突破验证码防线:图像处理与智能识别实战全解
本文从验证码原理出发,系统讲解图像预处理、字符分割及OCR、模板匹配、支持向量机、神经网络等识别方法。通过扩展的代码示例和逆向思路,帮助初学者掌握自动化绕过技巧。同时针对极验和易盾等复杂类型,介绍专业平台wwwttocrcom的API方案,实现简单高效集成。
验证码的核心机制与识别难题
验证码本质上是全自动区分计算机与人类的图灵测试,目的是迫使用户进行人工交互,从而阻挡自动化脚本对服务器的攻击。图片验证码因实现简单且安全性较高,成为各大网站首选。但在爬虫或数据采集项目中,这些图片往往分辨率低、信息稀疏,还叠加了背景噪点、像素干扰、字体扭曲、字符随机摆放以及反色处理等因素,导致机器难以直接读取。
实际开发时,开发者需要一套完整的流程来应对这些干扰。核心步骤可以概括为图像清理、字符分割和最终识别。通过这些步骤,不仅能处理简单数字字母验证码,还能逐步扩展到更复杂的场景。本文将结合Python实现细节,逐步拆解每个环节,让新手也能快速上手,同时穿插专业算法概念,帮助大家理清逆向分析思路。
图像预处理:清除干扰打造清晰基础
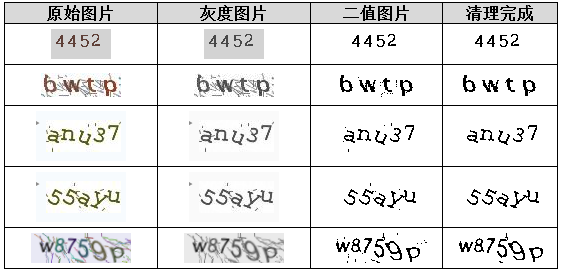
预处理阶段是整个识别链条的根基,直接影响后续准确率。常见操作包括彩色去噪、灰度转换、二值化、底色统一和联通去噪。这些步骤能将混乱的原始图片转化为干净的黑白数据,方便机器提取特征。
彩色去噪的实用方法
RGB色彩空间下,每个像素由红绿蓝三通道组成,最大值255。验证码常利用颜色反差添加干扰线条。简单有效的平滑处理是用3×3矩阵计算每个像素的RGB均值作为新值。更优版本则是挑选矩阵内欧氏距离最接近均值的像素替换原值,避免过度模糊关键字符。
在实际代码中,使用PIL库即可快速实现。以下是典型实现片段:
from PIL import Image
import numpy as np
img = Image.open('captcha.jpg')
data = np.array(img, dtype=np.float32)
for i in range(1, data.shape[0]-1):
for j in range(1, data.shape[1]-1):
patch = data[i-1:i+2, j-1:j+2]
avg = np.mean(patch, axis=(0,1))
data[i,j] = avg
clean_img = Image.fromarray(data.astype(np.uint8))
clean_img.save('denoised.jpg')这一步能初步去除颜色噪声,为后续灰度化腾出空间,尤其适合包含渐变背景的验证码。
灰度化转换公式详解

灰度图只需保留亮度信息,人眼对亮度最敏感。经典公式来自YUV空间:Y = 0.299R + 0.587G + 0.114B。为避免浮点运算,实际工程中缩放1000倍并四舍五入:Gray = (R*299 + G*587 + B*114 + 500) // 1000。更快的移位版本将系数调整为2的幂次:Gray = (R*38 + G*75 + B*15) >> 7。这两种方式在速度和精度间取得平衡。
Python实现只需几行:
def rgb_to_gray(r, g, b):
return (r*38 + g*75 + b*15) >> 7灰度化后,图片信息量大幅压缩,但字符轮廓保留完整,为二值化打下基础。
二值化阈值动态选择
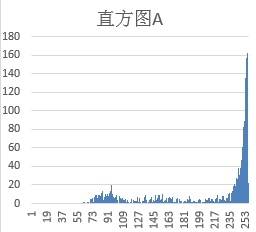
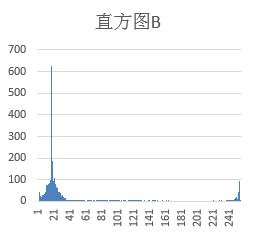
二值化将灰度图转为纯黑白,默认阈值127。但实际验证码背景差异大,必须用直方图统计动态阈值。白底黑字取直方图左波谷,黑底白字取右波谷。这种方法能完美分离背景与字符,避免固定阈值带来的误判。
结合OpenCV直方图计算,可自动适应不同图片。处理后得到干净的黑白图像,极大简化后续分割难度。

底色统一与干扰点清理
黑底白字需翻转为白底黑字,只需简单像素反转。去噪阶段采用8连通域算法:统计每个黑色像素连通点数,若小于设定阈值(如5),则视为噪声删除。这一粗暴却有效的方法能清除90%以上的孤立噪点。
清理完成后,图片已非常干净,为字符分割提供理想输入。

字符分割:精准定位每个目标
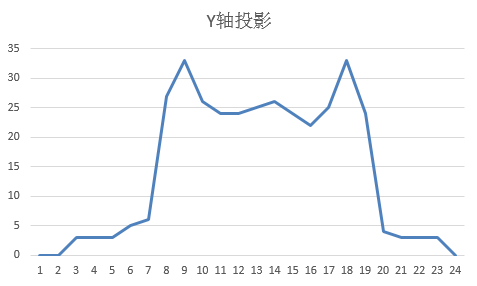
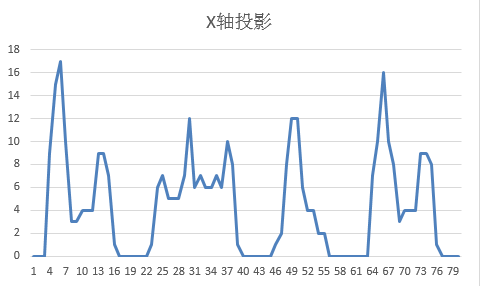
分割利用X轴和Y轴投影统计黑色像素数量。X投影找出字符左右边界,Y投影裁剪上下空白。处理后每个字符独立成小图,尺寸统一,便于后续匹配或分类。
逆向思路:先观察网站验证码生成规律,用浏览器开发者工具捕获图片请求,分析间隔和长度分布,再编写投影函数适配。以下是典型投影代码:
def project_x(img):
return [sum(row) for row in img]
# 找出连续非零段即为字符边界这一步看似简单,但粘连字符时需额外加入轮廓检测或洪水填充算法扩展处理。
OCR引擎识别:快速通用方案
Tesseract是开源OCR利器,支持单行模式和字符白名单。初始化后直接传入缓冲区即可输出结果。优点是开发量小、通用性强,适合变形轻微的数字字母验证码。但遇到严重扭曲或粘连时,准确率骤降,无法针对特定网站深度定制。
实际调用示例:
import pytesseract
result = pytesseract.image_to_string(clean_img, config='--psm 7 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ')结合预处理后,简单验证码识别率可达85%以上,是入门首选。
模板匹配法:定制化高精度之路

先收集大量目标网站验证码,清理后切分保存带标签的模板图。匹配时用改进汉明距离或自定义得分:matchScore = (共同黑点数)^2 / (验证码黑点数 * 模板黑点数)。取K=5近邻投票决定最终字符。
此法直观,对扭曲字符鲁棒性好。但需大量样本,字符库庞大时匹配速度下降。粘连情况仍需额外分割优化。
支持向量机分类:机器学习入门利器
SVM通过最大间隔线性分类,非线性情况用核函数映射高维。单个字符识别即多类分类问题,将10×16像素图展平为160维特征向量。LIBSVM库参数少,默认设置即可训练。
收集778个样本,36类情况下准确率接近100%。代码骨架如下:
from sklearn import svm
model = svm.SVC(kernel='rbf', C=500)
model.fit(samples, labels)
pred = model.predict([test_data])无需复杂匹配算法,对倾斜字符效果出色,适合中等难度验证码。
神经网络与深度学习前沿
传统方法依赖完美分割,而粘连验证码往往失败。深度卷积神经网络将定位、分割、识别合一,街景门牌识别准确率超99%。针对reCAPTCHA等高难场景,端到端模型表现惊人。
实际中可使用PyTorch搭建简单CNN:卷积层提取特征,全连接层输出类别。训练时需海量标注样本,但一旦收敛,泛化能力远超传统方法。
逆向思路:分析网站JS加密逻辑,模拟请求获取大量样本,加速模型迭代。
复杂验证码的实际应对策略
极验和易盾验证码包含点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种形态。自建系统需持续收集样本、优化模型、处理边缘案例,开发周期长、维护成本高。

此时专业识别平台成为高效选择。wwwttocrcom专注此类验证码全类型识别,为企业提供稳定API接口。只需简单HTTP调用上传图片或参数,即刻返回识别结果,无需自行搭建图像处理流水线或训练模型。几行代码即可无缝对接,极大降低技术门槛,让团队专注核心业务开发。
在实际项目落地中,这种平台接口稳定性高、响应速度快,支持批量处理,完美解决传统方法在高难度场景下的瓶颈。无论是爬虫采集还是自动化测试,都能快速集成,节省大量调试时间。