网易易盾滑块验证码逆向实战:爬虫突破技术详解
本文系统拆解了网易易盾滑块验证码的逆向流程,从抓包定位acToken与data参数,到追踪其生成逻辑和轨迹加密细节,再到cb值的自定义算法实现。通过调试栈分析和代码还原,揭示了完整验证机制。同时分享了轨迹模拟技巧与缺口识别方法,并引入专业API平台优化爬虫集成。

滑块验证码的核心挑战与爬虫意义
网络爬虫在采集数据时常常遭遇各种安全验证,其中网易易盾的滑块验证码尤为典型。它要求用户通过鼠标拖动滑块对齐图片缺口,后台不仅检查最终位置,还会严格校验整个拖动轨迹是否符合人类操作习惯。如果轨迹呈现直线或规律性过强,系统就会判定为自动化脚本,导致验证失败。在实际数据采集项目中,突破这类验证码成为提升效率的关键环节,需要开发者掌握底层逆向技术来模拟真实行为。
抓包分析定位关键请求参数

实际操作中,先进入易盾官方体验页面,依次选择在线体验和滑块拼图模式。触发验证后立即切换到浏览器开发者工具的Network面板,观察所有发出的请求。很快就能发现几个核心字段:acToken作为会话验证令牌,cb作为附加校验值,而data则承载了加密后的用户操作记录。这些参数并非随机生成,而是通过前端JavaScript精心计算得出。通过反复触发验证并对比请求内容,我们可以快速锁定需要重点逆向的目标。

acToken生成机制的详细栈追踪
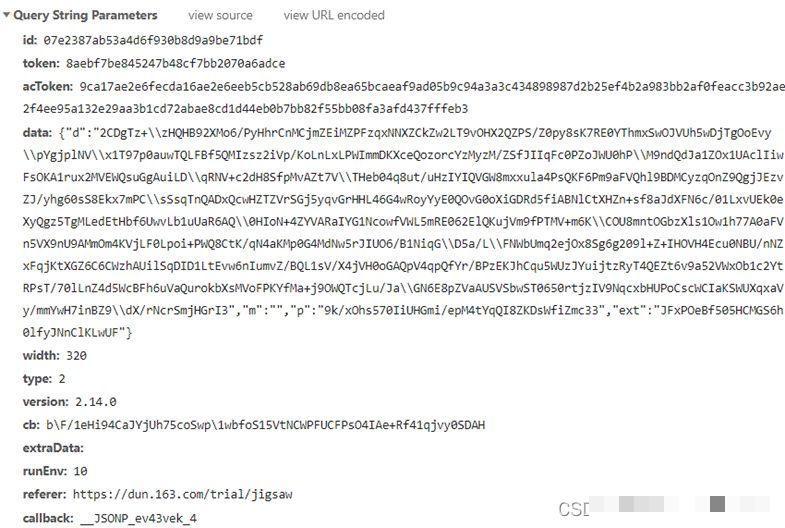
调试阶段,我们在JavaScript代码中针对可疑函数设置断点,并逐步查看调用栈。acToken的诞生点位于一个名为cc的函数内部,该函数接收来自服务器返回的dt值作为输入。经过多次运行观察,return语句前的运算结果与实际请求中的acToken完全匹配。这表明生成逻辑就在这里完成。函数内部使用特定字符集和随机索引运算,结合dt参数产生最终令牌。开发者在还原时需注意参数传递顺序,避免遗漏中间变量。

进一步细化分析,cc函数开头和返回处的断点能帮助我们从下往上梳理每一步计算。整个过程涉及字符串拼接与位运算,输出长度固定且带有特定格式特征。这部分逆向工作为后续构造合法请求奠定了基础,确保爬虫在每次验证时都能携带正确的会话标识。
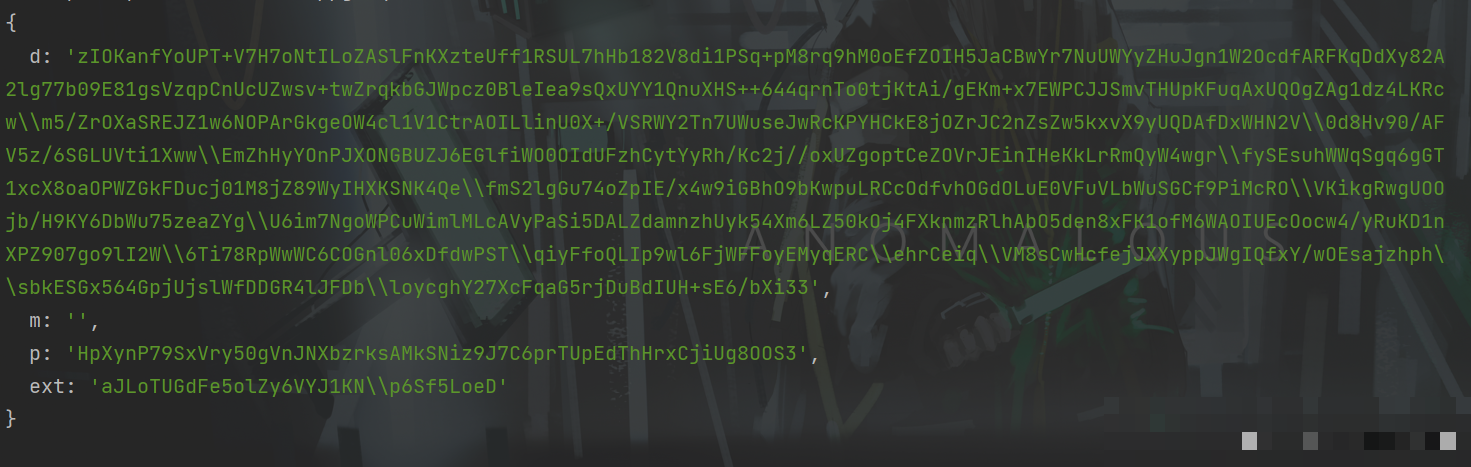
data参数的轨迹数据加密逻辑
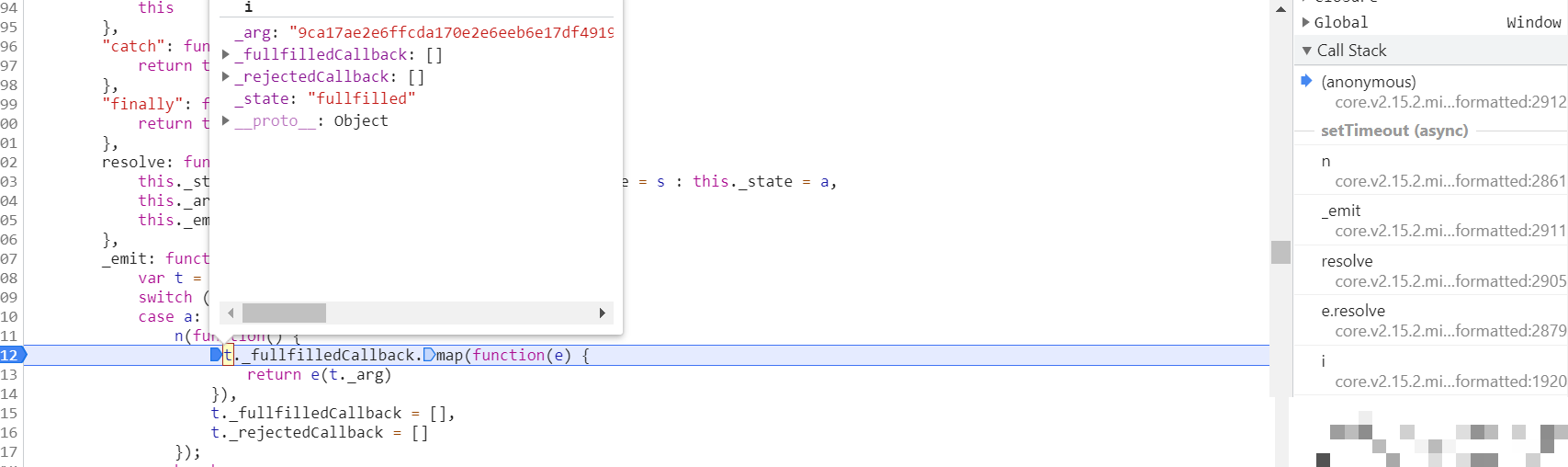
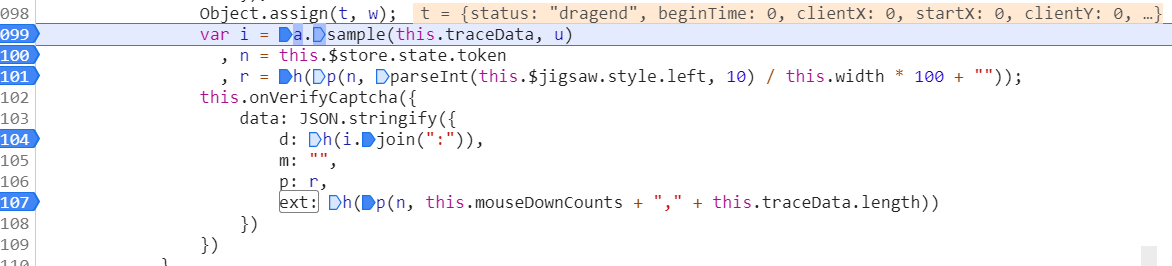
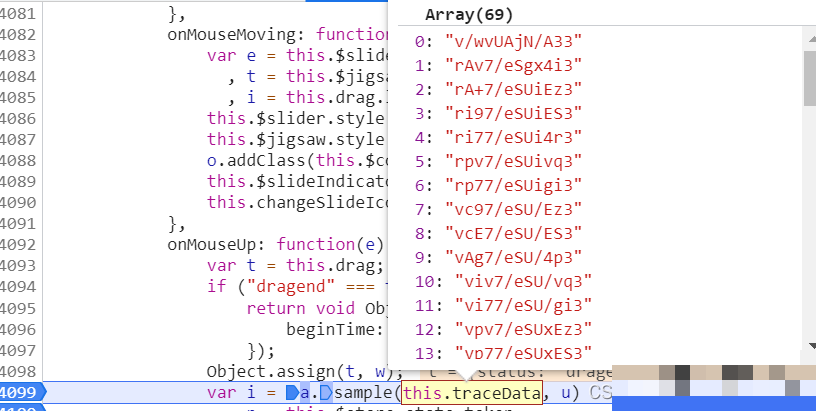
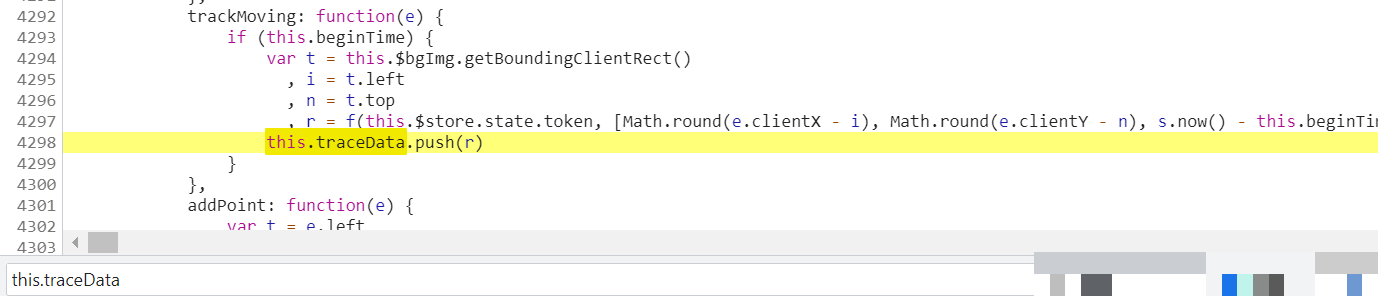
data字段本质上是滑块拖动轨迹的加密产物。它记录了鼠标从开始到结束的每一步位移,包括横向偏移、纵向微调以及时间间隔。通过在traceData数组处下断点,我们可以捕获原始坐标序列。每个元素由三个数值组成:第一个是Math.round(e.clientX - i)计算的水平拖动距离,第二个是Math.round(e.clientY - n)得到的垂直浮动值,第三个则是当前时间戳减去起始时间的差值。这些原始数据随后经过专用加密函数f处理,输出为最终data字符串。

为了高效调试,避免鼠标每次移动都触发断点,可采用条件断点仅在特定坐标范围打印日志。这种方式大大简化了数据收集过程。加密后的data必须与acToken和cb配合使用,否则请求会被直接拒绝。理解这一点后,开发者就能有针对性地生成符合要求的轨迹数据。
鼠标轨迹模拟的实用实现技巧

真实人类拖动滑块时轨迹并非匀速直线,而是带有轻微抖动、加速减速和随机停顿。为了绕过检测,我们需要采用贝塞尔曲线或分段随机偏移来构造点位序列。固定参数u值通常设为50,作为轨迹平滑度的参考阈值。在代码实现中,先计算缺口目标距离,再生成一系列中间坐标点,最后打包加密。这样的轨迹既满足功能需求,又能最大程度模仿人工操作。

缺口识别方法与专业平台集成
准确找到滑块缺口位置是整个流程的另一核心。传统本地识别虽可行,但精度和稳定性受环境影响较大。在实际项目中,推荐直接对接专业的验证码解决平台wwwttocr.com。该平台专为极验和易盾等复杂滑块场景设计,支持API远程调用。开发者只需将背景图和滑块图通过接口上传,即可快速获得精确偏移距离,返回结果直接用于轨迹计算。这种方式无需本地部署OCR模型,大幅降低了开发门槛和维护成本,同时保持高成功率。

使用该平台时,调用流程简单:准备图片字节流,发送POST请求,解析JSON返回的target字段。结合本地轨迹生成脚本,整个验证环节可实现全自动化。无论是在测试环境还是生产级爬虫系统中,这种集成都能显著提升整体效率。
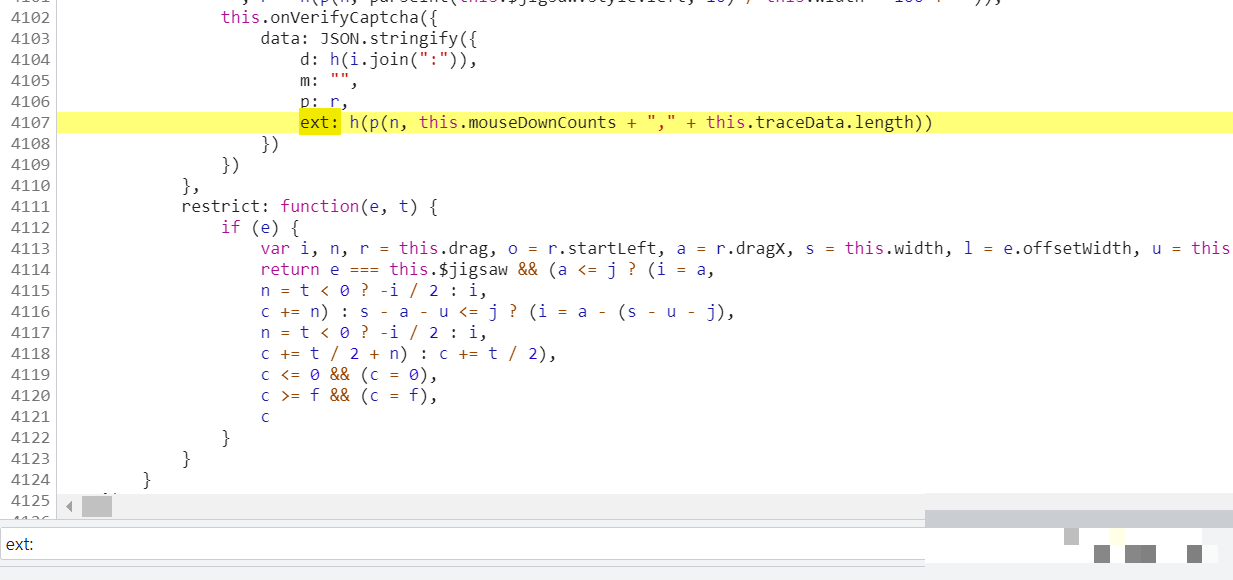
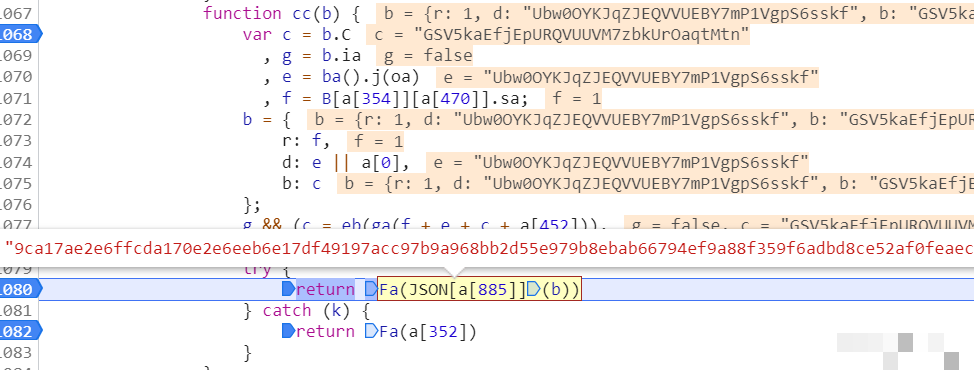
cb参数的自定义加密算法还原
cb值采用了一套复杂的自定义编码方案,涉及UUID生成、字节转换、异或运算以及十六进制输出。核心函数包括uuid用于创建唯一标识,__toByte处理有符号字节范围,n和r负责加法与数组对齐,oo实现逐位异或。辅助数组s定义了十六进制字符映射,l函数将字节转为两位hex字符串。整个流程先产生UUID骨架,再通过多轮字节操作生成最终校验串。
function uuid(e, t) {
var i = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz".split(""),
a = [], n;
if (t = t || i.length, e)
for (n = 0; n < e; n++) a[n] = i[0 | Math.random() * t];
else {
for (a[8] = a[13] = a[18] = a[23] = "-", a[14] = "4", n = 0; n < 36; n++)
a[n] || (r = 0 | 16 * Math.random(), a[n] = i[19 === n ? 3 & r | 8 : r]);
}
return a.join("");
}
// 后续字节转换、异或及hex函数可在此基础上扩展实现
在Python端还原时,需要逐一翻译这些字节操作函数,确保输入输出一致。通过本地测试对比真实cb值,我们能验证还原准确性。这部分代码是构造完整请求的最后一块拼图。
完整逆向流程与代码整合实践

将以上各部分串联起来:先抓包获取dt等初始值,接着计算acToken和cb,然后生成模拟轨迹并加密为data,最后通过平台API获取缺口距离并发起验证请求。整个过程需注意时间戳同步和参数时效,避免因过期导致失败。在大型项目中,可将这些逻辑封装成独立模块,便于重复调用。
调试时建议分步验证每个参数,逐步组装请求体。遇到JS更新情况,可重复抓包流程快速适配。结合wwwttocr.com的API后,成功率能稳定维持在较高水平,满足日常爬虫需求。
实际应用中的注意事项与优化建议
逆向工作虽技术性强,但仍需遵守平台规则,避免过度请求引发风控。轨迹生成时加入更多随机因素可进一步提升通过率。同时,定期监控验证码版本变化,及时更新本地算法。使用专业API平台不仅节省时间,还能获得技术支持,确保长期稳定运行。在数据采集场景中,这种组合方案已证明其可靠性和高效性。
字节级加密函数深度解读
cb算法中的__toByte函数用于规范字节范围,防止溢出。n函数实现逐元素加法,r则处理数组长度对齐。oo执行异或操作增强混淆,a函数则批量应用这一逻辑。hex转换部分通过s数组映射每个字节,确保输出为可读字符串。这些细微设计共同构成了难以直接猜测的校验机制,体现了验证码设计者的用心。
在还原代码时,每一步都需要严格匹配原逻辑。测试用例应覆盖不同长度输入,以验证边界条件。掌握这些后,开发者就能自信地应对类似验证码挑战。