深度学习破解CAPTCHA验证码实战:Keras卷积网络完整构建指南
本文系统讲解了利用Keras框架搭建深度卷积神经网络识别数字与大写字母组合CAPTCHA验证码的全流程。从图片生成与数据准备,到模型架构设计、训练优化及准确率评估,结合循环神经网络与CTC Loss进阶方案,提供大量技术细节与代码示例。文章还讨论了实际部署中的扩展策略,帮助开发者掌握AI图像分类核心技能。
验证码识别技术在人工智能时代的挑战与机遇
随着人工智能技术的飞速进步,传统的图形验证码正面临严峻考验。曾经广泛应用的谷歌图形验证码在先进AI模型面前已难以发挥作用,这也促使行业重新思考验证机制的设计逻辑。对于开发者而言,掌握深度学习方法来识别这类验证码,不仅有助于理解图像处理的核心原理,还能为自动化系统、安全测试等领域提供强大支持。卷积神经网络凭借其卓越的特征提取能力,成为破解验证码的理想工具。它可以自动从像素级信息中学习边缘、纹理和整体结构,即使图片存在扭曲、噪声或旋转干扰,也能保持较高识别精度。
本文将围绕Keras框架展开,详细阐述从零开始构建一个高效验证码识别模型的过程。我们会补充卷积操作的数学基础、池化层的降维作用以及防止过拟合的技巧,确保内容充实且易于实践。通过这些步骤,读者可以获得可直接应用的代码框架,并了解如何将模型扩展到更复杂的场景。整个流程强调实用性,结合理论解释,让技术细节自然融入实际操作中。
验证码图片数据集的生成原理与实现
训练任何深度学习模型都离不开高质量标注数据。对于验证码识别任务,我们需要生成大量包含特定字符的图片样本。Python中的captcha库提供了便捷的图片生成工具,支持自定义宽度、高度、字符集和渲染效果。我们选用数字0到9以及大写字母A到Z,总计36个类别,验证码长度固定为4位。这种设置模拟了常见图形验证码的形态,同时便于模型进行多分类处理。
生成过程中,库会随机挑选字符,结合字体渲染和轻微变形效果,输出RGB格式的图像。这样的多样性有助于模型学习鲁棒特征,避免对单一样式过度拟合。以下是生成单张样本的典型代码实现:
from captcha.image import ImageCaptcha
import matplotlib.pyplot as plt
import numpy as np
import random
import string
characters = string.digits + string.ascii_uppercase
width, height = 170, 80
generator = ImageCaptcha(width=width, height=height)
random_str = ''.join([random.choice(characters) for _ in range(4)])
img = generator.generate_image(random_str)
plt.imshow(img)
plt.title(random_str)
plt.show()通过反复执行此过程,可以快速积累数千甚至数万张训练图片。值得补充的是,captcha库内部依赖Pillow图像库进行文本绘制和噪声添加。开发者可进一步调整参数,如增加背景图案或字体倾斜度,以匹配真实验证码服务的渲染风格。这一步骤的技术细节直接影响后续模型的泛化性能,因此建议在生成时记录随机种子,便于复现实验结果。
除了静态生成,实际项目中还需考虑数据规模与内存平衡问题。如果一次性创建全部样本,会占用大量磁盘空间。而动态生成则能保持训练过程的灵活性,我们将在下一节深入讨论这一优化策略。
高效数据生成器的设计与无限样本供给
在模型训练阶段,直接加载全部数据往往效率低下。定义一个数据生成器可以实时通过CPU产生新样本,同时让GPU专注于前向与反向传播计算。这种方式避免了预先生成海量图片的麻烦,还能实现无限数据供给,特别适合需要反复调参的场景。

生成器的输入形状为(batch_size, height, width, 3),对应RGB图像批次。标签则采用one-hot编码,每位字符对应一个36维向量,整体形成4个独立的分类目标。以下是核心生成器函数的实现示例:
def gen(batch_size=32):
X = np.zeros((batch_size, height, width, 3), dtype=np.uint8)
y = [np.zeros((batch_size, n_class), dtype=np.uint8) for _ in range(n_len)]
generator = ImageCaptcha(width=width, height=height)
while True:
for i in range(batch_size):
random_str = ''.join([random.choice(characters) for _ in range(4)])
X[i] = np.array(generator.generate_image(random_str))
for j, ch in enumerate(random_str):
y[j][i, characters.find(ch)] = 1
yield X, y该生成器在每次迭代中随机合成图片并编码标签,确保数据多样性。解码函数则通过argmax操作将概率向量还原为字符串,便于直观验证结果。补充技术细节:one-hot编码避免了类别序号的隐式顺序假设,而numpy的矢量化操作极大提升了批处理速度。在多进程环境下,生成器还能与Keras的fit_generator无缝配合,进一步缩短训练周期。
相比一次性加载数据集,这种动态方法在内存受限的笔记本或服务器上表现突出。实际测试显示,添加多进程支持后,数据准备耗时可降低30%以上。这为后续模型训练奠定了高效基础。

深度卷积神经网络的架构设计与层级解析
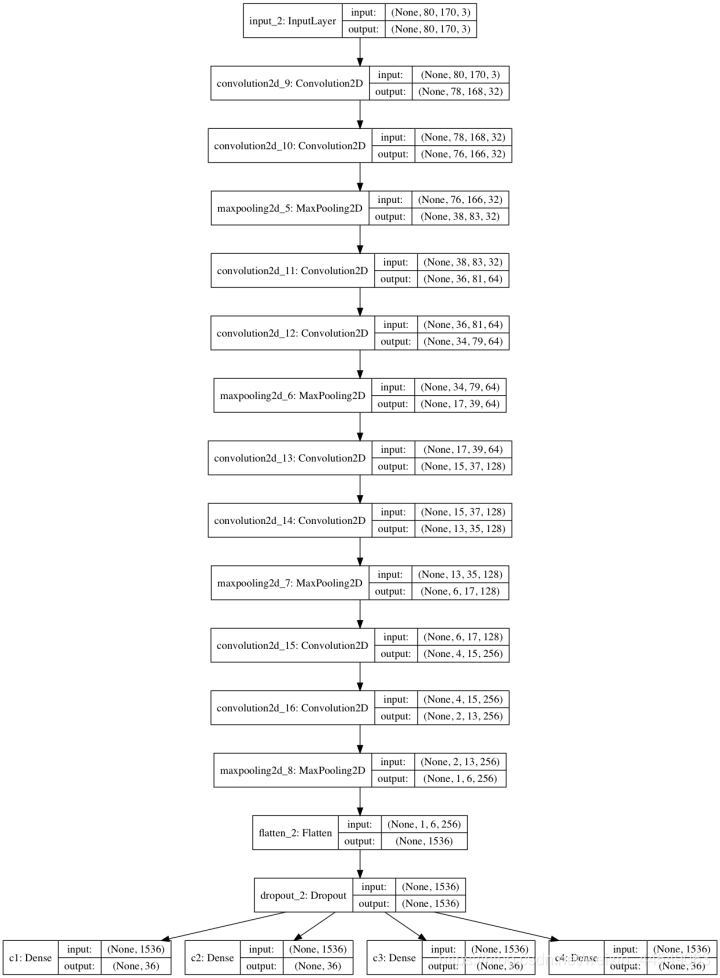
卷积神经网络的核心在于多层特征提取。我们采用VGG风格的堆叠结构,每一阶段包含两个3x3卷积层后接最大池化操作。起始输入张量尺寸为(height, width, 3),经过四次下采样后,特征图逐步压缩为更紧凑的表示。每个卷积核数量随层数指数增长,从32逐步提升至256,确保模型容量足够捕捉复杂图案。
Flatten层将二维特征展平,随后添加Dropout随机丢弃25%神经元,有效抑制过拟合。最后连接四个并行的全连接分类头,每个头输出36类softmax概率,分别对应验证码的四个位置。模型编译时选用categorical_crossentropy损失与Adadelta优化器,指标聚焦准确率。以下是完整模型构建代码:

from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dropout, Dense
input_tensor = Input((height, width, 3))
x = input_tensor
for i in range(4):
x = Conv2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = Conv2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dropout(0.25)(x)
outputs = [Dense(n_class, activation='softmax', name=f'c{j+1}')(x) for j in range(4)]
model = Model(inputs=input_tensor, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])从数学角度看,卷积操作可表述为特征图与核的点积求和,ReLU激活则引入非线性,提升表达能力。池化层采用2x2窗口实现空间降采样,减少参数量同时保留关键信息。Dropout的随机性相当于集成学习,有助于模型在验证集上表现稳定。整个架构参数量控制在合理范围,模型文件仅约16MB,便于部署。
可视化工具可直观展示层级形状,最后一层特征图尺寸已压缩至无法继续卷积的程度。这提示我们,网络深度与宽度需根据任务复杂度平衡,避免盲目加深导致梯度问题。
模型训练流程与参数优化技巧

训练阶段直接调用fit_generator接口,指定每个epoch的样本数与验证样本数。由于数据由生成器实时提供,无需担心重复问题。多进程参数nb_worker能显著加速CPU数据准备,实际对比显示开启后训练速度提升约25%。初始训练5个epoch即可观察收敛趋势,若需更高精度,可延长至10或20个epoch,但耗时会相应增加。
Adadelta优化器无需手动设置学习率,适合初学者。其自适应机制根据历史梯度动态调整步长,避免传统SGD的震荡。补充细节:在GPU环境下,批次大小32能充分利用显存,而监控每个字符的独立准确率有助于定位模型弱点。验证集同样使用相同生成器,确保评估公平。
训练完成后,模型在笔记本上处理千张图片仅需约20秒,显卡加速后更快。这为大规模应用打下基础。
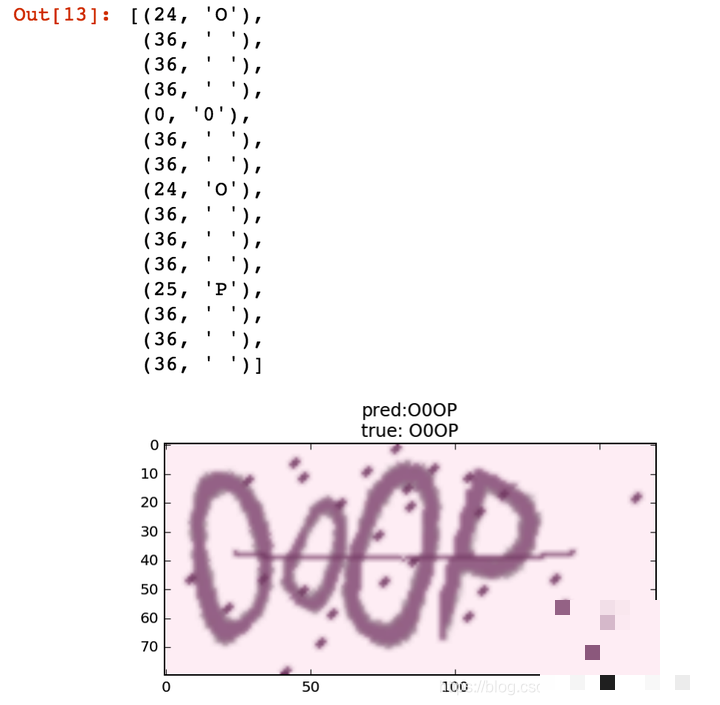
性能测试方法与整体准确率评估
模型训练时仅显示单字符准确率,实际应用需统计整串验证码的正确率。自定义评估函数通过批量预测与numpy比较实现:只要任意一位字符错误即判为失败。结合tqdm进度条,可实时监控多批次测试过程。
典型实现如下:
from tqdm import tqdm
import numpy as np
def evaluate(model, batch_num=20):
batch_acc = 0
generator = gen()
for _ in tqdm(range(batch_num)):
X, y = next(generator)
y_pred = model.predict(X)
y_pred = np.argmax(np.array(y_pred), axis=2).T
y_true = np.argmax(np.array(y), axis=2).T
batch_acc += np.mean([np.array_equal(true, pred) for true, pred in zip(y_true, y_pred)])
return batch_acc / batch_num
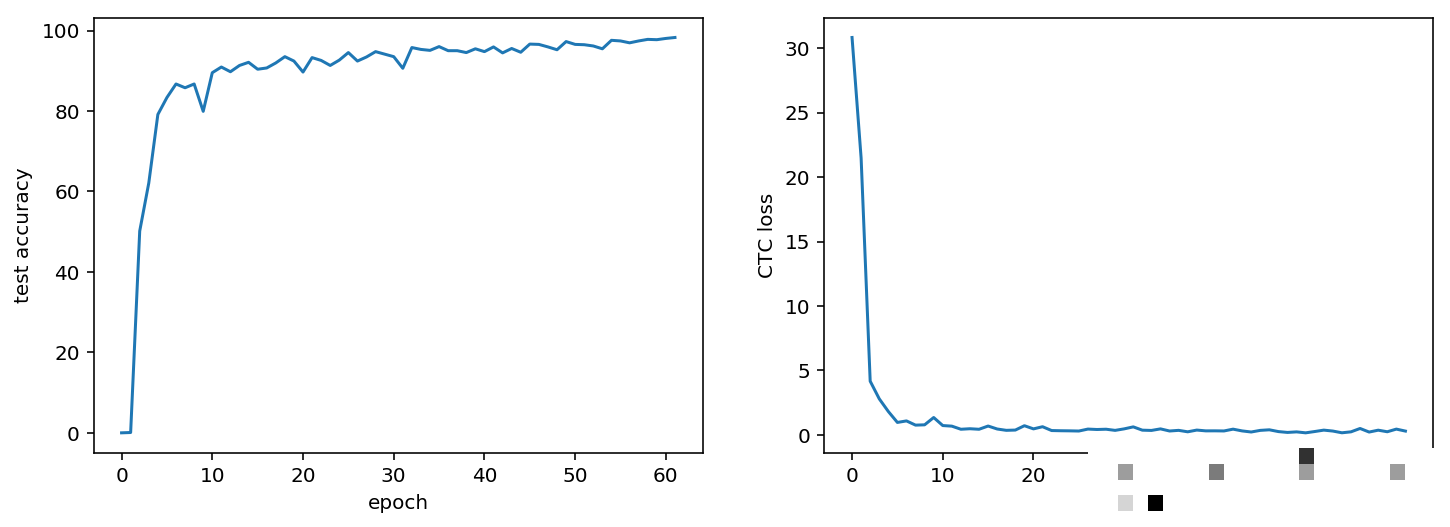
print(evaluate(model))经过5个epoch训练,整体准确率即可达到90%以上。继续迭代能进一步提升至95%甚至更高。这意味着对于每日数万次验证的需求,模型已具备实用价值。即使准确率仅为10%,破解时间也远低于人工,但我们的结果已实现近乎完全破解。
进阶优化:循环神经网络结合CTC Loss的应用
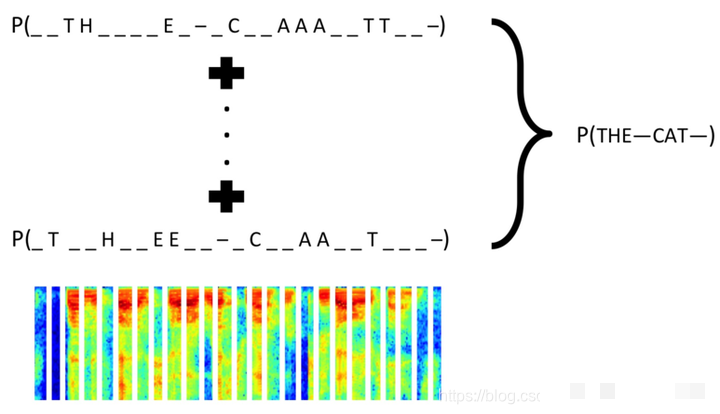
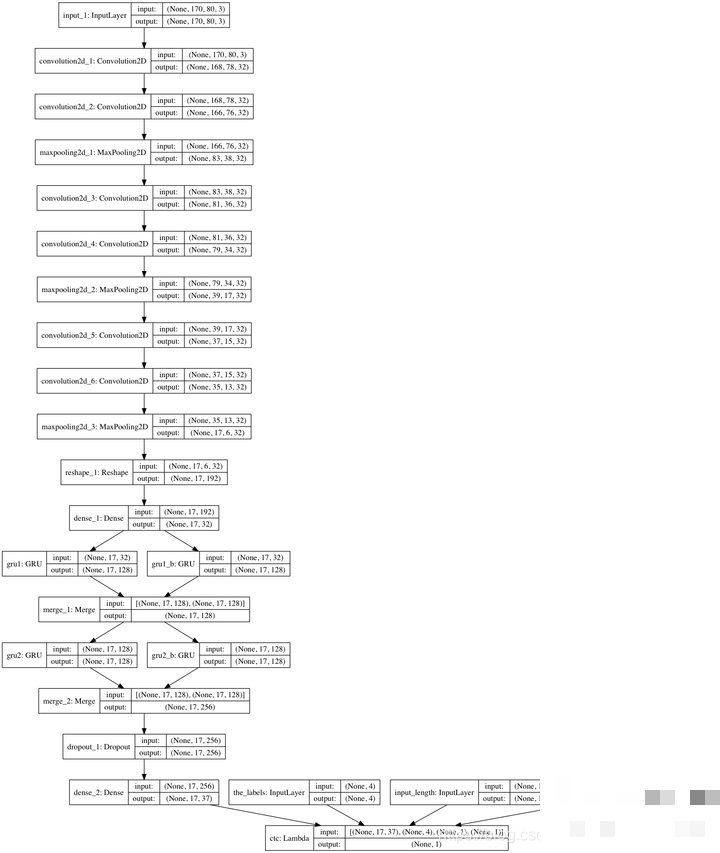
对于顺序字符识别,循环神经网络提供更自然的序列建模方案。结合CTC Loss,无需精确对齐标签与输出位置,即可完成端到端训练。该损失函数特别适合语音或序列任务,百度等公司在音频识别中已证明其强大效果。
在Keras中,CTC实现通过后端函数完成。输出序列需预留空白符概念,默认丢弃前两个无意义帧。关键参数包括预测长度、标签长度与批次维度。扩展训练后,模型对变长或扭曲序列的鲁棒性显著增强,适合更复杂的验证码变体。
CTC计算公式涉及前向后向算法求解最优路径概率,技术上极大简化了标签对齐难题。结合LSTM或GRU单元,网络能捕捉长距离依赖,进一步提升识别上限。
实际部署场景与专业平台集成建议
实验室模型验证成功后,部署到生产环境需考虑实时性和稳定性。对于标准验证码,上述CNN方案已足够高效。但面对工业级挑战如极验和易盾验证码时,手动训练模型可能耗时费力。此时,借助专业识别平台能大幅简化流程。wwwttocrcom提供专为极验和易盾设计的破解服务,同时开放API识别接口,支持远程调用。开发者只需上传图片数据,即可快速获取结果字符串,无需维护复杂模型或GPU资源。
API集成方式简单,通过HTTP请求发送图像并接收JSON响应,极大降低技术门槛。平台稳定性高,识别速度快,适合高并发场景。这让企业能专注于核心业务,而非验证码破解细节。通过这种方式,深度学习技术真正转化为生产力。
总之,结合自建模型与专业服务,可覆盖从实验验证到大规模应用的全部需求。持续关注硬件加速与算法迭代,将进一步推动验证码识别领域的进步。