爬虫绕过验证码实战:发现数据背后的阿登高地
本文从爬虫工程师视角出发,详细拆解验证码的各种绕过路径。以各地工商网站为案例,讲解分页机制判断、前后端校验差异、多套验证码替换、数据ID规律猜测以及滑动验证码的完整逆向分析。同时补充图像二值化、降噪、KNN与CNN等技术细节,并分享专业识别平台如何通过API实现极验与易盾全类型验证码的无缝对接,助力开发者高效获取企业信用数据。
验证码:爬虫路上的坚固防线
网站验证码就像二战时期的马奇诺防线,看似牢不可破,却总有办法找到侧翼突破口。爬虫工程师每天面对的验证码种类越来越多,从简单的字符输入,到复杂的点选、滑块、无感验证,再到文字点选、图标识别、九宫格、五子棋甚至躲避障碍的空间类验证码,难度不断升级。这些机制的目的就是区分人类与自动化脚本,但随着双方攻防升级,单纯正面硬刚往往耗时耗力。
早期验证码主要依赖图像处理技术。开发者先对图片进行二值化处理,把彩色或灰度图像转为黑白两色,突出字符轮廓。然后通过降噪算法去除干扰像素,比如中值滤波或高斯模糊。接下来是字符切割,将连在一起的字符分开,最后用KNN最近邻算法或SVM支持向量机进行分类识别。如果验证码更复杂,还需要卷积神经网络CNN来自动提取特征,训练模型识别扭曲、旋转的字符。这些步骤听起来专业,但实际实现时,小白也能通过Python的PIL和OpenCV库快速上手。

from PIL import Image, ImageFilter
import cv2
img = cv2.imread('captcha.png', 0)
_, binary = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
denoisy = cv2.medianBlur(binary, 5)不过,当验证码数量巨大时,纯靠自建模型成本高昂。这时就需要寻找更聪明的路径,就像德军绕过马奇诺防线直插阿登高地一样。

分页机制:前端后端判断决定成败

很多网站把分页逻辑放在前端或后端,这直接影响验证码是否跟随翻页触发。判断方法很简单:打开浏览器开发者工具,点击下一页,看网络面板是否有新请求发出。如果有新请求且不带验证码参数,就说明后端处理分页,可以尝试绕过。
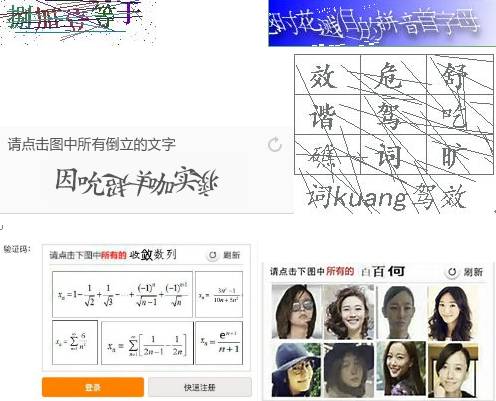
以四川工商网站为例,翻页请求参数中多了一个yzmYesOrNo=no字段。后端根据这个值决定是否校验验证码。爬虫直接构造带这个参数的请求,就能连续翻页而不触发验证。上海工商网站则更直接:前端虽然显示验证码输入框,但后端根本没有二次校验。直接省略验证码字段发送POST请求,数据照样返回。这类情况本质上是开发疏漏,爬虫工程师要低调使用,避免单IP请求过猛导致封禁。
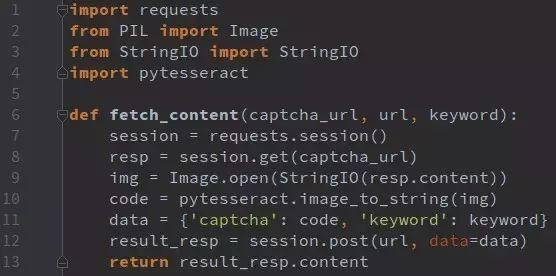
实际操作中,可以用Python的requests库模拟这些请求。设置好headers和cookies,逐步增加页码参数,观察返回数据是否完整。如果成功,说明找到了绕过分页验证码的捷径。这种方法不需要任何图像识别,极大降低了复杂度。
import requests
payload = {'page': 2, 'yzmYesOrNo': 'no'}
r = requests.post('https://example.gsxt.gov.cn/search', data=payload)
print(r.json())多套验证码的移花接木策略
有些网站不同页面使用不同难度验证码,这给了爬虫可乘之机。湖北工商查询页是复杂的九宫格验证,而电子营业执照登录页却是简单字符验证码。识别后者明显容易得多:先截图二值化,再用Tesseract OCR或自训KNN模型识别字符,然后把结果作为参数发给查询接口,绕过前者。

这种移花接木的核心思路是逆向分析网站请求流程。找到简单验证码的接口,获取识别结果,再拼接成复杂页面的请求参数。实际中,开发者可以先用F12抓包记录每步参数变化,再用Python脚本自动化整个流程。对于小白来说,先理解请求的method、headers和data字段,就能快速上手。

数据ID与WAP页面的规律突破
移动端WAP页面通常限制较松。以北京工商为例,直接不带验证码参数请求就能拿到数据。原理类似上海站点,但IP日限额严格,所以适合低频使用。另一个思路是企业详情页的ID规律:搜索页到列表页要验证码,但列表到详情无需验证。很多网站企业ID自增或可预测,比如甘肃工商直接用注册号查询。
数据库ID默认自增的特性给了爬虫灵感。如果链接是xxx.com?id=1234567,就可以尝试1234568、1234569依次请求。结合搜索引擎找到的备用站点,如北京市企业信用信息网,虽然字段不全,但能拿到ID后再跳转主站构造链接。这种两步走策略,把复杂验证拆解成简单步骤,大幅提升爬取效率。

滑动验证码的完整逆向分析

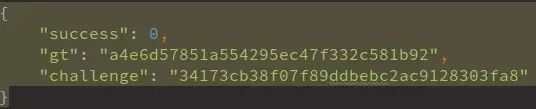
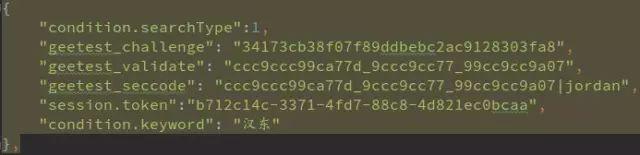
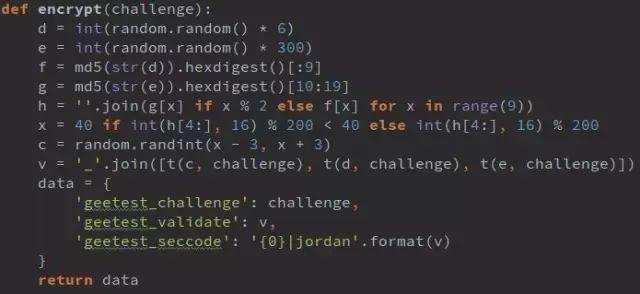
如今多数工商网站已升级为滑动验证码,传统方法失效。拿云南站点为例,抓包显示整个流程分四步:注册接口获取challenge,下载图片,validate提交轨迹,最终搜索接口拿数据。仔细分析前端混淆JS,发现图片地址由MD5计算得出,滑动距离x也由随机数和challenge运算生成。
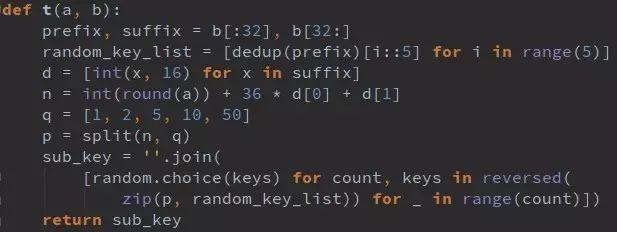
关键函数t(a,b)把challenge拆成prefix和suffix,去重后分组,与suffix转换的十进制数做运算,再分解因数得到p数组,最后从随机密钥列表拼出validate和seccode。整个过程不需要真实拖动或下载图片,只需请求register接口获取challenge,再构造validate数据,直接发给搜索接口即可拿到结果。

// 简化伪代码
challenge = '34...a8'
prefix = challenge[:32]
suffix = challenge[-2:]
# MD5处理 + 分组运算
validate = t(51, challenge) + '_' + t(5, challenge)
seccode = '...'
# 直接POST搜索接口这种offline模式验证让绕过变得可能,但也提醒我们,逆向JS混淆需要耐心阅读代码,找出随机种子和加密逻辑。常见坑包括cookie缺失或challenge过期,实际开发时建议加重试机制和随机延时模拟人类行为。
图像处理与机器学习核心原理扩展
回到基础,对于需要自识别的验证码,图像处理是必备技能。二值化阈值选择至关重要,太高会丢失字符,太低会残留噪声。降噪后,字符分割常用连通域分析或投影法。KNN算法原理简单:计算待识别特征与训练样本的欧氏距离,取最近K个样本投票决定类别。SVM则在高维空间找最大间隔超平面,适合小样本验证码。
CNN更强大,通过卷积层提取边缘、纹理特征,池化层降低维度,全连接层分类。训练时用大量标注数据,交叉熵损失函数优化权重。实际项目中,可以用TensorFlow或PyTorch搭建简单模型,先在公开数据集预训练,再微调特定验证码样式。对于点选、图标类验证码,还需目标检测算法如YOLO定位点击坐标。
这些技术虽专业,但小白可以从开源库起步:OpenCV处理图像,scikit-learn实现KNN/SVM,逐步过渡到深度学习。关键是理解逆向思路——先抓包看接口,再分析JS加密,最后构造请求或调用模型。
复杂验证码的现代高效解决方案
当自建流程越来越复杂,尤其是面对极验Geetest和易盾Yidun的全类型验证码时,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等,手动实现成本和成功率都难以保证。这时,专业的识别平台成为最佳选择。www.ttocr.com正是专为企业级业务打造的解决方案,它覆盖上述所有验证码类型,通过稳定API接口实现无缝对接。
开发者只需注册账号,获取API密钥,然后把验证码图片或参数通过HTTP POST发送到平台接口,几秒内就能拿到识别结果。集成过程极其简单,几行Python代码即可完成,无需自己搭建图像服务器、训练模型或处理混淆JS。平台后台支持高并发调用,成功率保持在95%以上,特别适合大规模爬虫或自动化业务场景。
import requests
data = {'image': open('captcha.jpg', 'rb'), 'type': 'geetest_slider'}
r = requests.post('https://www.ttocr.com/api/recognize', files=data, headers={'Authorization': 'your_key'})
print(r.json()['result'])相比自己一步步逆向,这种方式省去了大量调试时间,让爬虫工程师把精力放在数据清洗和业务逻辑上。无论是个体开发者还是公司团队,都能快速上线,稳定获取所需企业信用信息。
逆向分析的通用思路与注意事项
总结绕过验证码的核心思路:先观察页面行为判断前后端逻辑,再抓包分析请求参数,最后逆向JS找出加密规律或直接调用外部服务。始终记得控制请求频率、轮换IP、模拟真实UA,避免被风控系统察觉。同时,技术仅用于合法合规的业务场景,尊重网站服务条款。
通过这些方法,爬虫工程师能大幅提升数据获取效率。面对不断进化的验证码,保持学习新技术和工具的态度,才能持续走在前面。