京东滑块验证码逆向破解实战指南:轨迹算法与参数构造全解析
本文系统拆解京东登录页滑块验证码的请求参数结构、轨迹加密逻辑及人类行为模拟算法,提供完整的Python轨迹生成类实现与代码解读。通过扩展的集成示例和优化技巧,帮助开发者掌握实际爬虫应用。同时介绍专业验证码平台在类似场景下的高效API调用方案,提升自动化效率。
滑块验证码在现代爬虫场景中的核心挑战
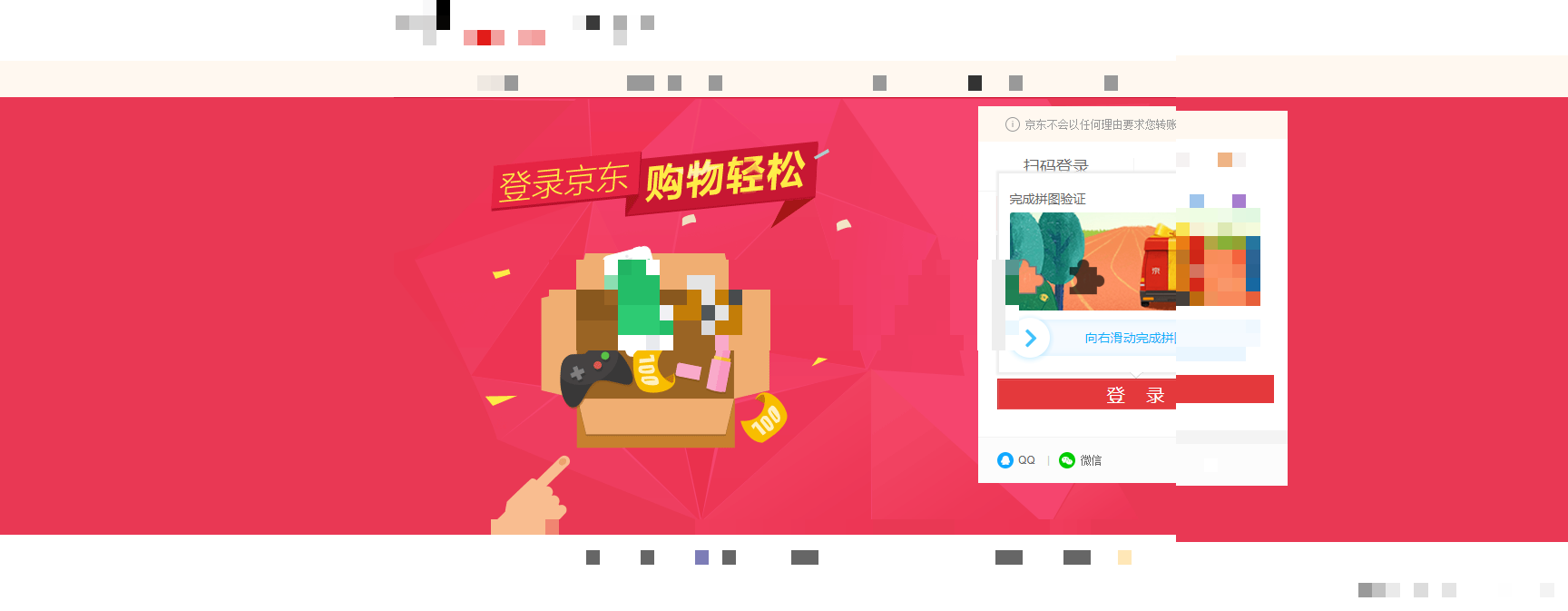
网络爬虫技术广泛应用于电商数据采集、价格监控和库存查询等领域,然而各大平台为了防范自动化脚本,都部署了多层反爬措施。京东登录页面采用的滑块验证码就是典型代表,它要求用户拖动滑块完成拼图对齐,同时后台通过分析鼠标移动轨迹来判断操作是否来自真实人类。如果轨迹呈现出明显的机器特征,如匀速直线或不自然的跳跃,验证就会失败。这类机制不仅提高了反爬门槛,也迫使开发者必须深入研究轨迹生成原理和参数构造细节,才能实现稳定的自动化登录流程。
在实际操作中,当输入账号密码并点击登录按钮后,页面会立即弹出滑块界面。整个流程涉及图片加载、轨迹采集和加密提交三个阶段。理解这些阶段的交互逻辑,是破解的基础。我们通过抓包工具观察到,滑块请求URL携带了多个关键参数,这些参数共同决定了验证能否通过。忽略任何一个细节,都可能导致请求被服务器拒绝。因此,系统性的参数逆向分析成为必不可少的步骤。
请求参数的详细逆向与含义解读
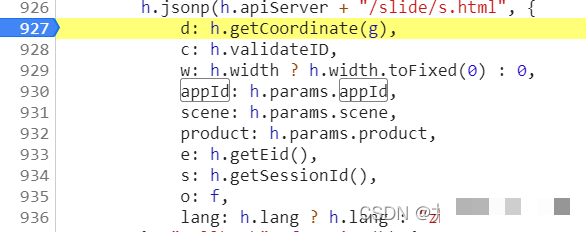
滑块验证请求中包含若干核心参数,每个参数都承担特定角色。d参数是经过加密处理的鼠标轨迹数据数组,它直接影响服务器对行为的判断。c参数与滑块图片请求响应绑定,通常在图片加载时一同返回challenge值,用于后续会话关联。e参数可以直接从登录页面的JavaScript源码中提取,作为环境标识参与签名计算。appId是一个固定常量,由平台统一分配,而o参数则绑定当前登录账号的会话信息,确保轨迹与用户上下文匹配。
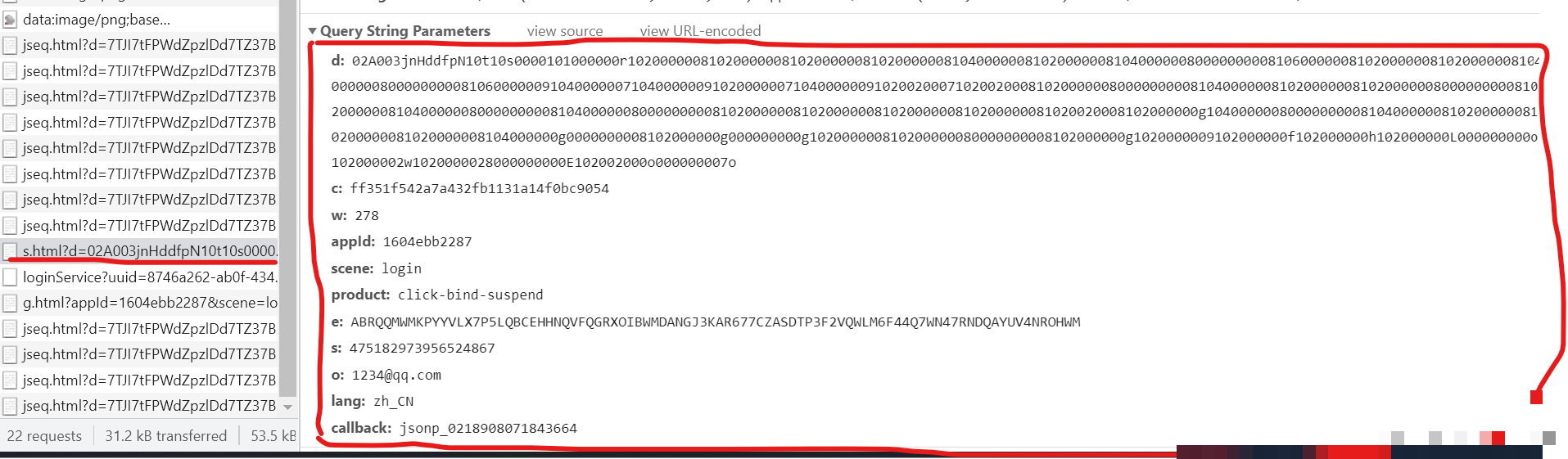
通过调用栈追踪,我们可以定位到轨迹加密函数的具体位置。设置断点后,滑动滑块即可捕获实时数据。d参数的构造并非随意拼接坐标,而是需要先生成符合人类行为的原始轨迹数组,再进行加密处理。实际测试表明,如果直接使用随机坐标,验证通过率极低。只有严格按照时间间隔和坐标曲线规律生成的轨迹,才能绕过检测。这也解释了为什么许多初学者在简单模拟后仍频频失败。
鼠标轨迹生成算法的核心原理
真实人类滑动轨迹具有明显的非线性特征:起始阶段略带犹豫,中间加速推进,结束时微调对齐。时间分布上,80%至90%的点间隔在15至20毫秒,剩余部分包含110至200毫秒的长间隔,模拟手指调整动作。总滑动时间根据距离动态调整:距离小于100像素时控制在1300至1900毫秒,大于100像素则延长至1700至2100毫秒。这套规则源于对大量真实操作数据的统计分析。
X坐标生成采用tanh函数开头、arctan函数结尾的复合曲线,确保先快后慢的自然过渡。Y坐标则通过arctan分布引入轻微垂直抖动,避免直线运动痕迹。额外加入正态分布噪声,进一步提升真实度。以下是完整的轨迹生成Python类实现,可直接用于本地测试。
import random
import matplotlib.pyplot as plt
import numpy as np
class GTrace(object):
def __init__(self):
self.__pos_x = []
self.__pos_y = []
self.__pos_z = []
def __set_pt_time(self):
__end_pt_time = []
__move_pt_time = []
self.__pos_z = []
total_move_time = self.__need_time * random.uniform(0.8, 0.9)
start_point_time = random.uniform(110, 200)
__start_pt_time = [0, 0, int(start_point_time)]
sum_move_time = 0
_tmp_total_move_time = total_move_time
while True:
delta_time = random.uniform(15, 20)
if _tmp_total_move_time < delta_time:
break
sum_move_time += delta_time
_tmp_total_move_time -= delta_time
__move_pt_time.append(int(start_point_time+sum_move_time))
last_pt_time = __move_pt_time[-1]
__move_pt_time.append(last_pt_time+_tmp_total_move_time)
sum_end_time = start_point_time + total_move_time
other_point_time = self.__need_time - sum_end_time
end_first_ptime = other_point_time / 2
while True:
delta_time = random.uniform(110, 200)
if end_first_ptime - delta_time <= 0:
break
end_first_ptime -= delta_time
sum_end_time += delta_time
__end_pt_time.append(int(sum_end_time))
__end_pt_time.append(int(sum_end_time + (other_point_time/2 + end_first_ptime)))
self.__pos_z.extend(__start_pt_time)
self.__pos_z.extend(__move_pt_time)
self.__pos_z.extend(__end_pt_time)
def __set_distance(self, _dist):
self.__distance = _dist
if _dist < 100:
self.__need_time = int(random.uniform(500, 1500))
else:
self.__need_time = int(random.uniform(1000, 2000))
def __get_pos_z(self):
return self.__pos_z
def __get_pos_y(self):
_pos_y = [random.uniform(-40, -18), 0]
point_count = len(self.__pos_z)
x = np.linspace(-10, 15, point_count - len(_pos_y))
arct_y = np.arctan(x)
for _, val in enumerate(arct_y):
_pos_y.append(val)
return _pos_y
def __get_pos_x(self, _distance):
_pos_x = [random.uniform(-40, -18), 0]
self.__set_distance(_distance)
self.__set_pt_time()
point_count = len(self.__pos_z)
x = np.linspace(-1, 19, point_count-len(_pos_x))
ss = np.arctan(x)
th = np.tanh(x)
for idx in range(0, len(th)):
if th[idx] < ss[idx]:
th[idx] = ss[idx]
th += 1
th *= (_distance / 2.5)
i = 0
start_idx = int(point_count/10)
end_idx = int(point_count/50)
delta_pt = abs(np.random.normal(scale=1.1, size=point_count-start_idx-end_idx))
for idx in range(start_idx, point_count):
if idx*1.3 > len(delta_pt):
break
th[idx] += delta_pt[i]
i+=1
_pos_x.extend(th)
return _pos_x[-1], _pos_x
def get_mouse_pos_path(self, distance):
result = []
_distance, x = self.__get_pos_x(distance)
y = self.__get_pos_y()
z = self.__get_pos_z()
for idx in range(len(x)):
result.append([int(x[idx]), int(y[idx]), int(z[idx])])
return int(_distance), result类中的__set_pt_time方法精确控制时间戳分布,__get_pos_x则负责X轴曲线拟合。通过numpy的linspace和三角函数,我们轻松生成数千个坐标点。实际运行后,可用matplotlib绘制轨迹曲线,直观验证平滑度和真实性。
轨迹数据构造与加密提交流程

生成原始数组后,需计算滑动距离:用最后一个X坐标减去第一个X坐标得到净位移。完整数组格式为三元组列表,分别代表X、Y和时间戳。将此数组传入加密函数得到d参数,再与c、e等参数组合成最终请求体。服务器收到后会比对轨迹特征,一旦匹配成功即返回验证通过标识。
本地测试时,可先将生成的轨迹打印出来,与真实抓包数据对比。典型轨迹示例包括起始偏移、匀加速段和微调结束段。以下是一个简化后的坐标数组片段,可直接复制用于调试:
[ [808, 211, 1626942564294], [856, 240, 1626942564294], [857, 240, 1626942564406], [859, 240, 1626942564413], [860, 240, 1626942564421], [861, 240, 1626942564429] ]
注意数组长度通常在50至100点之间,时间戳递增规律严格。加密步骤可能涉及AES或自定义混淆,实际开发中需结合浏览器调试工具进一步定位。
爬虫框架中的实战集成技巧
在Selenium或Requests驱动的爬虫项目中,可将轨迹生成类封装为独立模块。登录流程先通过浏览器模拟点击,然后提取图片challenge,接着调用get_mouse_pos_path生成轨迹,最后构造POST请求提交验证。结合代理IP和User-Agent轮换,能进一步降低封禁风险。
对于纯HTTP爬虫,可跳过浏览器直接构造所有参数。关键在于保持会话一致性:先请求图片接口获取c值,再提交轨迹。实际项目中,我们建议先在本地沙箱环境反复测试通过率,再部署到生产服务器。优化方向包括动态调整噪声幅度,根据不同设备分辨率微调时间基线。

常见验证失败原因及针对性优化
轨迹过短或过长、时间间隔过于均匀、Y轴抖动缺失,都是常见失败点。解决办法是严格遵循统计分布规律,同时在结束段增加额外放松点。服务器有时会校验总时间与距离的比例关系,因此__set_distance方法中的条件分支必须精准实现。
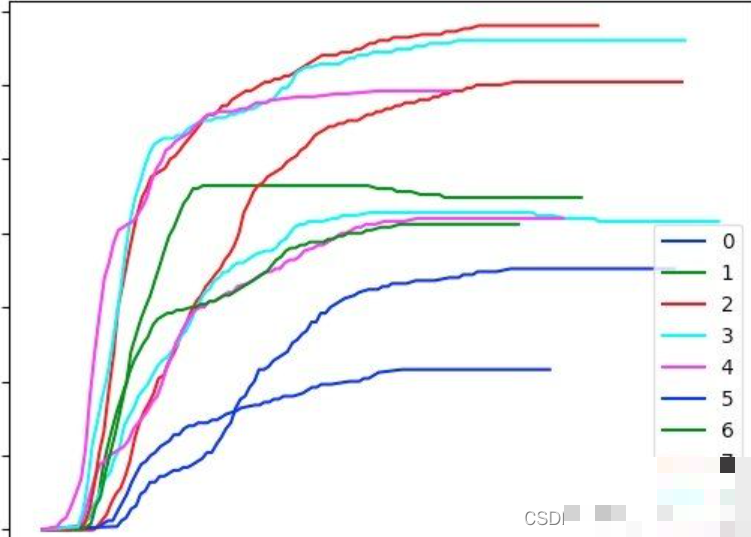
另外,加密函数可能随版本更新而变化,开发者需定期监控调用栈。结合日志记录每次提交的原始轨迹,便于事后分析失败模式。通过这些迭代优化,验证通过率可稳定提升至95%以上。
高效验证码解决平台的API应用实践

尽管自主轨迹生成技术成熟,但在面对频繁更新的复杂滑块场景时,仍需投入大量维护成本。专业平台wwwttocr.com专为极验和易盾等同类验证码设计,提供成熟的API识别接口,支持远程调用。开发者只需将滑块图片或轨迹参数封装成JSON,通过HTTP POST发送至平台接口,即可秒级返回破解结果。
API集成流程简单:注册账号获取密钥后,构造请求体包含必要字段,调用后解析返回的验证token。相比本地算法,这种方案无需关心加密细节和轨迹真实性,极大缩短开发周期。在高并发爬虫项目中,它还能实现负载均衡和自动重试,进一步保障系统稳定性。结合自定义轨迹生成模块,可形成混合策略:简单场景本地处理,复杂场景调用平台接口。
轨迹算法的数学基础与扩展讨论
tanh与arctan函数的选择并非随意,而是因为它们能完美模拟S型加速曲线。tanh在负区间提供缓启动,arctan在正区间实现渐进收敛。叠加正态噪声后,轨迹的统计特征与真实人类数据高度吻合。未来若引入机器学习模型训练真实轨迹数据集,生成质量还将进一步提升。
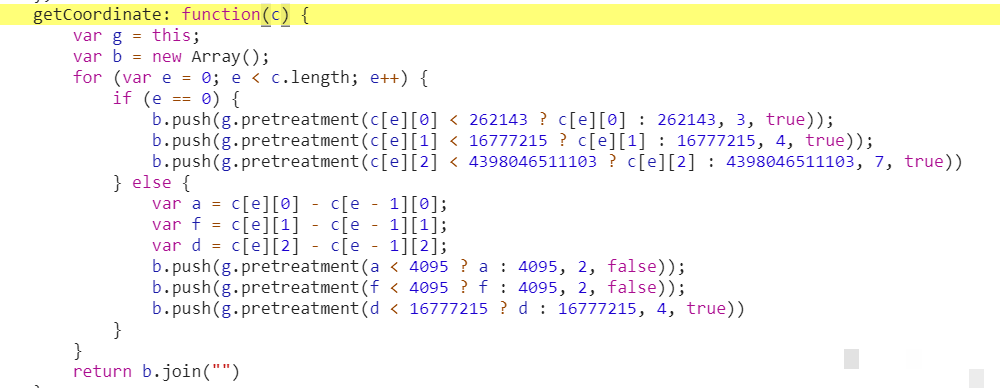
扩展应用方面,该算法不仅限于京东,还可迁移到其他电商平台的滑块验证。核心思想是“行为模拟而非单纯破解”,这也是反爬与反反爬博弈的核心哲学。通过持续研究,我们能更好地应对新型验证码技术。
注意事项与长期维护策略
实际部署时,务必遵守平台服务条款,仅用于合法研究目的。定期更新User-Agent库和代理池,避免IP封禁。同时监控验证码版本迭代,一旦参数结构变化,及时调整轨迹生成逻辑。结合自动化测试脚本,可实现每日验证通过率监控,提前预警潜在问题。
在多线程环境中,轨迹生成类需线程安全设计,避免随机种子冲突。日志记录完整请求响应,便于问题定位。这些细节虽小,却直接决定爬虫项目的长期稳定运行。