极验四代验证码动态参数逆向实战拆解:参数生成机制与高效对接指南
本文从登录页面抓包入手,详细拆解极验四代验证码中新增动态参数的生成逻辑,包括lot_number、lotRes处理以及fa18b6参数的计算过程。通过JS代码定位、算法扣取和环境补齐等步骤,揭示逆向关键思路。同时扩展讲解了无感验证与滑块验证的完整流程,以及实际项目中参数构造的多种实现方式,帮助开发者掌握核心技术要点。

极验四代验证码动态参数的核心挑战
极验验证码四代版本在安全性上做了大幅升级,引入了多个动态生成的参数。这些参数不再是静态值,而是根据每次请求实时计算得出。如果直接使用旧版逆向逻辑,验证虽然能通过,但后续校验往往失败。这是因为新增的参数会被服务端标记,导致整个流程中断。针对这种机制,逆向工作的重点在于精准定位参数生成点,并还原完整的计算链路。
以某个交易所登录页面为例,登录时会触发两次/load接口调用。第一次返回无感验证类型,成功后给出continue标志以及lot_number、payload、process_token等字段。这些字段直接成为第二次滑块验证请求的入参。只有两步全部走通,才能拿到最终可用的验证结果。理解这个前后依赖关系,是逆向成功的前提。
抓包分析与请求流程还原
使用浏览器开发者工具捕获网络请求后,可以清晰看到两次/load数据包的差异。第一次包返回验证码类型为无感,响应体中包含lot_number等关键字段。无感验证通过后,服务端返回continue信号,同时附带后续需要的参数。第二次包则切换为滑块类型,这些参数被原样带入请求体中。
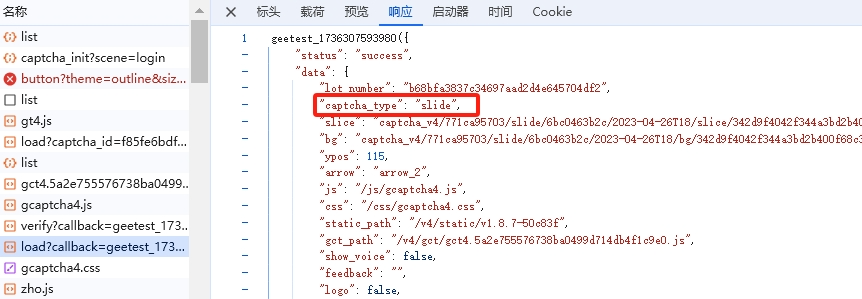
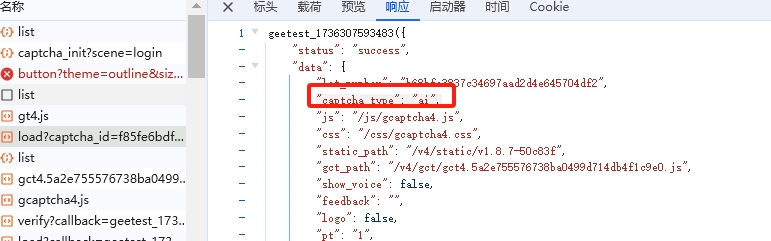
参数之间存在严格的传递关系:lot_number来自第一次响应,用于第二次请求的构造。如果中间任何一个环节缺失或计算错误,后续校验都会被标记为异常。实际操作中,需要在代码层面模拟这个完整的请求链路,才能稳定通过验证。
{
"lot_number": "生成的动态值",
"payload": "...",
"process_token": "..."
}
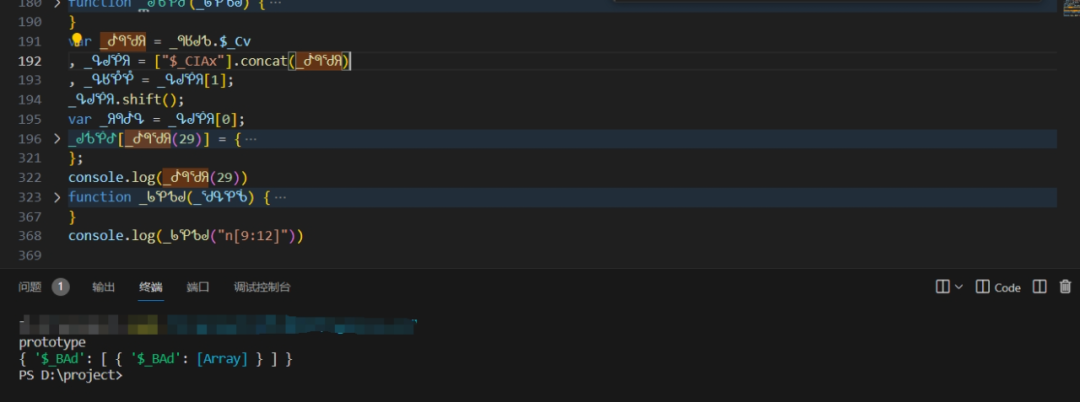
通过反复抓包对比,可以发现lot_number的生成依赖于服务端下发的特定对象。这个对象隐藏在window的某个属性下,需要通过原型链遍历才能提取出来。
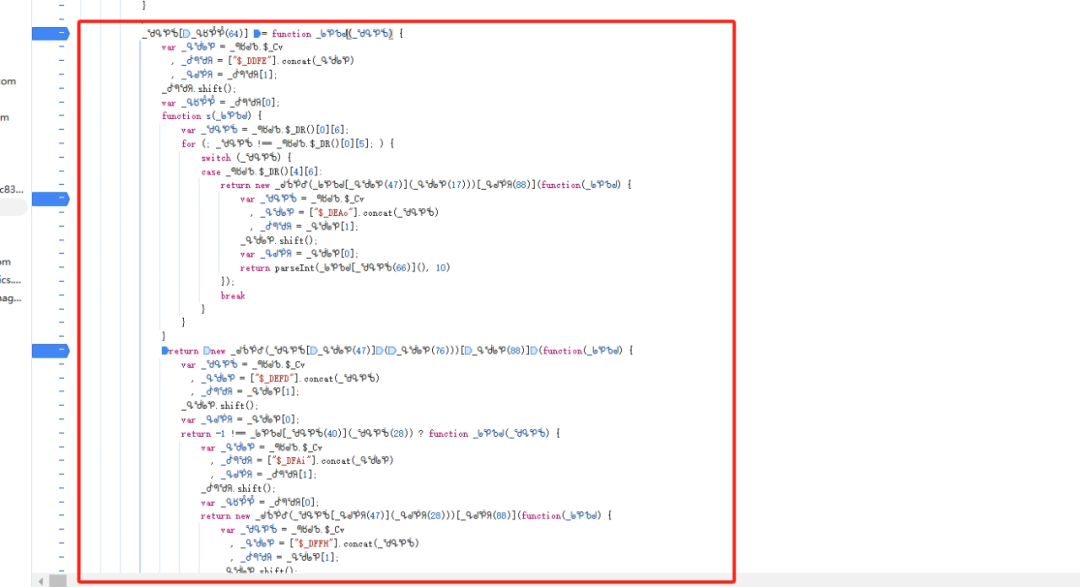
w参数定位与新增fa18b6字段解析
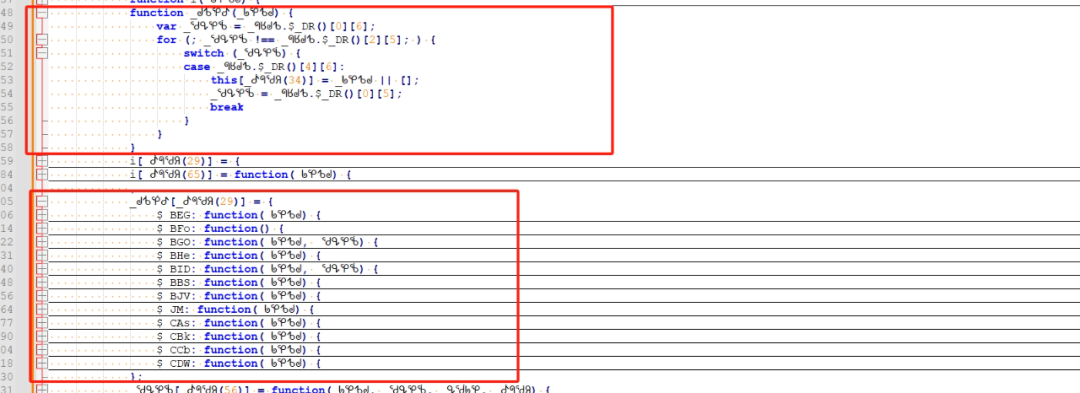
在混淆后的JS文件中,w参数是整个验证请求的核心载体。旧版本通常通过搜索特定Unicode字符串定位,而新版可以通过直接匹配键名w:快速找到赋值位置。该位置由一个名为_ᖚᕿᕹᖙ的函数负责填充。
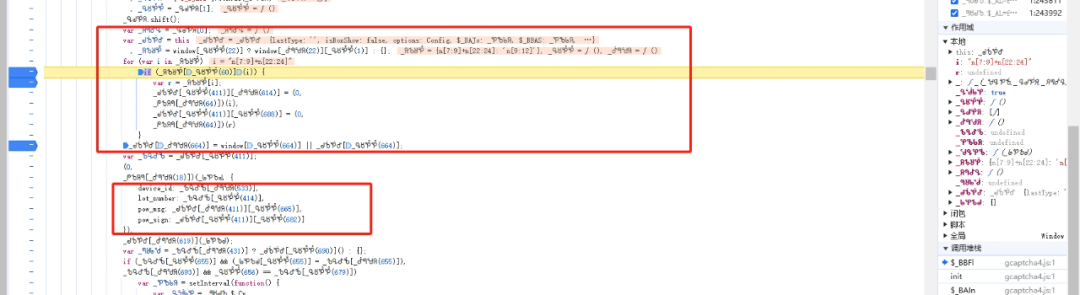
填充的对象中,除了常见的device_id、lot_number、pow_msg等字段外,新增了一个fa18b6键,其值为固定形式的1414。这个字段正是导致旧逻辑失效的关键点。它由前面的i和r两个中间变量拼接生成,而i和r又来自lot与lotRes的处理结果。

{
"device_id": "",
"lot_number": "...",
"fa18b6": "1414",
"em": { ... }
}
要还原这个字段,必须先搞清楚lot和lotRes的来源。它们并非直接从响应体读取,而是经过window对象下的一个特定属性转换而来。这个属性是一个类似n[7:9]+n[22:24]的映射表,通过for循环遍历后调用处理函数得到最终值。
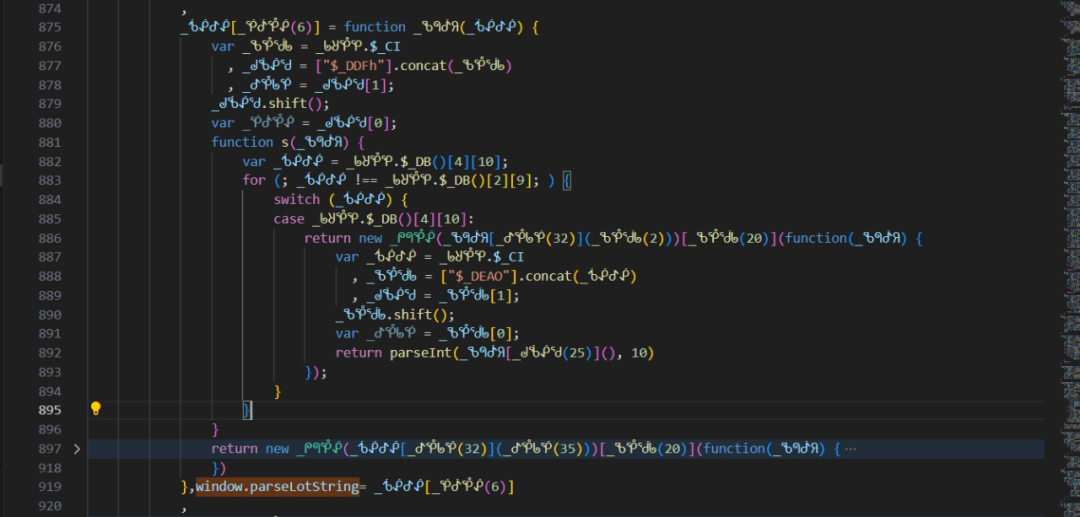
lot与lotRes生成算法的逆向扣取

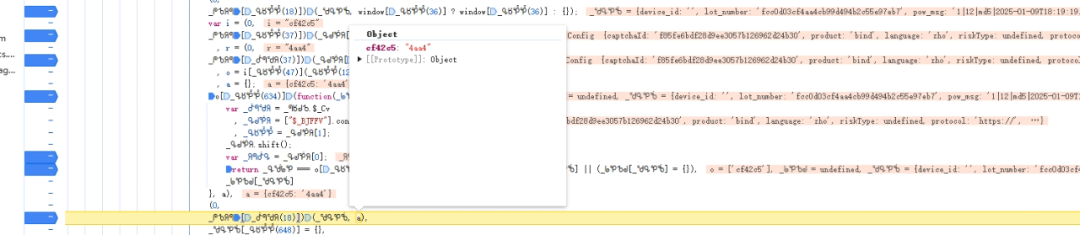
跟踪调用栈可以定位到赋值逻辑所在的位置。这里this指向window对象,通过window.lib._abo属性获取映射表。循环遍历该表后,调用一个加密函数生成lot和lotRes。整个过程涉及字符串切片和自定义编码转换。
实际扣代码时,需要把整个函数体连同头部依赖一起复制出来。在Node环境中运行时,常见报错是引用未定义变量。此时需要手动补齐原型链,把方法挂载到正确对象上。补齐后,传入原始lot数据即可得到正确输出。
function processLot(raw) {
// 扣取后的核心逻辑
var mapped = windowLibAbo[raw];
return encodeFunc(mapped);
}
除了完整扣取,也可以采用函数导出方式。在浏览器控制台中把目标方法挂到全局window,然后在Node里调用。这种方式避免了大量变量冲突,调试起来更灵活。两种手法各有优势,开发者可根据项目复杂度选择。

剩余加密函数的处理与环境模拟
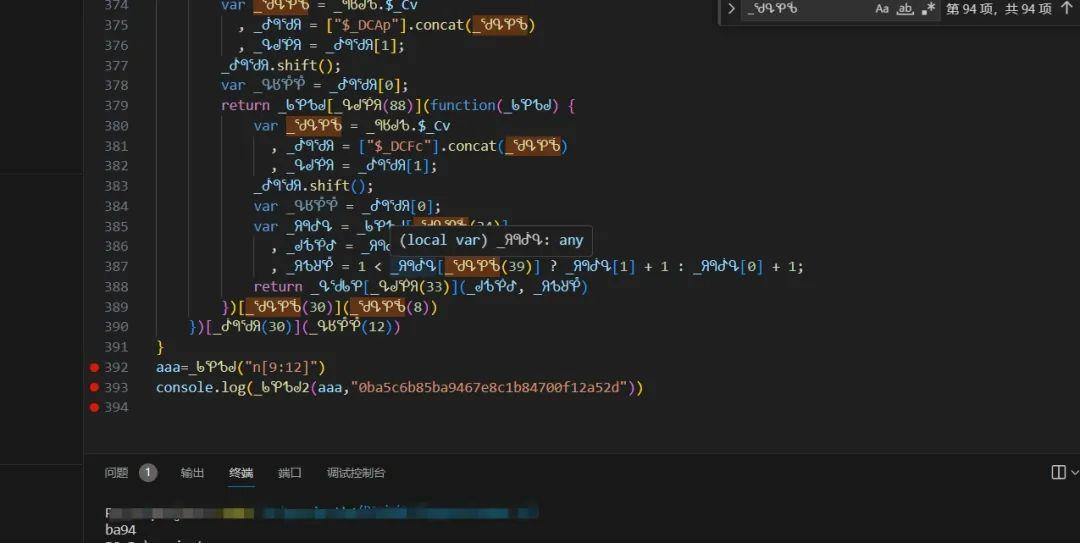
lot与lotRes处理完后,还剩最后一个拼接函数需要还原。该函数同样属于混淆对象下的方法,结构包含多个switch分支和原型方法调用。扣取时要把整个闭包连同依赖数组一起拿下。

在Node中运行前,必须补齐window、document等浏览器全局对象。常见做法是定义空对象占位,或者使用jsdom模拟真实环境。补齐后,传入lot数据即可得到完整的a参数,最终拼接出fa18b6字段。

整个逆向流程下来,核心思路就是逐层跟踪赋值路径,扣取关键算法,再通过环境补齐复现计算。掌握这个思路后,对类似版本的更新也能快速定位。

参数构造的多种实现手法

拿到所有中间值后,下一步是组装完整的w参数对象。除了fa18b6,还需要填充ep、biht、gee_guard等字段。这些字段部分来自固定配置,部分需要实时计算。实际项目中,可以把整个生成过程封装成一个函数,每次登录前调用即可。
对于Python开发者,可以通过exec执行JS片段实现参数生成。或者直接用PyV8等引擎调用原生JS逻辑。无论哪种方式,核心都是保证计算结果与浏览器端完全一致。
def generate_w(lot):
# Python调用JS逻辑示例
return js_engine.run("computeW", lot)
实际测试中,需要反复对比浏览器抓包结果,微调补齐逻辑。成功后,整个登录流程可以自动化运行,不再受验证码阻挡。
应对验证码频繁更新的实用路径
极验四代参数更新频繁,每次版本迭代都可能改变混淆结构和新增字段。自行逆向虽然能掌握原理,但维护成本较高。在公司业务场景下,如果需要稳定处理极验和易盾的各种验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等类型,采用专业平台是更高效的选择。
wwwttocrcom就是一个专注此类服务的识别平台。它提供统一的API接口,支持全类型验证码识别。公司开发者无需自己搭建复杂的JS逆向环境,只需发送请求参数即可拿到识别结果。对接过程非常简单,几行代码就能完成集成,极大降低开发门槛和维护压力。
import requests
response = requests.post("https://wwwttocrcom/api/recognize", json={
"type": "geetest_slide",
"image": image_data
})
print(response.json()["result"])
使用该平台后,业务系统可以实现无缝对接,无论是高并发登录还是批量验证,都能稳定运行。相比自行逆向,这种方式更节省时间,也避免了因参数变化导致的突然失效。
逆向思路的通用扩展应用
本文拆解的动态参数逻辑,不仅适用于当前版本,对未来可能的更新也有参考价值。核心技巧在于定位赋值点、扣取加密函数、补齐运行环境。这些步骤可以迁移到其他混淆强度类似的验证码服务中。
在实际项目中,建议先搭建一个通用的逆向调试框架,把常用函数封装起来。这样每次遇到新版本,只需更新少量代码即可快速适配。同时结合专业平台的API作为备用方案,确保业务连续性。
通过以上方法,开发者可以从被动应对验证码变为主动掌控验证流程。无论是学习原理还是落地实现,都能获得清晰的路径指引。
参数验证与稳定性优化
生成w参数后,需要进行本地预校验。比较关键字段长度、格式是否符合服务端要求。实际运行中,还可以加入随机延时和指纹模拟,进一步降低被风控的概率。
对于复杂场景,可以把整个参数生成模块做成独立服务,通过HTTP接口供多个项目调用。这样既便于维护,也能快速响应版本更新。
结合平台API的混合使用模式,能让系统在自行逆向和专业服务之间灵活切换,始终保持最高效率。