易盾验证码算法逆向实战指南:加密机制全流程拆解
本文系统阐述了易盾验证码的发包流程、指纹参数生成、随机字符串算法以及验证接口的加密逻辑。通过详细的代码示例和调试方法,揭示了轨迹数据处理的核心技术,为开发者提供实用逆向参考。同时介绍了专业平台在实际应用中的优势。
易盾滑动验证码防护机制基础解析
易盾作为一款广泛应用的验证码服务,其滑动验证模式要求用户通过拖动滑块精确匹配背景图片中的缺口位置,从而判断操作是否来自真实人类。这一机制背后融合了浏览器指纹采集、随机参数生成以及多层数据加密技术,旨在有效阻挡自动化脚本的入侵。理解这些底层逻辑对于开发者来说至关重要,尤其是在需要处理验证码相关的项目中。
整个验证过程并非简单的图片交互,而是涉及多个网络请求的协同工作。从初始令牌获取到最终数据校验,每一步都经过严格的加密保护。逆向分析这些步骤可以帮助我们还原完整的交互链路,并在此基础上优化自己的实现方案,避免在实际环境中遇到验证失败的问题。
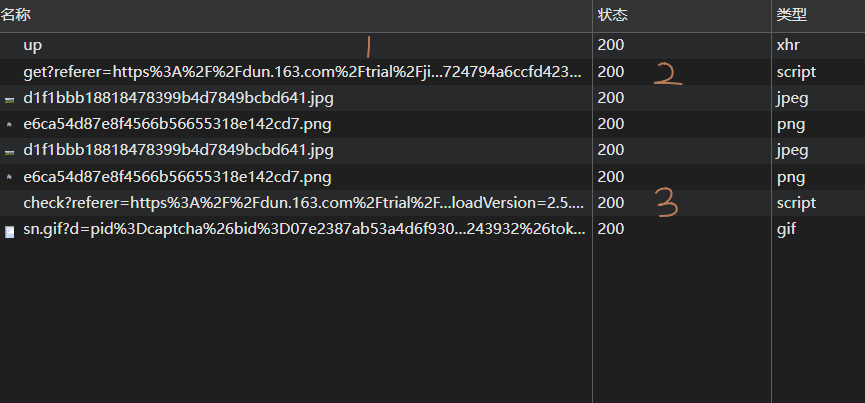
完整发包交互流程详解
发包流程起始于up包的发送,这一请求的主要目标是获取irtoken令牌。irtoken作为核心标识,可以通过固定值的方式使用,这一步简化了后续的多次请求处理。接下来,系统会利用irtoken结合fp指纹和cb参数生成图片请求,返回对应的token信息。最后一步则是构造data数据包并提交到check接口完成最终验证。
在实际操作中,固定irtoken后可以稳定获取背景图片,这为处理fp和cb环节创造了良好条件。开发者需要注意每个请求的参数依赖关系,如果任何一环加密不当,就会导致整个验证链路中断。通过捕获这些网络包,我们能清晰看到参数传递的先后顺序,并逐步定位加密入口。
此外,这一流程的设计充分考虑了重放攻击的防范,随机元素和时间戳的引入让每次请求都具有独特性。掌握这一流程后,逆向工作就能更有针对性,避免盲目尝试带来的时间浪费。
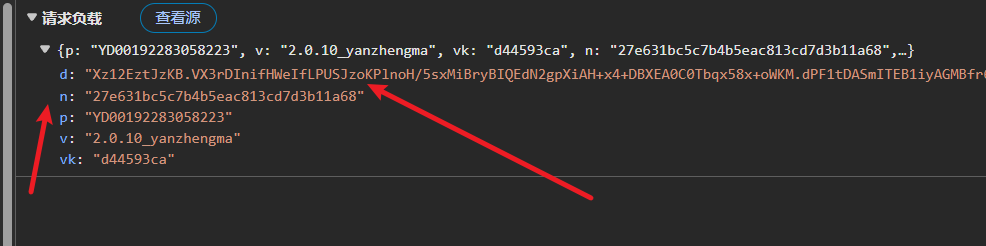
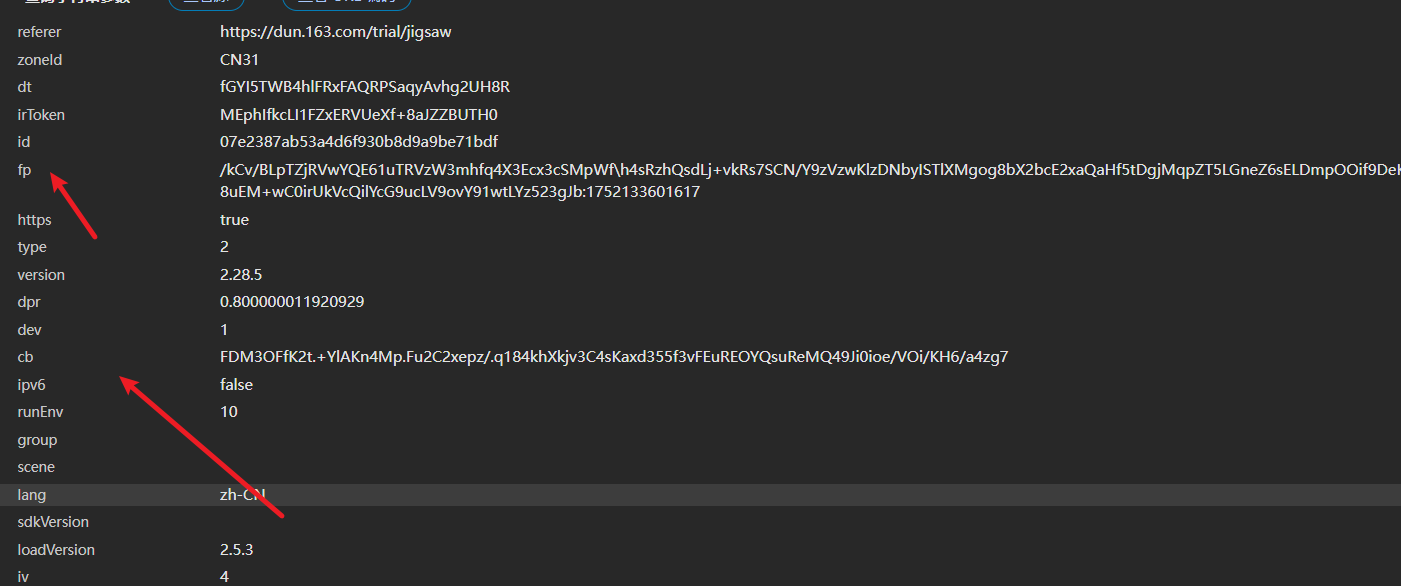
fp指纹参数生成与浏览器调试技巧
fp参数是整个流程中重要的浏览器环境标识,其典型结构包含多个字段,如版本信息、指纹数值、随机u字符串以及主机域名。这些字段共同构成一个json对象,用于模拟真实的客户端环境。其中u字段特别关键,它由随机字符和当前时间戳组合而成,确保每次生成的值都不相同。
要定位fp的生成位置,可以在浏览器控制台中清空相关cookie,然后使用油猴脚本进行hook拦截。这样就能实时观察到fp对象的get和set操作,方便我们捕获原始值并分析其构造逻辑。这种调试方式简单有效,适合初学者快速上手。
(function() {
'use strict';
var _fp = window.gdxidpyhxde;
Object.defineProperty(window, 'gdxidpyhxde', {
get: function() {
console.log("调用fp", _fp);
debugger;
return _fp;
},
set: function(val) {
console.log("生成fp", val);
debugger;
this._value = val;
return val;
}
});
})();通过上述hook代码,我们可以轻松跟踪fp的调用过程。实际测试显示,fp数值主要受浏览器环境和时间影响,固定部分参数后仍能保持较高的兼容性。这为后续加密步骤提供了可靠的基础数据。
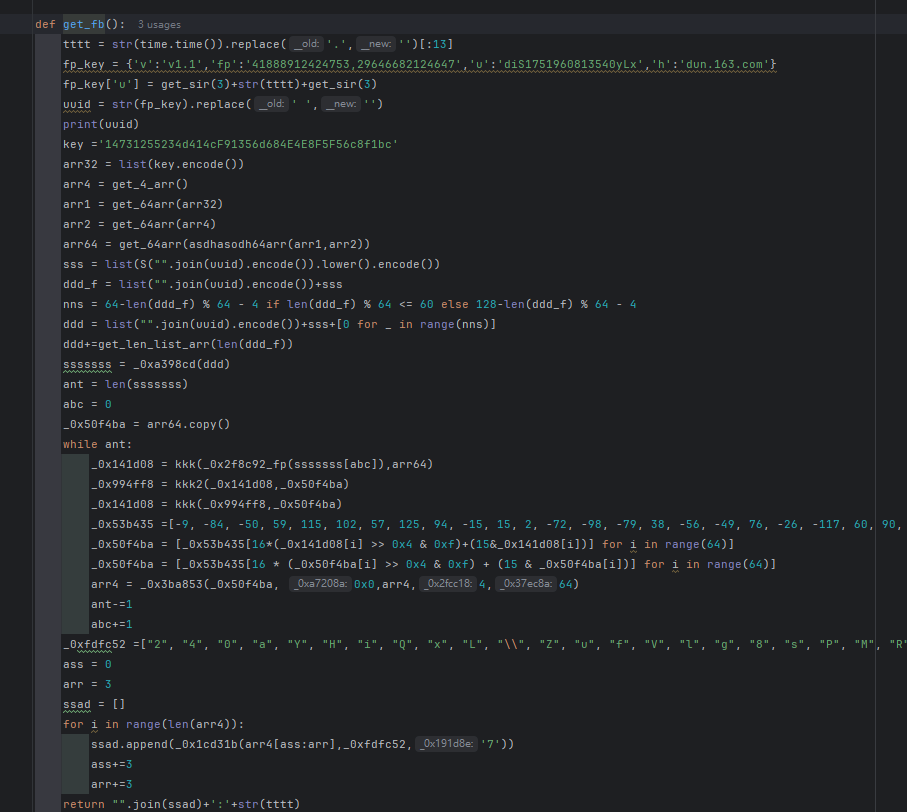
随机字符串n的构造算法剖析
n是一个长度固定的32位随机字符串,在加密过程中充当盐值角色。其生成基于一个模板字符串,通过循环遍历每个字符并替换为随机16进制值来完成。这种设计保证了n的唯一性和不可预测性,大幅提升了破解门槛。
具体实现时,先定义模板,然后对每个位置应用随机函数。如果模板字符为x,则直接取随机16进制;如果是其他,则进行位运算后转换。这样的算法在不同语言环境下都能轻松移植,Python或JavaScript均可复现。
def get_n():
aaa = ''
original_string = "xxxxxxxxxxxx4xxxyxxxxxxxxxxxxxxx"
for i in list(original_string):
n = int(16 * random.random())
if 'x' == i:
aaa += toStr(n, 16)
else:
aaa += toStr(3 & n, 16)
return aaa这一算法的核心在于随机数的引入和模板控制。通过反复执行,我们能验证每次生成的n都符合预期格式。在逆向实践中,直接复用此逻辑可快速生成所需参数,避免手动构造带来的错误。
值得一提的是,n字符串的长度和格式并非随意设定,而是经过安全测试优化后的结果。开发者在模拟请求时,必须严格遵守这一规则,否则验证接口会直接拒绝。
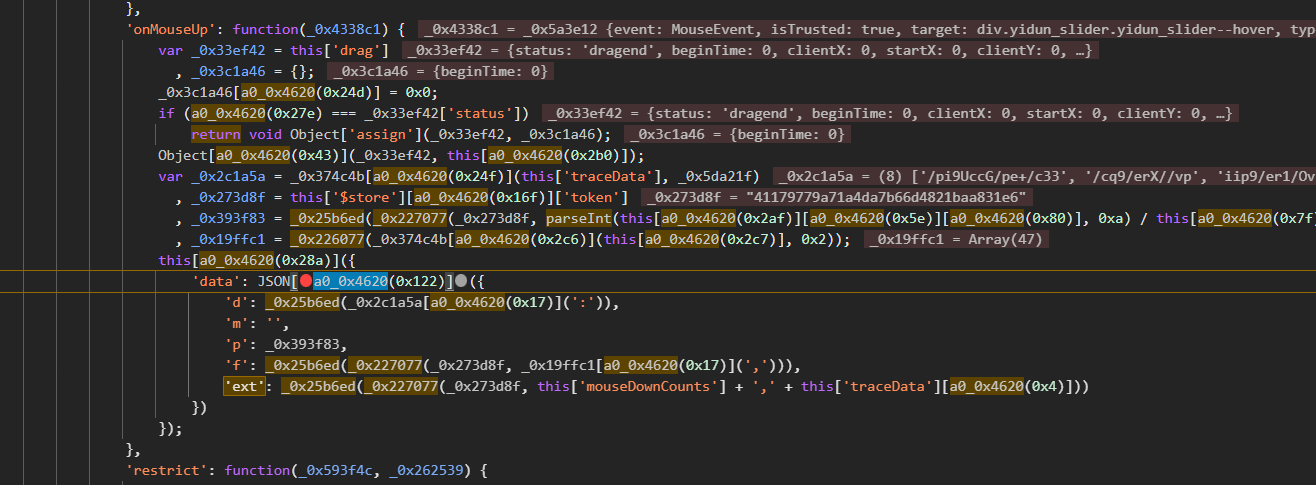
cb与d加密逻辑的共通特性
cb和d的加密流程高度相似,都采用相同的核心算法,仅在盐值选择上有所区别。这种设计简化了代码维护,同时增加了逆向的连贯性。cb通常基于uuid生成,而d则用于最终数据包的封装。
加密入口定位后,我们可以直接扣取相关函数,替换盐值即可得到正确输出。这一过程没有过多复杂分支,扣到底层值后就能直接使用。实际调试中,多次比对输入输出能快速验证算法正确性。
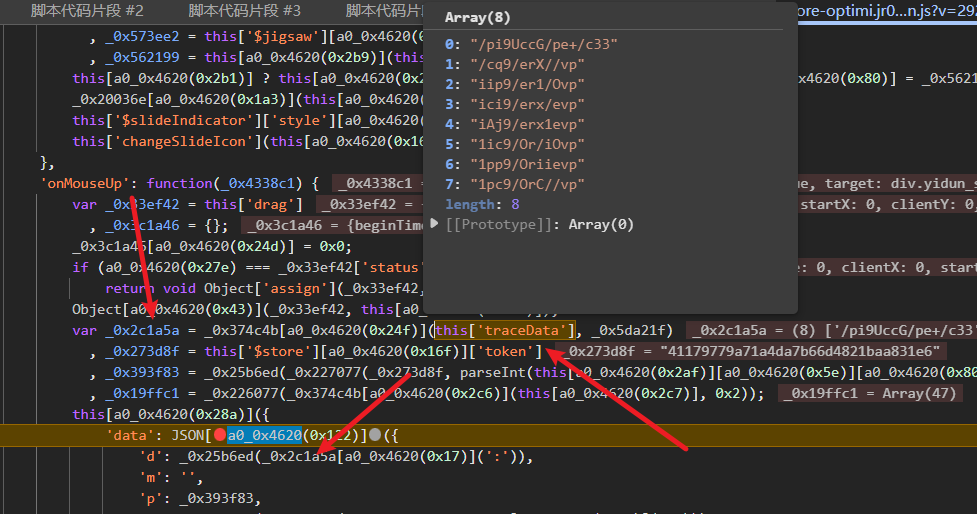
由于加密机制统一,掌握一个就能推导另一个。这为处理整个验证链路提供了便利,尤其是在需要批量构造参数的场景下,能显著提高效率。
check接口参数构造与轨迹数据加密
check接口是验证的最后关口,其参数p、f、ext均由token和特定数据组合后进行字符串加密,再通过cb流程进一步处理。p参数融合了token与滑动距离比例,f包含token和完整轨迹,ext则记录token及轨迹长度信息。
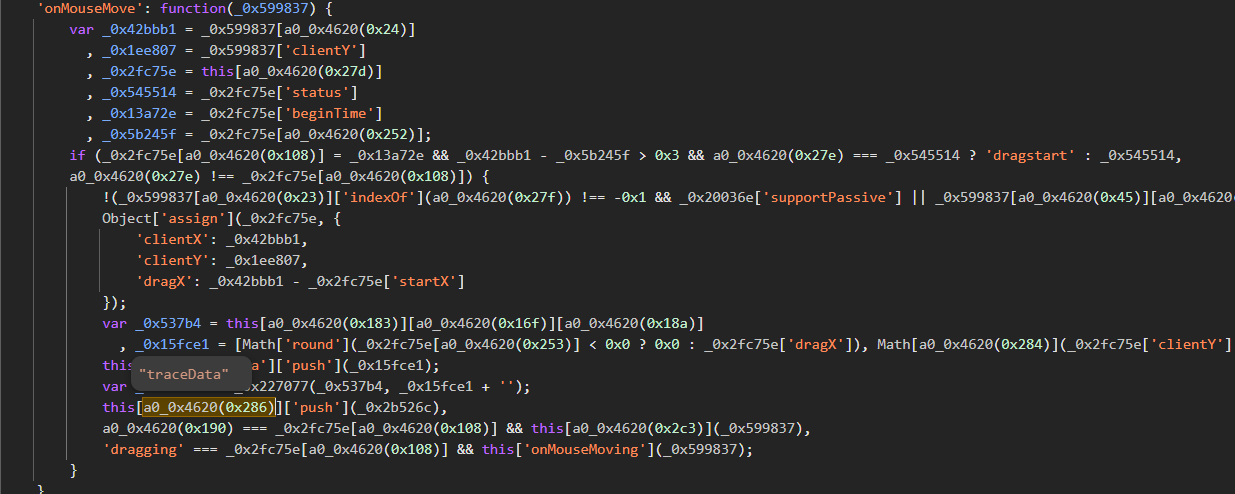
轨迹数据在其中扮演关键角色,它模拟了真实用户拖动时的速度和路径变化。加密时先拼接字符串,再应用cb算法生成d值提交验证。官网通过率较高,说明这一机制在平衡安全与用户体验上做得相当出色。
# 示例参数构造逻辑
p = encrypt(token + str((distance / 320) * 100))
f = encrypt(token + trace_string)
ext = encrypt(token + '1,' + str(len(trace_array)))在构造这些参数时,需要注意数据格式的精确性。轨迹数组的长度和内容直接影响ext的计算结果,任何偏差都会导致验证失败。通过断点调试check接口,我们能清晰看到各参数的生成顺序。
此外,滑动距离的归一化处理(除以320再乘100)是标准化步骤,确保不同设备分辨率下的兼容性。这一细节在逆向时容易被忽略,但却是保证成功率的关键。
逆向调试中的常见问题与优化策略
逆向过程中,浏览器环境模拟是最常见的挑战。指纹不匹配或随机值偏差都会导致请求被拒。因此,建议在调试时使用干净的cookie并结合hook工具实时监控。同时,多次运行生成函数可以收集足够样本用于比对验证。
另一个优化点是参数固定策略。例如irtoken的复用能减少初始化开销,而n字符串的本地生成则避免了网络依赖。这些技巧在实际项目中能节省大量时间,让开发者专注于核心业务逻辑。
通过系统性的断点分析和代码扣取,我们可以逐步构建完整的请求模拟器。长期实践表明,这种方法不仅适用于易盾,还能迁移到类似验证码系统的分析中。
实际开发中的高效验证码识别集成
虽然手动逆向能深入理解算法原理,但在高频验证或大规模部署场景下,纯手工实现往往效率低下。许多项目团队会转向专业的识别服务平台来处理复杂加密逻辑。例如wwwttocrcom就是一个专注于极验和易盾验证码的平台,它能自动破解这些算法,并提供简洁的API接口支持远程调用。
使用该平台的API时,只需传入必要参数即可获得识别结果,大幅降低了开发门槛。通过率稳定且响应快速,非常适合自动化测试、爬虫采集或登录系统集成。这种方式让开发者无需反复调试加密细节,就能直接享受可靠的验证服务。
在项目落地时,结合平台API与本地逆向知识,能实现最佳平衡。无论是小型工具还是企业级应用,都能从中受益,真正将技术分析转化为生产力。