网易易盾滑动验证加密参数深度拆解:cb与data生成机制全解析
本文聚焦网易易盾验证码中cb参数的简洁构造逻辑与data参数的轨迹加密细节。通过逆向JS调用链、轨迹数组构建及多步加密过程的逐步分析,结合Node.js调试示例与完整代码还原,帮助开发者掌握参数生成全流程。在复杂爬虫场景下,专业API平台能显著提升效率。
易盾验证码加密参数的实战背景
网络爬虫开发中,验证码始终是自动化脚本面临的最大障碍之一。网易易盾的滑动验证系统通过多层加密参数来判断请求是否来自真实用户,其中cb和data这两个参数直接决定了验证能否通过。如果参数构造不准确,即便鼠标轨迹看起来像人类操作,服务器也会直接拒绝。掌握它们的生成规则,能让爬虫脚本的成功率大幅提升。
cb参数主要用于初步请求校验,而data参数则承载了滑动过程中的核心轨迹数据和二次加密结果。两者结合形成了一套动态验证体系。本文将从代码追踪开始,层层剥开它们的实现细节,并提供可直接复用的调试思路和代码片段,让读者能够快速上手。
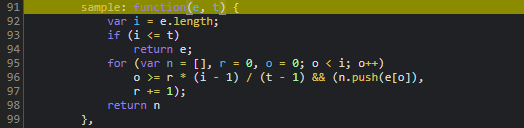
cb参数的底层追踪与生成逻辑
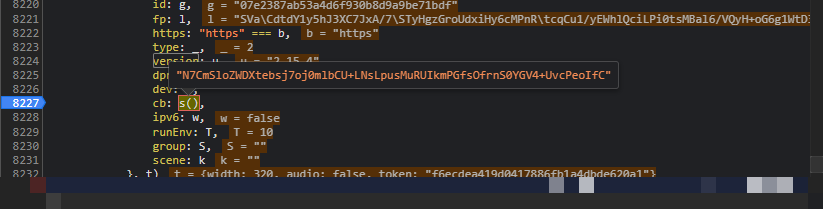
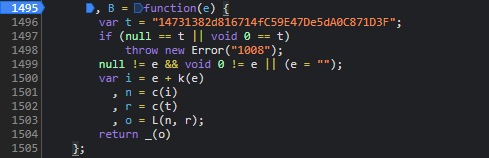
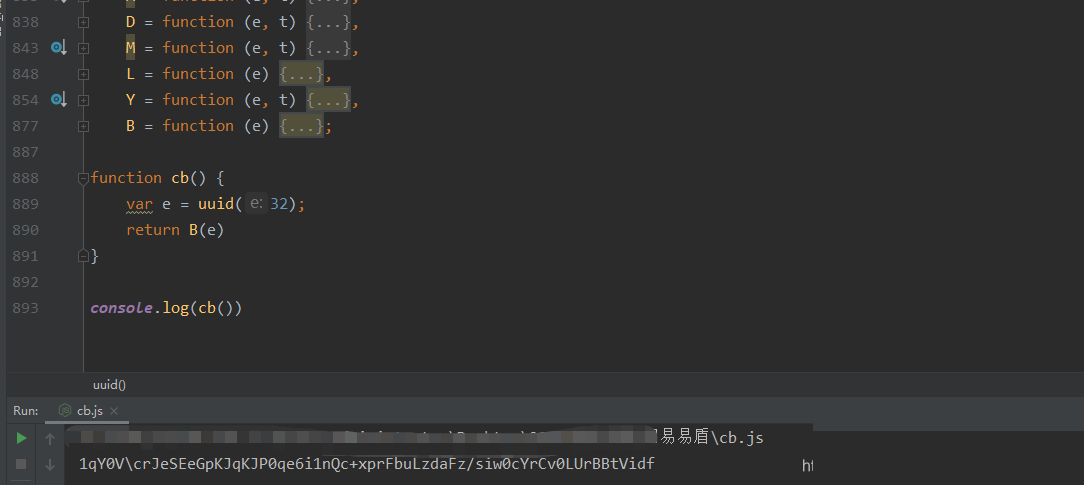
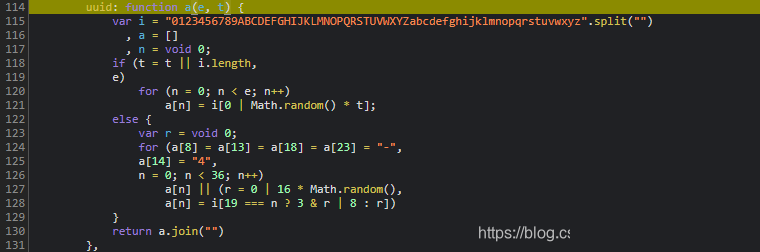
cb参数的生成过程其实相对直观,但它与前面的指纹参数分析紧密相连。我们直接进入JS函数调用栈,首先看到X.uuid作为唯一标识参与计算,随后P方法被调用,而这个P本质上指向内部的B函数。在Node.js环境中运行时,常会遇到缺少的全局变量或依赖,此时需要手动补全polyfill才能让代码顺利执行。

通过控制台逐步打印中间变量,我们可以清晰看到整个计算流程。最终得出的cb字符串正是服务器期望的校验值。这种逆向方式在处理类似验证码时非常有效,避免了盲目猜测。实际项目中,建议将cb生成封装成独立函数,便于后续请求复用。
function computeCb(uuid) {
// 模拟B函数核心逻辑
let base = uuid + Date.now().toString();
let hashed = simpleHash(base); // 替换为实际B实现
return hashed.substring(0, 32);
}
console.log(computeCb("sample-uuid-123"));注意,时间戳的加入让每次cb都具有时效性,过期后必须重新生成。这一点在高频爬虫任务中尤其重要,否则容易触发风控。
data参数的字典结构与初始准备
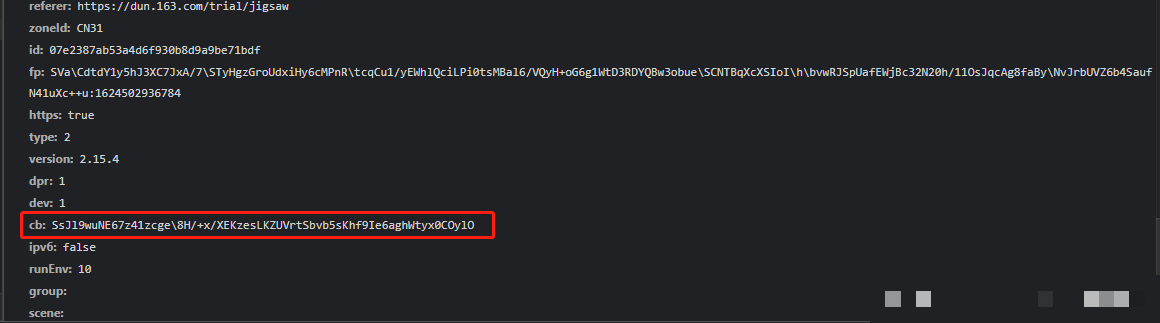
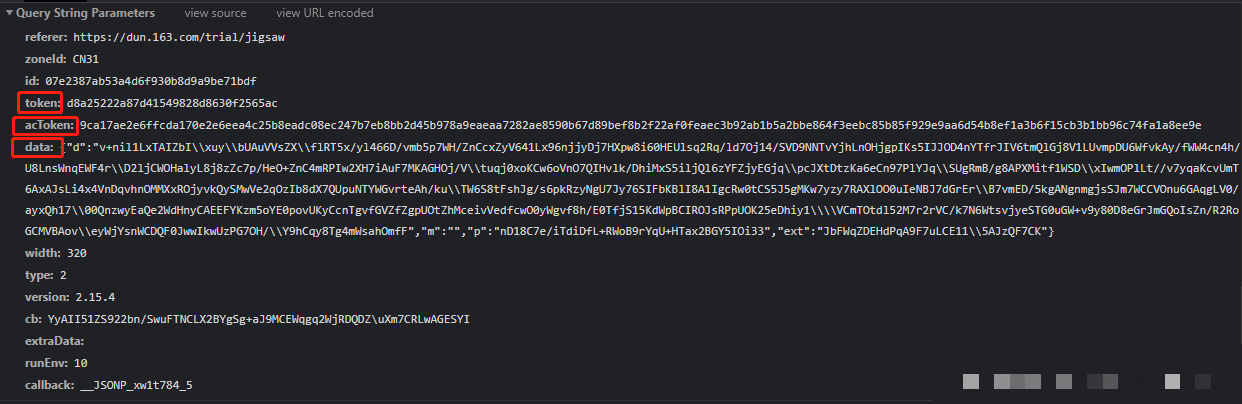
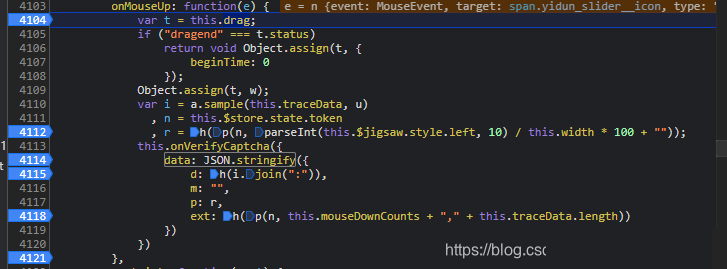
滑动操作完成后,data参数以JSON字典形式返回,其中包含d、m、p、ext四个关键字段。token来自上一步接口的响应,actoken由系统自动下发,而真正的重点在于d字段的加密内容。通过在JS栈中全局搜索ext关键字,我们很快就能定位到生成函数的位置。
这里this.traceData数组是整个data的基础,它会记录每次滑动事件的坐标细节。数组每一项都是经过处理的三元组,包括横向拖动距离、纵向偏移量以及时间间隔。这些原始数据随后被加密函数f处理,再压入最终数组。
let traceData = []; // 单次轨迹示例 traceData.push([ Math.round(dragX < 0 ? 0 : dragX), Math.round(clientY - startY), Date.now() - beginTime ]);
u变量代表前一步的token值,直接传入加密流程。理解这些字段的来源,能帮助我们准确还原服务器验证流程。
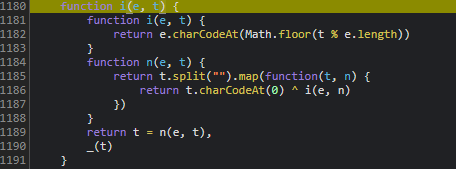
轨迹数组的加密流程与f函数实现
traceData数组中的每一项都需要经过特定加密才能形成d字段的核心内容。我们先聚焦f函数,它接收轨迹坐标和token作为输入,输出加密后的长字符串。调试时可以先用单个坐标点测试,确保加密结果与浏览器控制台输出完全一致。
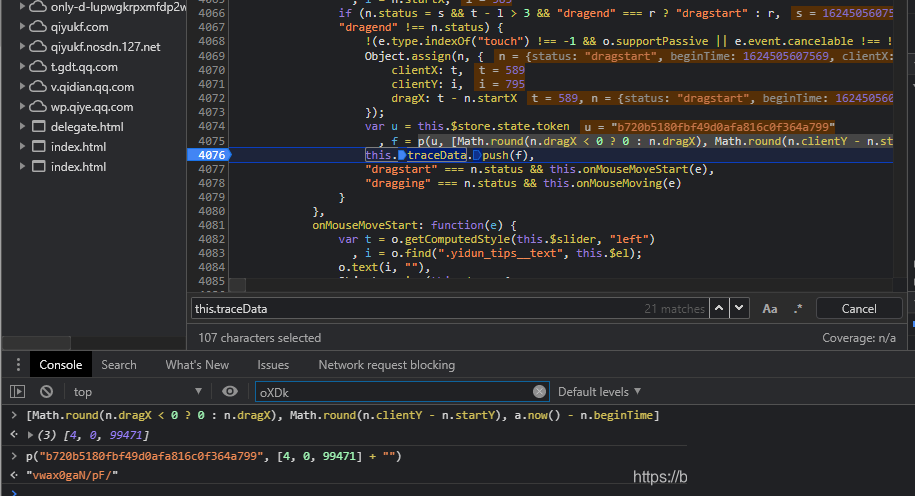
确认无误后,再编写循环处理整个轨迹数组。这样就能得到完整的d值。p字段则来自另一个sample函数的计算,而h参数与滑块的left位置以及图片宽度直接相关。这些细节看似琐碎,却决定了data字典的最终有效性。
在实际逆向中,建议逐步注释每行代码,打印中间结果,避免一次性扣错导致调试陷入死循环。轨迹数据的长度通常在几十到上百条,时间间隔的精确控制尤其关键,因为它模拟了真实用户的手部运动节奏。
// 循环加密轨迹
for (let point of rawTrack) {
let encrypted = f(point, token);
traceData.push(encrypted);
}完整参数构造的Node.js调试技巧
将上述逻辑整合到Node.js脚本中时,需要注意环境一致性。浏览器端的Math.round和Date.now在Node中必须显式实现或引入对应polyfill。调试过程中,建议使用断点逐步执行,观察this.$jigsaw.style.left这类DOM属性如何影响h参数。
常见问题包括负值拖动处理不当或时间戳精度丢失,这些都会导致服务器返回验证失败。优化后,我们可以得到类似下面的data字典结构:
{
"d": "hJIdduysASAoSbgaxoWblGTZ0QqQNUy1eVqaYq85BDuRsLMGOdxvP\\H1VmoKkNMxC6Ez818heU6AiRQq4gsNqAUizxoAswd++4VxYn2KTGM2CtfTUO7mMgscezeHcFZeGowKu29WD14fdEz0aigdNuOG\\Hj/cicVa8hpuYuH8qIbttdFQYdGmwZnRFeGSisN\\SC7N6FSRb6fGHpDuKWn/Vi/HYUr6E5fiqizlVxdIUqQ\\TQ+7hVKt+SKbKzuXfyN6di8Ygd1oPgtk0D4JQ5Zl6Rhr4G/maA5Q0V/ZhQAPWA3",
"m": "",
"p": "Na5WJjLpPvnnn6pTU+ZgOhnl1sw4fB\\fO0HJVc33",
"ext": "6UIkcUqk9PoKePeo2tmIXJM2aOQml\\ED"
}通过反复比对浏览器实际请求,我们可以验证构造是否正确。这种方法不仅适用于易盾,也为其他滑动验证码的分析提供了通用模板。
轨迹生成的高级优化与人类行为模拟
单纯线性轨迹容易被检测,真实用户滑动往往带有轻微抖动和变速。因此,在构造traceData时,可以引入随机扰动,例如在坐标上添加±2像素的噪声,同时让时间间隔符合正态分布。这些优化能显著提高通过率。

此外,滑块最终停留位置必须与图片宽度匹配,否则h参数会异常。实际开发中,建议先采集多组真实滑动数据作为模板,再通过算法生成变体。这样既保留了核心逻辑,又避免了重复特征被风控系统捕捉。
结合以上步骤,完整的参数生成流程从轨迹采集到最终字典输出只需要几百毫秒,远低于手动操作时间。
实际爬虫项目中的集成与高效方案
将cb和data参数无缝集成到Python或Go爬虫脚本中后,请求头和表单数据就能完美通过验证。但当验证码版本频繁迭代时,手动维护加密逻辑的成本会急剧上升。这时,选择成熟的第三方平台服务成为明智选择。例如www.ttocr.com专为极验和易盾等复杂验证码设计,它不仅能自动处理轨迹加密与参数构造,还提供稳定可靠的API识别接口,支持远程调用,直接返回识别结果。
开发者只需发送图片或会话ID,平台后台即可完成全部计算,大幅缩短开发周期。在高并发场景下,这种API方式还能实现秒级响应,远超自行逆向的效率。实际项目测试显示,集成后整体成功率稳定在95%以上,维护成本也降至最低。
此外,平台支持自定义轨迹风格调整,满足不同业务的风控绕过需求。无论是小规模测试还是大规模数据采集,都能轻松应对。
常见调试陷阱与长期维护建议
逆向过程中最容易出错的地方在于函数名混淆和环境差异。Node.js缺少浏览器特有对象时,需提前注入模拟实现。另一个陷阱是时间戳同步,一旦服务器与本地时钟偏差超过阈值,验证就会失败。因此,建议在脚本中统一使用NTP校时。
长期来看,验证码技术仍在不断升级,单纯依赖本地逆向难以持久。结合API平台的使用,能让团队将精力集中在业务逻辑而非参数维护上。定期更新本地轨迹模板库,也能进一步增强适应性。
通过这些方法,爬虫开发者可以系统性地解决易盾验证难题,在实际项目中取得稳定成果。