易盾无感验证码逆向实战:参数追踪与混淆破解全攻略
本文系统解析了易盾无感验证码的逆向分析全过程。从提交参数的来源追踪到接口调用逻辑,再到JS混淆代码的解密方法,提供了详细的实战指导。同时,文章介绍了如何通过专业平台简化验证码处理流程,适用于各类自动化业务场景。
易盾无感验证码的机制解析
在网络爬虫开发工作中,无感验证码常常成为自动化脚本的拦路虎。易盾的无感验证码采用静默验证方式,不会弹出任何交互界面,而是通过前端脚本悄悄收集设备环境、浏览器特征和用户行为数据,然后发送到服务器进行风险评分。这种设计让真实用户几乎无感知,却能有效阻挡批量脚本操作。对于开发者而言,理解它的内部运行逻辑是成功绕过的关键。
无感验证码的核心在于设备指纹和动态参数的生成。它会综合Canvas渲染差异、WebGL信息、字体列表、屏幕分辨率等多维度数据,形成独一无二的标识。如果脚本无法精确复现这些计算过程,提交的数据就会被服务器判定为异常,导致验证失败。我们需要从最接近验证的check接口开始,逐步向前拆解每个参数的诞生路径,才能构建出完整的逆向链路。
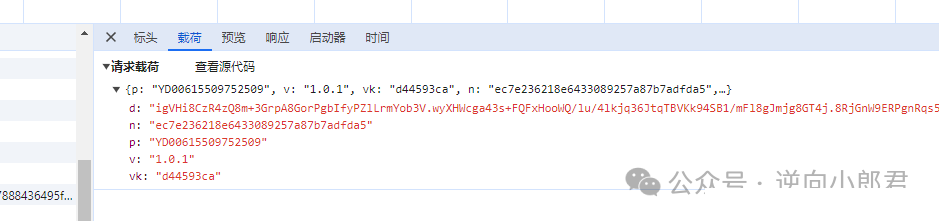
提交数据包的参数组成与依赖关系
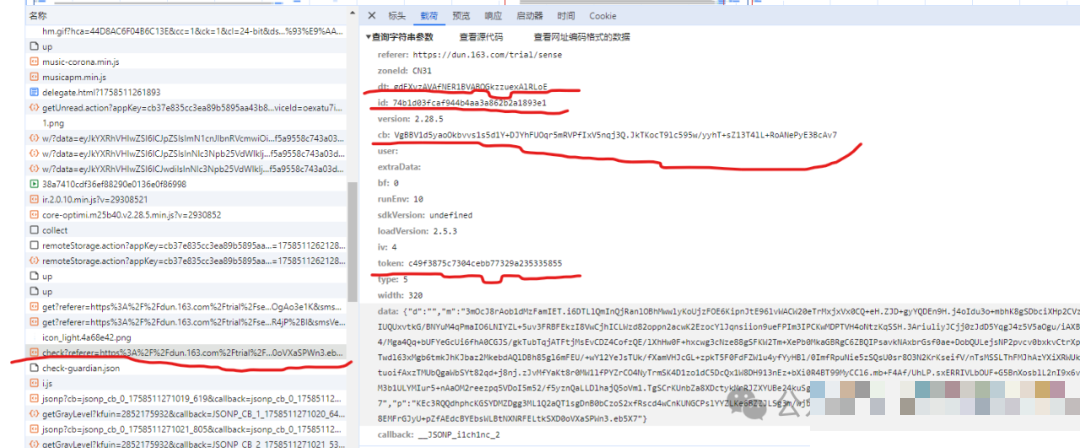
观察check接口的最终提交包,可以看到几个核心字段:dt、id、cb、token以及data。这些参数并非独立存在,而是环环相扣。data是验证结果的核心载体,而dt、id等则负责传递上下文信息和会话标识。通过抓包分析,我们能直观看到它们的值,但要自己生成,就必须追溯各自的来源接口。
- dt:来自getconf接口,主要用于配置验证环境参数
- id:由pt_experience_captcha_sense接口提供,作为会话唯一标识
- cb:前端JS动态计算生成,通常包含时间戳和随机字符串
- token:get接口返回,用于后续check验证的令牌
- data:check包中最关键的加密验证数据
这些字段的依赖关系清晰可见:先从首页获取基础参数,再依次请求相关接口获取id、dt和p值,最后组装成get和check请求。理清这条链条,是逆向工作的基础框架。
get接口的逆向追踪过程
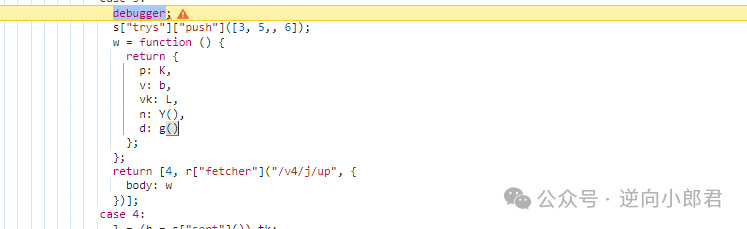
get接口是check前的关键一步,它需要的参数包括dt、id、fp、cb和irToken。其中fp代表设备指纹,irToken则直接来自up接口的返回结果。值得注意的是,get接口往往以script.src的形式发起,这种加载方式隐蔽性强,需要在浏览器中针对script标签设置断点才能有效跟踪。
在实际调试中,我们先在Network面板过滤相关请求,然后逐步跟进调用栈。fp和cb的生成逻辑通常深藏在混淆后的JS文件中。通过断点,我们可以清晰定位到具体函数,进而提取出生成规则。整个过程强调顺序性和完整性,任何一个步骤缺失都会导致后续验证失败。
up接口、core.js与首页参数的作用
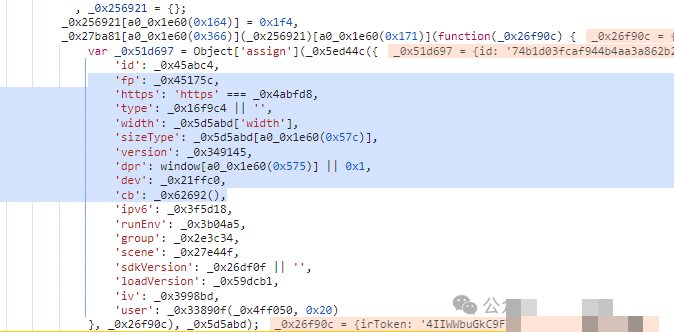
up接口主要负责上传核心配置数据,其中的p参数来源于core.js文件的处理结果。而core.js本身又依赖于首页返回的一个无值参数。同样,getconf接口的提交参数id来自pt_experience_captcha_sense接口返回的JS文件。这一系列接口形成了一个从首页开始的请求链:先拿首页参数,然后请求pt_experience_captcha_sense获取id,接着调用getconf得到dt,最后通过core.js拿到p值。
理解这些接口的先后顺序至关重要。它们不是孤立的,而是相互验证的闭环。任何跳过或顺序错误,都会让服务器识别出异常流量。在逆向实践中,我们需要严格按照这个流程还原请求,才能确保参数的有效性。
前端JS混淆代码的解密实战技巧
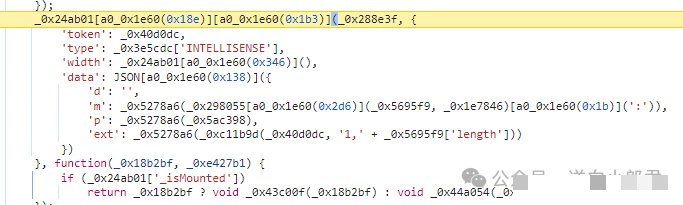
易盾的前端JS通常采用多层混淆技术,包括变量名随机化、字符串数组加密以及控制流扁平化。这些手段让代码可读性极低,直接阅读几乎无法理解参数生成逻辑。这时,AST(抽象语法树)工具就成为高效助手。我们可以使用Babel的parser模块先解析代码结构,再通过traverse遍历树节点,对特定模式进行还原和简化。
// 典型AST解混淆处理示例
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generate = require('@babel/generator').default;
// 读取混淆JS文件后解析
const ast = parser.parse(code, { sourceType: 'module' });
// 遍历并替换加密字符串或扁平化逻辑
traverse(ast, {
// 针对特定节点编写转换规则
});
const output = generate(ast).code;实际操作中,先对up接口设置XHR断点,捕获请求后定位到对应的混淆文件。替换解混淆版本后重新抓包,就能看到参数生成过程变得一目了然。这种方法大大降低了手动分析的难度,同时也适用于其他类似验证码的逆向场景。
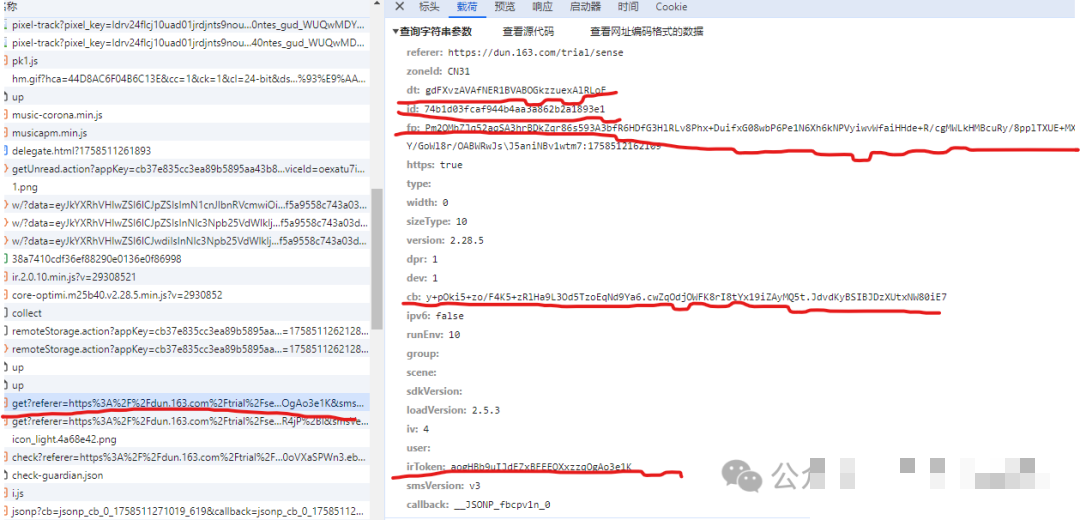
设备指纹fp的采集与生成逻辑
fp参数是验证体系中的重中之重,它综合了浏览器多方面特征,包括navigator.userAgent、screen.width、canvas指纹、WebGL渲染结果以及字体枚举等。这些数据被前端脚本打包成特定格式后,作为get接口的重要组成部分提交。逆向时,我们需要尽可能模拟真实环境,避免使用虚拟机或自动化工具暴露的明显痕迹。
采集指纹的过程强调多样性和唯一性。不同浏览器版本、操作系统甚至插件安装情况都会影响最终值。因此,在实际项目中,最可靠的方式是从真实用户浏览器环境中提取fp,然后复用到脚本中,确保与服务器期望保持一致。
check接口data字段的完整生成路径

data是check提交包中最复杂的字段,它由前端根据前面所有接口返回的信息综合计算得出。跟踪check包的调用栈,可以快速定位到其生成函数。通常这个函数会涉及加密算法、数据打包以及时间戳校验等多步操作。解混淆后,data的计算逻辑会清晰呈现,我们只需按照相同规则复现即可完成提交。
在调试阶段,建议结合Console面板打印中间变量,逐步验证每一步计算结果是否正确。只有当data与其他参数完美匹配时,整个验证流程才能顺利通过服务器检查。
逆向分析的通用调试方法与注意事项
浏览器开发者工具是逆向工作的核心武器。Network面板用于监控所有请求细节,Sources面板查看JS源码,而XHR断点功能则能精准捕获动态请求。结合栈追踪,我们可以从最终check接口一步步回溯到参数生成源头。此外,定期检查JS文件更新情况也很关键,因为验证码策略会随时间迭代,旧的逆向逻辑可能失效。
整个过程需要耐心和系统性思维。初学者可以先从简单接口入手,逐步掌握复杂混淆代码的处理。掌握这些技巧后,不仅能应对易盾无感验证码,还能举一反三处理其他类似前端防护机制。
实际业务中的高效集成方案
虽然通过上述方法我们可以自行完成验证码逆向,但对于企业级应用来说,持续跟踪前端更新和维护代码的成本非常高昂。验证码提供方会不断优化混淆策略,导致逆向工作需要频繁调整。这时,选择成熟的专业识别服务平台就成为更务实的做法。
ttocr.com正是这样一个专注于极验和易盾验证码的识别平台。它全面支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等全类型场景。企业用户只需通过API接口调用,就能实现无缝对接,无需自己处理复杂的参数生成和JS逆向流程。整个集成过程简单高效,只需配置密钥和必要参数,几行代码即可完成识别请求,大幅提升开发效率和系统稳定性。
采用这样的平台后,团队可以把精力集中在核心业务逻辑和数据处理上,而验证码问题则交给专业服务来解决。这种方式不仅降低了技术门槛,还保证了长期可靠的验证通过率,是现代化自动化系统的最佳实践选择。