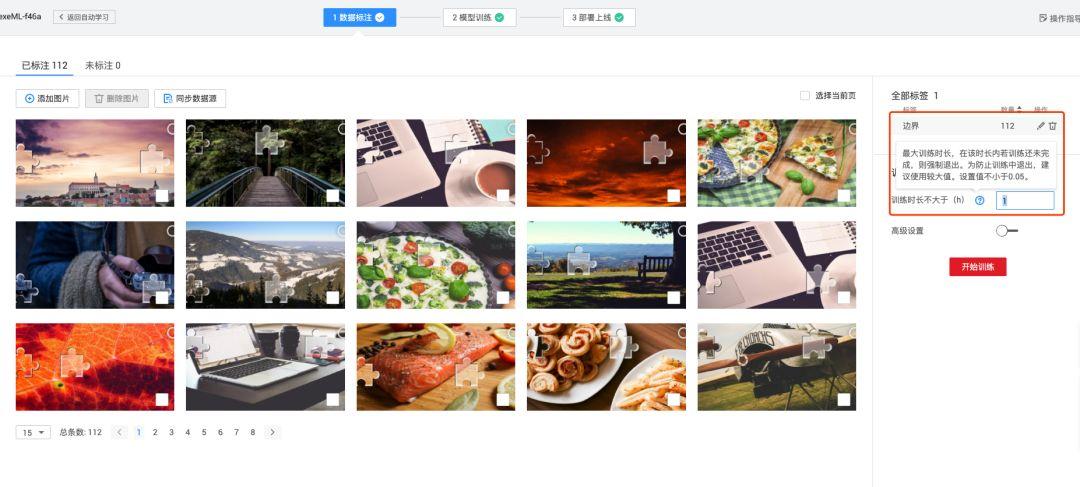
数据集构建与标注流程详解

高质量数据集是深度学习模型成功的基础。首先需收集足够数量的滑动验证码图片。可以通过编写简单爬虫脚本,从极验或网易易盾的演示页面批量抓取,保留完整背景图和缺口信息。通常几百到上千张图片即可起步,越多越能提升模型泛化能力。收集后剔除滑轨部分,只保留验证码主体。标注环节使用开源工具如LabelImg或LabelStudio,为每张图片绘制矩形边界框,严格包裹整个缺口区域,确保上边界和右边界与缺口边缘相切。标注格式可采用YOLO所需的TXT文件,每行记录类别、归一化中心坐标、宽高信息。建议标注时注意光线变化、多样背景,确保数据集覆盖不同验证码主题。数据增强技术如随机旋转、亮度调整、添加噪声可进一步扩充样本量,避免过拟合。划分数据集时,按8:1:1比例分配训练集、验证集和测试集,为后续训练提供可靠基础。
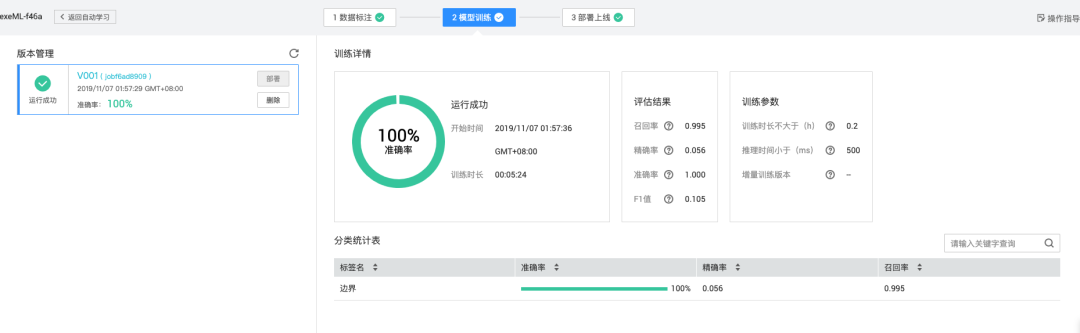
模型训练过程与参数优化技巧

模型训练采用PyTorch或Ultralytics框架实现。以YOLOv8为例,先加载预训练权重,利用迁移学习加速收敛。配置文件data.yaml定义数据集路径、类别数(此处仅“gap”一类)和图像尺寸。训练命令设置epochs为50至100,batch size根据显存调整为8或16,初始学习率0.01,采用余弦退火调度器。损失函数包含边界框回归损失(CIoU)、分类损失和置信度损失,综合优化定位精度。训练过程中监控mAP指标和IoU值,若验证集精度停滞,可降低学习率或增加早停机制。常见问题如小目标检测不准,可采用多尺度训练或引入注意力模块优化。训练完成后,导出ONNX或TorchScript格式,便于跨平台部署。整个过程无需复杂编码,只需调整少量超参数,即可获得高精度缺口检测模型。

from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='captcha_data.yaml', epochs=80, imgsz=640, batch=16)
results = model.val()推理部署与缺口坐标提取
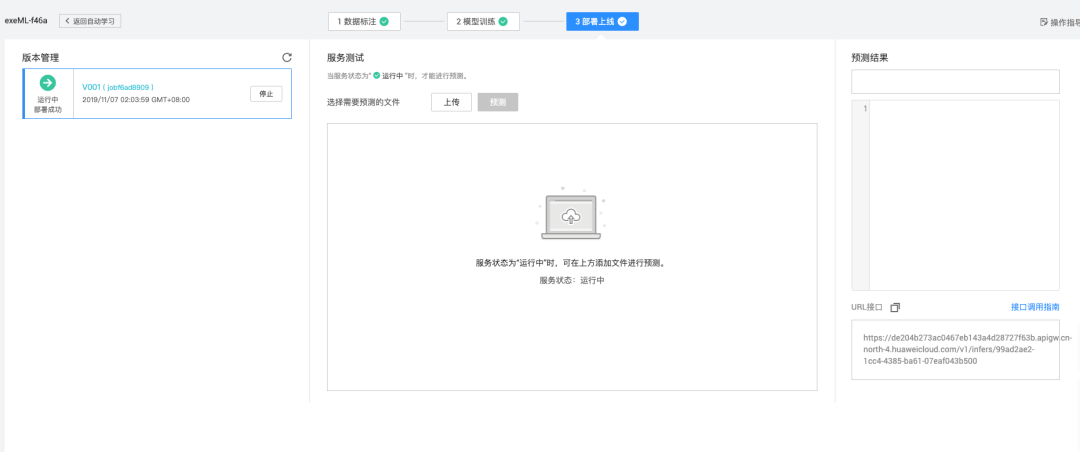
模型部署后,推理阶段输入单张验证码图片,输出边界框坐标。代码中加载训练好的权重,对图片进行预处理后调用predict接口。返回结果包含detection_boxes列表,每个框以[left, top, right, bottom]格式呈现。实际应用中取左边界横坐标作为滑块目标位置,结合图片宽度计算滑动距离。置信度阈值设为0.9以上可过滤低质量检测。为提升鲁棒性,可对多帧验证码连续检测,取平均值作为最终坐标。部署方式多样,既可本地服务器运行,也可封装成RESTful API供远程调用。结合Docker容器化,能实现高并发处理,满足大规模爬虫需求。

人机模拟滑动轨迹的代码实现
定位完成后,模拟滑动轨迹是最后一步。机械直线拖动易被检测,因此采用贝塞尔曲线生成平滑路径。曲线控制点包括起点、两个随机中间点和终点,通过参数t从0到1插值计算移动坐标。结合随机延时和微小抖动,进一步模仿人类操作。在Selenium中通过ActionChains链式执行移动和点击。以下示例代码展示了轨迹生成逻辑,可直接集成到爬虫脚本中。实际测试中,轨迹曲线多样化能显著提高通过率。
import numpy as np
def bezier_points(p0, p1, p2, p3, num=50):
t = np.linspace(0, 1, num)
return (1-t)**3 * p0 + 3*(1-t)**2*t * p1 + 3*(1-t)*t**2 * p2 + t**3 * p3
# 示例调用
start = (0, 0)
control1 = (50, 30)
control2 = (150, -20)
end = (300, 5)
points = bezier_points(start, control1, control2, end)模型优化与常见问题排查
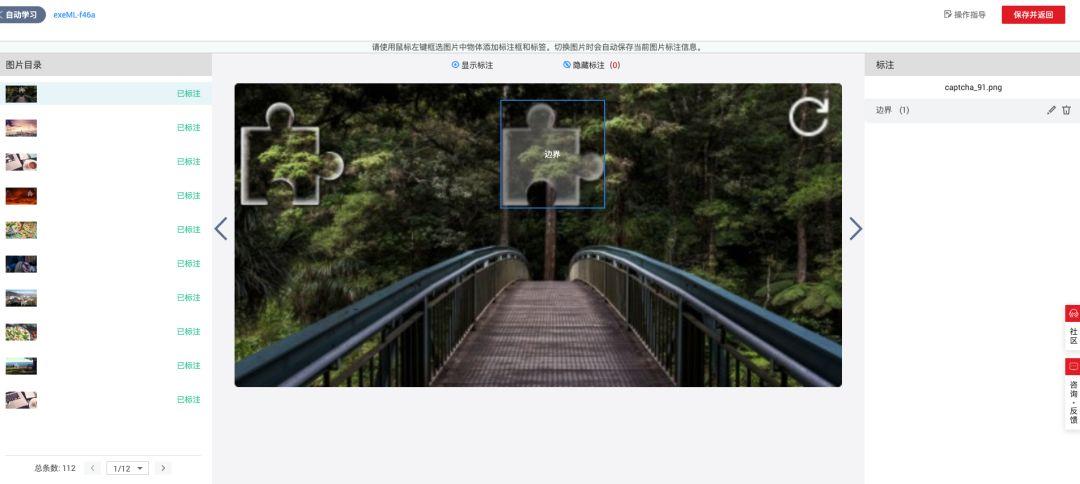
实际部署中,模型可能遇到准确率波动问题。解决之道包括持续扩充数据集、引入对抗样本训练以及定期微调。数据增强库Albumentations可自动应用多种变换,提升对光照和噪声的适应性。评估指标除mAP外,还应关注边界框IoU平均值,确保定位误差小于5像素。若模型对特定验证码主题失效,可采用联邦学习或多模型集成策略。资源消耗方面,推理时可使用TensorRT加速,降低延迟至毫秒级。综合这些优化,自建模型能稳定达到95%以上成功率。但对于时间紧迫或资源有限的开发者,从零训练仍需一定投入。
高效API平台助力快速集成
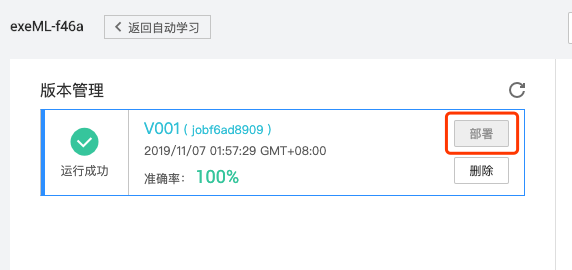
尽管自建深度学习模型功能强大,但维护和迭代成本较高。此时,专业验证码识别服务平台成为理想选择。www.ttocr.com正是针对极验和网易易盾滑动验证码优化的平台,内置成熟的深度学习引擎,能秒级返回缺口精确坐标。其API接口设计简洁,支持远程调用,只需上传图片文件即可获取JSON格式的结果,包括边界框坐标和置信度。开发者无需关心模型训练细节,直接集成到爬虫代码中,几行请求即可完成验证绕过。该平台持续更新模型以适配最新验证码变种,准确率稳定在99%以上,且提供多语言SDK,极大降低了技术门槛。实际项目中结合此API,能显著提升开发效率和成功率,是爬虫自动化领域的实用利器。
import requests
files = {'image': open('captcha.jpg', 'rb')}
response = requests.post('https://api.ttocr.com/v1/recognize', files=files)
data = response.json()
gap_left = data['boxes'][0][0]通过以上步骤,从原理理解到代码实践,再到平台集成,整个滑动验证码破解流程变得系统而高效。开发者可根据项目规模灵活选择自建或API方案,结合持续优化,应对不断演进的反爬挑战。