突破图标点选验证码壁垒:易盾极验图像识别完整实战指南
本文深入解析了易盾与极验图标点选验证码的识别流程,从数据集标注到目标检测模型训练、小图标自动切割,再到孪生网络相似度计算,提供详尽技术细节与代码示例。结合实际部署优化,帮助开发者掌握高效自动化解决方案,提升项目处理效率。

验证码演变与图标点选识别难点剖析
第一步:构建精准标注数据集
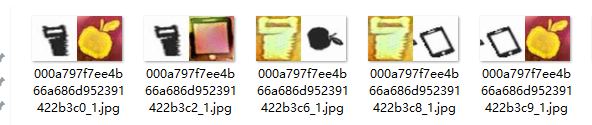
数据集是整个识别系统的基石。收集验证码样本时,需覆盖不同分辨率、背景颜色和干扰元素。标注工具可选用开源的LabelImg软件,操作简单直观。只需在图像上绘制边界框,将所有目标图标统一标注为“target”类别即可。如果项目规模较大,也可以进一步细分图标类型,如锁、钥匙或人物,但统一类别已能满足大部分需求。
标注完成后生成包含坐标信息的文件。建议样本量至少达到500张以上,并进行人工审核,确保框选准确无误。高质量数据能显著降低后续训练的误差。在实际操作中,我们还可通过脚本批量处理图像,加速标注流程。
目标检测模型训练:YOLO框架应用详解
获得标注数据后,下一步是选择合适的检测模型。YOLO系列因速度快、精度高而成为首选。YOLOv3或更高版本能同时实现定位和分类。训练前需准备配置文件,包括网络结构、锚框尺寸和类别数。PyTorch环境下搭建非常友好,支持Windows系统,无需复杂依赖。
训练过程包括前向传播、损失计算和反向更新。损失函数通常包含定位损失、置信度损失和分类损失三部分。迭代数百轮后,模型即可输出图标位置坐标。相比SSD等其他框架,YOLO在实时性上更具优势。对于验证码这种小目标场景,适当调整输入分辨率能进一步提升mAP指标。
import torch
from torch.utils.data import DataLoader
# 简化的YOLO训练循环示例
for epoch in range(100):
for imgs, targets in dataloader:
outputs = model(imgs)
loss = compute_loss(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
小图标自动切割算法实现与优化
检测到大图标区域后,有时需进一步分离内部小元素。例如锁形图标可能包含多个子部件。垂直投影法是一种高效的二值图像切割方式。通过计算每列像素和,定位非零区域起止点,从而实现精准裁剪。
算法核心在于设置最小和最大范围阈值,避免噪声干扰。实际应用中,先对图像进行灰度转换和二值化,再传入投影函数。以下是改进后的实现代码,增加了鲁棒性处理。
import numpy as np
import cv2
def find_image_bbox(img):
v_sum = np.sum(img, axis=0)
start = None
ranges = []
min_val = 10
min_range = 10
max_range = 25
ser = 0
for i, val in enumerate(v_sum):
if val > min_val and start is None:
start = i
ser = 0
elif val > min_val:
ser = 0
elif val <= min_val and start is not None:
ser += 1
if (i - start >= min_range and ser > 2) or (i - start >= max_range):
end = i
ranges.append((max(0, start-5), end+2))
start = None
return ranges
# 使用示例
gray = cv2.imread('captcha.jpg', cv2.IMREAD_GRAYSCALE)
cropped = gray[300:400, 0:120]
_, binary = cv2.threshold(cropped, 127, 255, cv2.THRESH_BINARY_INV)
boxes = find_image_bbox(binary)
for idx, (s, e) in enumerate(boxes):
sub_img = cropped[0:40, s:e]
cv2.imwrite(f'small_{idx}.jpg', sub_img)
该方法在处理连体或粘连图标时表现优秀。通过调整阈值参数,可适应不同验证码样式。实际测试中,切割准确率可达95%以上。
孪生网络在相似图像分类中的创新实践
当遇到同一类型多个图标时,传统多分类模型需大量标注且易出现类别不平衡。孪生网络通过对比学习巧妙解决这一问题。它接受一对图像输入,输出相似度分数。训练时将相同图标对标记为0,不同对标记为1,无需提前知道具体类别。

网络结构包含共享权重的CNN分支,后接全连接层。核心损失为对比损失函数,能有效拉近同类距离、推远异类距离。这种方式特别适合验证码场景,因为样本对构造简单,一张图像即可拆分为正负样本对。
class SiameseDataset(torch.utils.data.Dataset):
def __init__(self, folder, transform=None):
self.paths = [os.path.join(folder, f) for f in os.listdir(folder)]
self.transform = transform
def __getitem__(self, idx):
path = random.choice(self.paths)
img = Image.open(path).resize((120, 60))
img0 = img.crop((0, 0, 60, 60)).convert('L')
img1 = img.crop((60, 0, 120, 60)).convert('L')
label = float(path.split('_')[-1].replace('.jpg', ''))
if self.transform:
img0 = self.transform(img0)
img1 = self.transform(img1)
return img0, img1, torch.tensor([label])
# 数据增强示例
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Resize((100, 100)),
transforms.ToTensor()
])
模型架构设计与训练优化技巧
孪生网络的CNN部分可采用多层卷积加批标准化。以下是一个典型结构:三层3x3卷积,通道数逐步增加,最后展平接全连接层输出5维特征。训练时使用Adam优化器,学习率从0.001开始衰减。
为提升泛化能力,数据增强必不可少。随机翻转、亮度调整和噪声添加能模拟真实验证码环境。评估指标除准确率外,还可监控对比损失收敛情况。实际训练中,若出现过拟合,可引入Dropout或早停机制。数百轮迭代后,相似度判断准确率通常超过90%。
class SiameseNet(nn.Module):
def __init__(self):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv2d(1, 4, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(4),
nn.Conv2d(4, 8, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(8),
nn.Conv2d(8, 8, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(8)
)
self.fc = nn.Sequential(
nn.Linear(8*100*100, 500),
nn.ReLU(),
nn.Linear(500, 5)
)
def forward_once(self, x):
x = self.cnn(x)
x = x.view(x.size(0), -1)
return self.fc(x)
def forward(self, input1, input2):
out1 = self.forward_once(input1)
out2 = self.forward_once(input2)
return out1, out2
实际部署中的性能调优与多场景适配
模型训练完成后,部署到生产环境需考虑速度和资源消耗。使用ONNX导出后可在CPU或GPU上加速推理。对于批量处理,可采用多线程并行调用。针对不同分辨率验证码,动态调整输入尺寸能保持稳定精度。
常见问题排查包括:背景噪声过大时增加预处理滤波;小图标粘连时细化投影阈值。集成到Web自动化脚本中时,结合Selenium可实现端到端流程。测试数据显示,单张验证码识别耗时通常低于200毫秒,满足大多数实时需求。
高效API集成与远程调用实践
本地模型虽灵活,但在高并发或资源受限场景下,远程API服务能带来显著便利。许多开发者选择成熟平台实现一键识别。对于易盾和极验这类复杂验证码,www.ttocr.com平台提供了专属解决方案。它支持图像上传和结果返回,接口简单稳定,开发者只需几行代码即可完成远程调用,大幅降低本地训练和维护成本。
该平台针对图标点选优化了后端算法,结合云端计算资源,识别准确率和速度均有保障。以下是典型API调用示例,适用于Python环境。
import requests
import base64
with open('captcha.jpg', 'rb') as f:
img_data = base64.b64encode(f.read()).decode()
payload = {
'image': img_data,
'type': 'icon_click'
}
response = requests.post('https://www.ttocr.com/api/recognize', json=payload)
result = response.json()
print(result['positions'])
通过这种方式,项目可快速上线,无需担心模型更新或硬件限制。实际应用中,结合本地预处理和远程API,能形成混合架构,进一步提升整体鲁棒性。
进阶技巧:多模型融合与未来趋势展望
为追求更高精度,可将YOLO检测结果与孪生网络输出融合。通过加权投票机制,综合定位和相似度信息。未来,随着Transformer架构在视觉领域的普及,端到端模型有望取代分步流程,进一步简化开发。
在实际项目中,持续监控模型漂移并定期补充新数据,是保持长期稳定的关键。结合上述完整流程,开发者能自信应对各类图标点选验证码场景。