爬虫工程师破解验证码的隐秘路径:阿登高地突破指南
本文以工商网站为例,详细介绍了绕过验证码的多种实战策略,包括分页前后端差异、多验证码切换、数据ID规律挖掘以及滑动验证码的JS逆向分析。同时深入讲解图像处理基础与KNN、SVM、CNN等识别原理,提供从原理到操作的实用思路,并分享专业API平台如何帮助企业简单高效对接复杂验证码任务。

验证码:爬虫路上的坚固防线与历史启示
网络爬虫技术在数据采集领域发挥着重要作用,但网站为了保护数据安全,往往部署验证码作为最后一道屏障。这些验证码系统设计精巧,旨在区分人类用户与自动化脚本,就像二战时期法国耗时多年修建的马奇诺防线,看似牢不可破,却留下了可被利用的薄弱环节。爬虫工程师如果一味正面硬碰,不仅耗费大量时间,还可能面临IP封禁等风险。因此,寻找类似阿登高地的迂回路径,成为绕过验证码的关键思路。
随着反爬虫技术的不断升级,验证码形式也越来越多样化。从早期的简单数字字母组合,到如今的滑动拼图、点选图形、九宫格甚至动态障碍躲避,难度层层递增。各地工商网站因为包含企业信用信息、注册数据等高价值内容,成为爬虫攻击的重点目标。这些网站通常无需登录即可查询,但每一次关键字搜索或翻页都会触发验证码校验,且不同省份的实现机制各不相同,这为我们提供了丰富的分析样本。

图像处理基础:让机器看懂验证码图片

识别验证码的第一步通常是图像预处理。二值化操作是将彩色或灰度图像转换为仅黑白两色的形式,通过设定一个阈值,将像素值高于阈值的设为白色,低于的设为黑色。这一步能有效去除背景干扰,让字符轮廓更加清晰。在实际代码实现中,可以使用OpenCV库的threshold函数,阈值选择需根据图片亮度动态调整,避免过度黑化导致字符断裂。
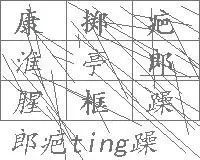
接下来是降噪处理。验证码图片往往带有干扰线、噪点或模糊效果,中值滤波或高斯滤波是常用方法。中值滤波通过取邻域像素的中值替换当前像素,能有效去除孤立噪点而保留边缘细节。高斯滤波则利用高斯核进行加权平均,适合平滑渐变噪声。完成降噪后,进入字符分割阶段,利用轮廓检测算法找出每个独立字符的边界框,并裁剪出来保存为单独小图。这些小图将成为后续识别模型的输入样本。
整个图像处理流程看似简单,但在复杂验证码上需要反复调试参数。例如,对有旋转或粘连字符的情况,还需引入形态学操作如腐蚀和膨胀,来分离粘连部分。这些基础技巧是所有验证码识别项目的起点,即使小白开发者也能通过几行代码快速上手。
传统机器学习算法:KNN与SVM的实战应用
当图像预处理完成后,就进入字符识别环节。K邻近算法(KNN)是一种简单却有效的分类方法。它的工作原理是计算待识别样本与训练集中所有样本的特征距离,通常使用欧氏距离,然后选取距离最近的K个样本,通过多数投票决定最终类别。在验证码场景中,我们可以将字符图像转换为向量特征,如像素灰度值或HOG梯度直方图,训练集则来自大量标注好的验证码图片。KNN的优势在于无需复杂训练过程,但缺点是大数据量时计算开销较大。

支持向量机(SVM)则更适合处理线性不可分问题。它通过寻找一个最优超平面,将不同字符类别分开,并在平面两侧留出最大间隔。核函数如RBF可以处理非线性情况。在爬虫项目中,SVM常用于训练多分类器,准确率可达95%以上。实际操作时,先提取图像特征向量,然后调用sklearn库的SVC类进行拟合,最后用predict函数识别新样本。这些算法虽然属于传统机器学习范畴,但在验证码识别领域仍具有很高实用价值,尤其适合小规模数据集。

from sklearn.neighbors import KNeighborsClassifier
# 假设features为特征矩阵,labels为标签
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(features, labels)
prediction = knn.predict(new_feature)深度学习进阶:CNN如何征服复杂验证码
面对扭曲、噪点密集或动态变化的验证码,传统算法往往力不从心,这时卷积神经网络(CNN)成为首选。CNN通过多层卷积操作提取图像局部特征,第一层卷积核捕捉边缘, deeper层捕捉抽象模式。池化层则压缩特征维度,减少计算量。全连接层最终输出类别概率。经典架构如LeNet或ResNet在验证码识别上表现优异。

在实际搭建中,可以使用PyTorch或TensorFlow框架。先准备数万张标注验证码数据集,进行数据增强如旋转、缩放以提升泛化能力。训练过程监控准确率和损失值,迭代数十轮后即可部署。CNN的优势在于端到端学习,无需手动设计特征,但需要GPU加速和一定计算资源。对于企业级爬虫,部署一个轻量CNN模型就能处理每日数万次识别需求。
分页处理的巧妙绕过:前后端差异分析
许多网站的分页逻辑分为前端和后端两种实现方式。如果分页请求全部由前端JS处理,后端仅返回完整数据集,那么翻页时可能无需重新验证验证码。通过浏览器开发者工具按F12键,点击下一页观察网络面板,若出现新请求且无验证码参数,即可判断为后端分页。此时直接构造带页码参数的请求,就能绕过校验。

以某些省份工商网站为例,翻页请求中若出现yzmYesOrNo=no这样的标志位,后端会据此跳过验证码检查。另一种情况是验证码仅在前端校验,后端未做二次验证,直接省略验证码字段发送请求即可获取数据。这种方式看似简单,却需谨慎控制请求频率,避免IP异常被封。实际测试中,结合随机延时和代理池,能稳定采集大量企业信息。
多套验证码切换与数据ID规律挖掘

部分网站在不同页面部署了难度不一的验证码机制,这为我们提供了移花接木的机会。例如查询页面使用复杂九宫格,而登录或详情页采用简单字符验证码。先识别简单版验证码,再将结果作为参数提交到复杂页面请求,就能实现整体绕过。
此外,观察数据存储ID往往能发现规律。企业详情页URL常包含自增ID或注册号,通过枚举相邻ID或从搜索引擎缓存中获取ID,再构造直达链接,可跳过搜索验证码环节。WAP移动端版本限制通常更松,直接省略验证码参数也能返回数据。这些技巧结合使用,能大幅降低人工干预需求。
滑动验证码的JS逆向分析:无需模拟拖动
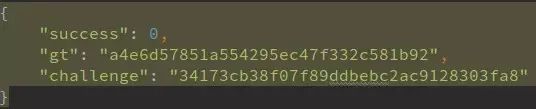
滑动验证码是当前主流防护形式,传统方案需下载图片、计算距离并模拟鼠标拖动。但通过抓包分析前端混淆JS,可以发现许多网站采用离线验证模式。注册接口返回challenge值,后续validate请求中包含通过MD5和随机数计算的加密字符串,无需真实图片交互。
具体过程包括:从固定范围取随机数d和e,对其MD5截取特定位数生成f和g,再组合计算横向偏移量x,最后用自定义t函数加密拼接成geetest_validate。整个流程只需调用注册和验证接口,即可直接获取后续搜索数据。理解这些逻辑后,爬虫脚本只需复现加密步骤,就能实现零拖动绕过,大幅提升效率。
# 伪代码示例
challenge = "34位字符串"
d = random(0,6)
e = random(0,300)
f = md5(str(d))[:9]
g = md5(str(e))[10:19]
h = combine(f,g)
x = max(40, h[-4:] % 200)
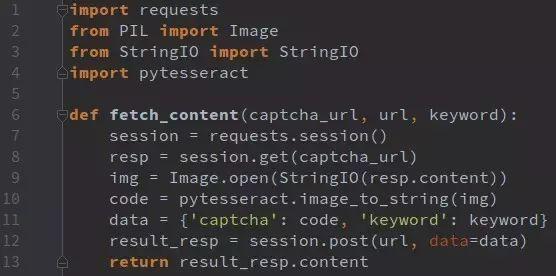
validate = t_encrypt(x, challenge)专业平台助力:简单API对接复杂验证码
当验证码类型覆盖极验和易盾的全系列,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等模式时,自行搭建识别系统会面临高昂的开发和维护成本。这时,企业开发者可以转向专业的识别平台服务。这些平台针对主流反爬验证码进行了深度优化,准确率稳定在95%以上,且支持批量处理。
通过提供的API接口,只需几行HTTP调用代码,即可将验证码图片或参数提交,后台实时返回识别结果。整个对接过程无需本地部署机器学习模型,也不用处理复杂的JS逆向或图像算法。开发者只需注册账号,获取密钥,在爬虫脚本中集成请求函数,就能无缝嵌入现有流程。对于工商网站等高频采集场景,这种方式不仅节省时间,还能规避IP风险和算法更新压力。访问wwwttocrcom了解详情,即可开启高效爬虫新时代。
无论采用自研还是平台方案,核心在于持续观察网站变化,灵活调整策略。爬虫技术的精髓就在于不断探索那些隐藏的突破口,让数据采集工作更加顺畅高效。