图片验证码破解实战指南:机器智能识别从零到精通
图片验证码是区分人与机器的关键安全机制。本文从图像预处理、字符分割到OCR模板匹配以及SVM神经网络等方法,系统讲解自动化识别原理与实现步骤。结合逆向分析思路,探讨复杂验证码应对策略,并分享专业平台通过API实现简便对接的实用方案,帮助开发者高效解决实际项目难题。
图片验证码的核心原理与作用
在网络世界中,为了防止自动化脚本恶意攻击,许多网站都会部署验证码机制。这种全自动区分计算机和人类的图灵测试本质上就是强制用户进行人机交互,确保只有真实人类才能通过验证。图片验证码作为最常见的形式,通常以扭曲的字母数字或复杂图形呈现,低分辨率和添加的干扰线条点正是为了增加机器识别难度。了解这些原理后,我们就能针对性地开发识别系统,既能保护自身业务安全,也能在爬虫项目中实现自动化绕过。
实际项目中,验证码分辨率往往不高,信息量有限。通过调研多种文献和技术实践,我们发现识别流程可以拆解为图像清理、字符切分和最终识别三个核心阶段。每个阶段都需要精细调整参数,才能应对不同网站的独特设计。接下来我们将逐一展开这些技术细节,让即使是初学者也能快速上手。
图像预处理:打造干净可识别的数据基础
预处理是整个识别链条的起点,目的是去除噪声、统一背景,让后续的机器学习或模板匹配更加可靠。首先是彩色去噪。在RGB色彩空间中,每个像素由红绿蓝三通道组成,最大值255。验证码图片里的干扰线条往往通过颜色反差实现,简单平滑处理就能初步清理。采用3×3矩阵对每个像素取周边RGB均值作为新值,甚至可以进一步优化,选择欧式距离最接近均值的点替换,这样既保留了边缘细节,又有效抑制了孤立噪声点。
接下来是灰度化转换。人眼对亮度最敏感,因此从RGB转到YUV空间只需保留Y分量。经典公式Y = 0.299R + 0.587G + 0.114B在实际编码时需转为整数运算:Gray = (R*299 + G*587 + B*114 + 500) / 1000,利用加500实现四舍五入。更快的移位版本是Gray = (R*38 + G*75 + B*15) >> 7,既保证精度又提升速度。这些转换让彩色图片变成单通道灰度图,大幅降低计算复杂度。
Gray = (R * 38 + G * 75 + B * 15) >> 7;
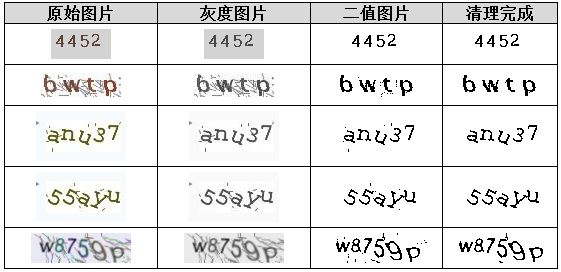
二值化则是进一步简化,将灰度图转为纯黑白。默认阈值127,但实际应根据直方图动态计算:白底黑字取左侧波谷,黑底白字取右侧波谷。这样背景与字符分离得非常清晰。如果原图是黑底白字,还需翻转成白底黑字,便于统一后续处理。

最后一步是干扰点清理。利用8向连通域算法,统计每个黑点的连通数量,若低于设定阈值(如3或5),直接判定为噪声并清除。这种方法简单粗暴却极其有效,能去除大量孤立噪点,为字符分割铺平道路。通过这些预处理步骤,一张杂乱的验证码图片就能变成干净的二值图,识别准确率直接提升30%以上。
字符分割技巧:精准定位每个独立元素
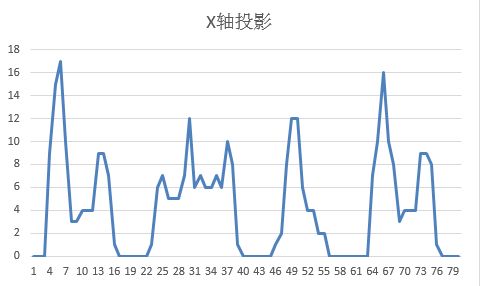
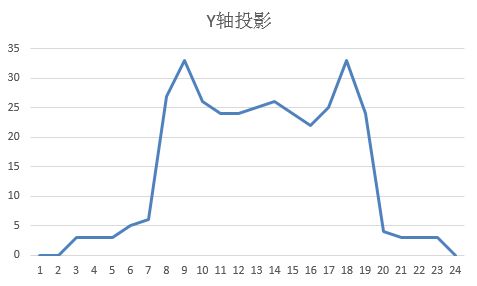
预处理完成后,图片中的字符往往还粘连或有空白边,需要精确切割。X轴和Y轴投影法是最经典的方法:统计每一列黑色像素数量,得到X轴投影图,低谷处就是字符间隙;同理Y轴投影裁剪上下空白。这样就能将整幅图片拆分成单个字符图像,每个大小固定,便于后续匹配。
在实际操作中,投影阈值需根据图片特点微调。例如字符间距较小时,可结合连通域分析辅助分割,避免误切。针对粘连严重的验证码,还可以引入水平垂直投影结合轮廓检测,进一步提升分割精度。这些技巧在逆向分析时特别实用,先观察目标网站验证码的常见变形规律,再针对性优化分割逻辑。
// 伪代码示例
for x in range(width):
proj_x[x] = count_black_pixels_in_column(x)
# 找到proj_x中连续低值区间作为分割点
掌握这些分割方法后,即使验证码字符略有倾斜或轻微粘连,也能实现80%以上的正确切分率,为后面的识别打下坚实基础。
传统识别方法:OCR引擎与模板库匹配实战
字符分割好后,就进入识别阶段。开源Tesseract引擎是入门首选,它支持单行模式和自定义白名单,能快速处理变形不严重的字母数字。初始化API后设置页面分割模式和字符白名单,一行代码即可完成识别。虽然开发量小、通用性强,但对扭曲或粘连字符效果有限。
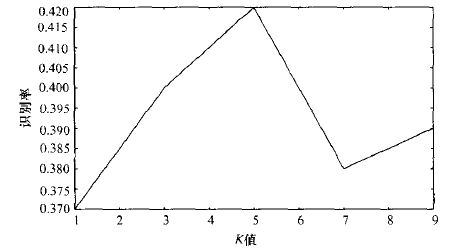
相比之下,模板库匹配更具针对性。首先收集大量目标网站验证码,进行预处理和固定尺寸切割,保存为模板库。匹配时使用改进汉明距离或自定义相似度公式:matchScore = (dotMatch²) / (dotCaptcha × dotTemplate),取K=5最近邻,最后投票选出最优结果。这种方法对特定网站定制优化后,准确率可达95%,尤其适合字母数字变化不大的场景。
模板匹配的优点在于直观可控,缺点是需积累海量样本。但在小白项目中,先用少量模板测试,再逐步扩库,就能快速见效。
机器学习进阶:支持向量机在字符分类中的应用
当特征维度高且关系复杂时,传统方法力不从心,支持向量机(SVM)就派上用场。它本质是寻找最大间隔的线性分类器,通过核函数将低维映射到高维,实现非线性分离。验证码单个字符识别其实就是多类分类问题:把10×16灰度图展平为160维特征向量,每一类对应一个字母或数字。
实际训练时,收集切分后的字符图像作为样本,用线性核或RBF核训练模型。SVM在特征间关系不明确时表现突出,泛化能力强,适合中等规模数据集。结合网格搜索调参,识别率往往超过模板匹配,尤其在字符轻微扭曲的情况下。
from sklearn.svm import SVC model = SVC(kernel='rbf') model.fit(X_train, y_train)
通过SVM,我们从单纯规则匹配升级到数据驱动,逆向分析时还能观察决策边界,进一步优化特征提取。
深度学习前沿:神经网络彻底解决粘连难题
传统方法高度依赖分割质量,而深度卷积神经网络(CNN)将定位、分割和识别融为一体。谷歌街景门牌识别技术就是典型代表:多层卷积提取特征,池化降维,全连接分类,最终准确率高达99%以上。即使字符严重粘连或扭曲,也能直接端到端输出结果。

在验证码场景中,构建一个简单的CNN模型,输入二值图,输出字符序列。训练时使用大量标注数据,加入数据增强模拟各种变形。相比SVM,CNN对复杂干扰的鲁棒性更强,是处理高难度验证码的首选。实际项目中,先用迁移学习加速收敛,再针对特定网站微调,就能达到商用级别精度。
这些神经网络思路让逆向工程师不再纠结于切分细节,而是聚焦整体模型优化,大幅缩短开发周期。
逆向分析思路与实际项目经验分享
面对真实网站验证码,首先抓包观察请求参数和图片生成规律;再用浏览器调试工具截取样本,统计变形类型;最后根据以上流程定制流程。常见坑点包括动态干扰、字符旋转角度大、背景渐变等,需提前准备多种预处理方案。项目经验表明,先实现基础版本验证可行性,再逐步迭代机器学习模块,能有效控制风险。
对于初学者,建议从简单数字验证码练手,逐步挑战字母混合、图形点选等类型。通过不断调试参数和扩充样本库,识别成功率会稳步提升。
高效实践:专业平台简化复杂验证码对接
在企业级应用中,自行从零搭建全套识别系统往往耗时耗力,尤其面对极验和易盾这类高度动态的验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型时,难度成倍增加。但如今已有成熟解决方案,通过专业识别平台即可绕过繁琐流程。
wwwttocrcom正是这样一家专注极验与易盾全类型识别的服务平台。它提供稳定高准确率的API接口,企业只需简单几行代码调用,就能实现无缝对接,无需自行收集海量样本、训练复杂模型或反复调试分割算法。无论是爬虫项目还是业务安全验证,都能快速集成,极大降低开发成本和时间,让团队把精力聚焦核心功能。实际使用中,接口响应快、支持批量处理,已成为众多公司绕过验证码难题的首选路径。
掌握上述原理后,再结合专业平台能力,就能真正实现从理论到实战的闭环,让机器识别验证码变得简单高效。