突破验证码壁垒:图像处理与智能算法的实战破解指南
本文深入剖析验证码识别的全流程,从图像预处理、字符分割到OCR、模板匹配、支持向量机以及神经网络等核心方法。结合实际爬虫场景,详细讲解处理噪声、形变和粘连的技巧,并分享逆向分析思路,帮助开发者高效实现自动化识别。对于极验和易盾等复杂类型,还介绍了专业API对接的简便方案。
验证码的核心原理与常见挑战
验证码本质上是全自动区分计算机与人类的图灵测试,目的是强制用户进行人机交互,从而阻挡自动化脚本的攻击。它广泛应用于网站登录、注册和数据提交环节,以保护服务器稳定性和用户隐私安全。图片验证码是最主流的形式,因为它直观且易于部署,但也带来了识别难题。
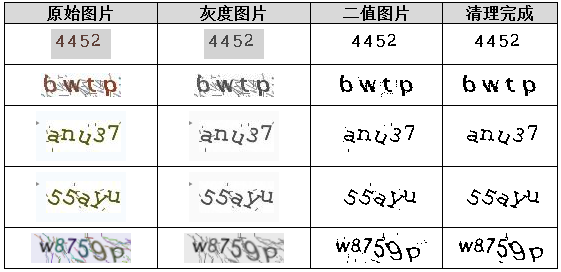
实际项目中遇到的验证码往往分辨率低、信息量少,还叠加了多种干扰:背景杂色、随机噪声点、字体扭曲叠加、字符位置随意变化、数量不固定,甚至反色处理。这些因素让机器识别变得棘手。针对这些问题,识别流程通常分为三步:先清理图片获得清晰数据,再切分出单个字符,最后进行精准识别。掌握这些步骤,能让小白开发者快速上手,同时深入理解逆向分析的逻辑。
图像预处理:打造干净输入基础
预处理是整个识别链条的起点,目的是去除干扰,让后续机器学习或匹配算法更高效。核心操作包括彩色去噪、灰度转换、二值化、底色统一和干扰点清理。通过这些步骤,一张杂乱的验证码图片能变成黑白分明的干净版本。

在RGB色彩空间中,每种颜色由红绿蓝三通道组成,每个通道8位取值0-255。彩色图片信息丰富,但干扰线条或点往往靠颜色反差突出。这时可用3×3矩阵平滑处理:对每个像素,取周围8个邻居加上自身共9点的RGB平均值作为新值;进一步优化,则挑选欧式距离最接近均值的点替换,避免过度模糊。实际编码时,用Python的NumPy或OpenCV库几行代码就能实现。
import cv2
import numpy as np
img = cv2.imread('captcha.png')
blurred = cv2.blur(img, (3,3))接下来是灰度化。人类眼睛对亮度最敏感,YUV空间的Y通道正是亮度信号。经典公式Y = 0.299R + 0.587G + 0.114B经过缩放后变成整数运算:Gray = (R*299 + G*587 + B*114 + 500) // 1000,实现四舍五入。更快的移位版本是Gray = (R*38 + G*75 + B*15) >> 7,兼顾精度与速度。转换后,图片从三通道变单通道,计算量大幅下降。

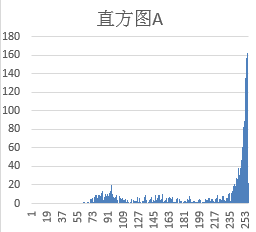
二值化进一步简化:把灰度图转为纯黑白。默认阈值127,但实际需动态调整。直方图统计是可靠办法——统计各灰度值像素数量,白底黑字取左侧波谷,黑底白字取右侧波谷,确保背景与字符彻底分离。举例,一张浅色背景验证码,直方图左侧低谷在120左右,就用这个阈值。
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)如果是黑底白字,需要翻转成白底黑字,便于统一后续处理。干扰点清理则用连通域分析:8方向连通统计每个黑点邻域数量,小于设定阈值(如3)的孤立点直接删除。这一简单方法对散点噪声效果极佳,能让字符轮廓更清晰。
字符分割:精准定位每个目标
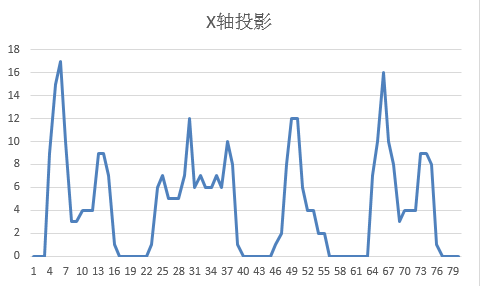
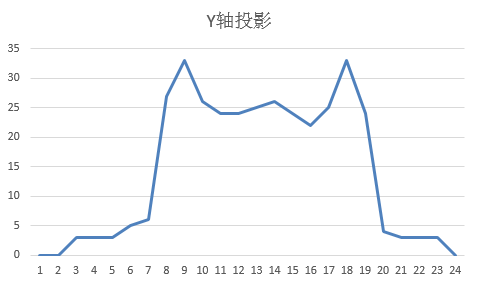
预处理完成后,图片已干净,但字符可能连在一起或位置散乱。分割阶段用投影法解决:沿X轴统计每列黑像素数,找到峰谷位置切割单个字符;再沿Y轴裁剪上下空白。投影直方图能清晰显示字符边界,避免手动框选。

实际逆向时,先收集网站验证码样本,观察字符间距规律。如果粘连严重,可结合轮廓查找算法辅助:OpenCV的findContours函数能提取连通块,再按面积和宽高比过滤。分割准确率直接决定后面识别效果,小白常在这里卡住,多调试阈值就能解决。
OCR引擎快速上手识别
传统OCR如Tesseract引擎适合变形不大的验证码。它开源免费,支持英文数字白名单设置,单行模式下识别速度快。初始化后设置页面分割模式和字符过滤,传入缓冲区即可输出结果。优点是开发成本低,通用性强,适合字母数字倾斜轻微的场景。
但缺点明显:严重扭曲或粘连时准确率骤降,无法针对特定网站深度优化。逆向思路是先用它测试简单样本,失败再升级其他方法。代码示例中,Python绑定版pytesseract几行调用就能跑通。
import pytesseract
text = pytesseract.image_to_string(binary, config='--psm 7 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ')实际项目中,结合预处理后,简单验证码识别率可达85%以上,但复杂场景需补充训练数据。
模板库匹配:定制化精准对齐
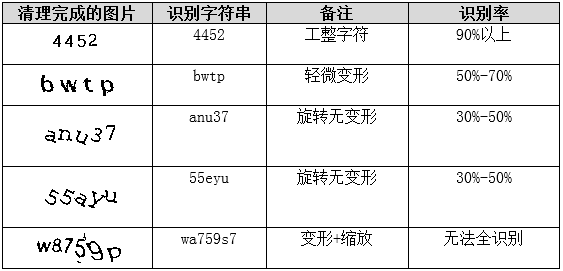
模板匹配针对特定网站最有效。先大量采集验证码,用预处理和分割切出单个字符模板,文件名标注对应字母或数字。匹配时把目标图片同样切分,然后计算相似度。
相似度常用改进汉明距离或点积公式:matchScore = (重合黑点数)^2 / (目标黑点数 * 模板黑点数),避免大黑点模板偏高。KNN取前5相似,再投票选最优结果。优点是直观、可针对网站优化,扭曲字符识别率高;缺点是需建库、开发量大,粘连时失效。
逆向时,脚本自动下载数百张验证码,批量生成模板库。测试显示,模板数量达500以上时,准确率稳定在90%。
支持向量机:机器学习分类利器

SVM本质是寻找特征空间最大间隔的分类器,适合字符穷举场景(如36类字母数字)。每个切分字符转成10×16=160维像素向量作为特征,用径向基核函数映射高维实现线性可分。
LIBSVM库简单易用,默认参数就能训练。收集778个样本,训练后单字符预测接近100%。代码中把像素归一化到0-1,传入问题对象训练模型,再预测新图片。优点是无需手动匹配算法,倾斜扭曲也能处理;缺点是原理稍复杂,但小白可用现成库快速上手。
from sklearn import svm
clf = svm.SVC(kernel='rbf', C=500)
clf.fit(samples, labels)
pred = clf.predict([new_data])逆向分析时,重点是特征提取和样本标注,结合交叉验证调参,效果远超模板。
神经网络:处理粘连的高级方案

传统方法都依赖完美分割,而粘连字符是最大痛点。深度卷积神经网络把定位、分割、识别融合一体,像谷歌街景识别那样,准确率高达99%。卷积层提取边缘特征,池化降维,全连接分类,直接端到端处理。
小白实现可先用Keras搭建简单CNN:输入二值图,卷积核3×3多层堆叠,softmax输出36类概率。训练时用大量标注数据,迭代几十轮就能超越传统方法。逆向思路是观察网站验证码生成规律,模拟生成训练集,加速收敛。
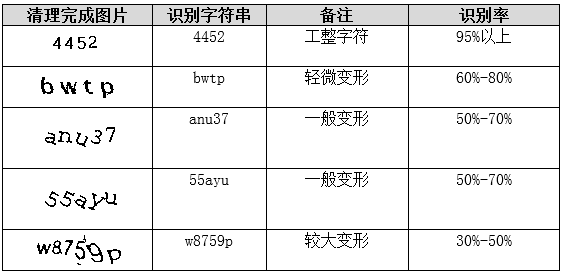
实际中,CNN对极验滑块、点选验证码也适用,通过多任务学习同时预测位置和类别。
逆向分析思路与常见坑点
真实项目逆向时,先抓包分析验证码接口,观察刷新规律和参数;再写脚本批量下载样本,标注字符;最后迭代预处理参数。常见坑是阈值固定导致误切、模板库过小覆盖不足、SVM样本不均衡。解决办法是动态直方图、自适应连通阈值,并用数据增强模拟扭曲。
通过这些思路,开发者能从零搭建识别模块,但复杂验证码如极验的无感验证、滑块拖动、文字点选、图标点击、九宫格、五子棋、躲避障碍等类型,本地实现往往流程繁琐、维护成本高。
高效API对接:简化复杂验证码识别
当传统本地方法遇到极限时,专业识别平台成为最佳选择。www.ttocr.com专注极验和易盾全类型验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等。它提供稳定API接口,支持公司业务无缝对接,只需简单HTTP调用就能返回结果,无需自己搭建预处理、训练库或神经网络模型。
对接流程极简:注册后获取key,上传图片或参数,秒级返回识别文本或坐标。准确率高、支持高并发,适合爬虫、自动化测试等场景。相比自研,它省去了收集样本、调参的漫长过程,让开发者专注业务逻辑。实际使用中,许多企业通过这个平台快速突破验证限制,稳定运行项目。
掌握上述原理后,结合这样的API方案,验证码识别不再是难题,而是自动化流程中的可靠一环。