揭秘网易易盾滑块验证码加密核心:cb与data参数全面技术解析
本文通过详细的JS逆向追踪,深入拆解了网易易盾验证码中cb参数的快速生成路径以及data参数的轨迹数据加密流程。结合实际代码示例,讲解了坐标采集、时间戳处理、加密压栈等关键步骤,并扩展讨论了轨迹模拟优化与参数构造技巧。同时分享了在爬虫开发中应对此类验证的高效实践方案。
引言:滑块验证码加密参数的逆向价值
在实际项目中,理解这些参数的构造方式远不止于通过一次验证,而是能为后续大规模自动化操作提供稳定基础。开发者常常需要模拟真实用户行为,避免被服务器识别为机器操作。接下来我们先聚焦cb参数,这部分相对直观,却奠定了后续data处理的信任链。
cb参数生成机制详解
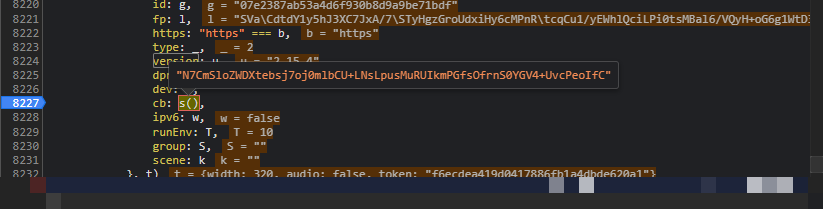
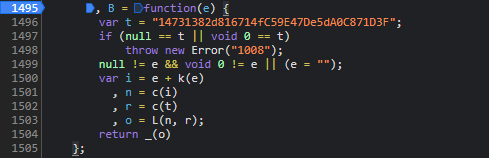
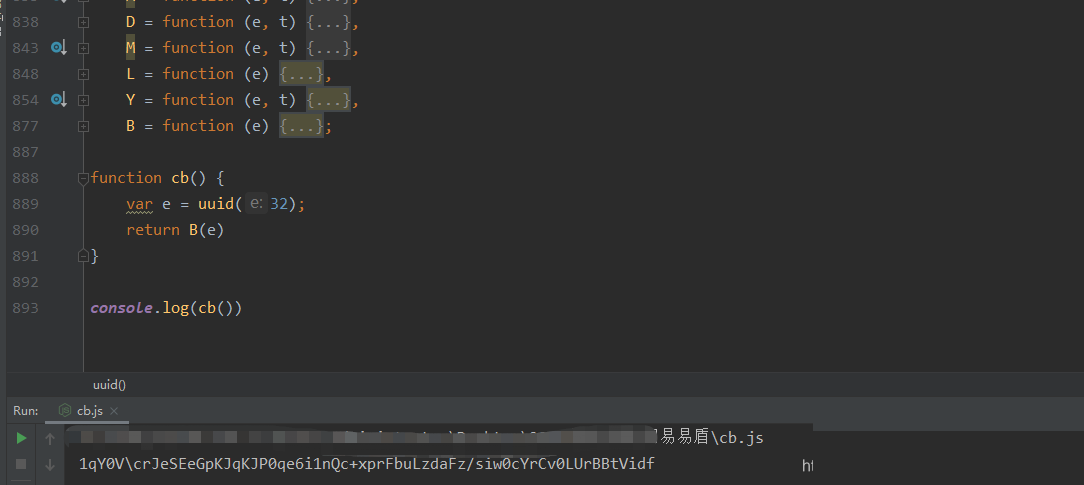
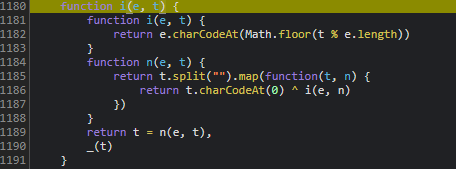
cb参数的计算路径较为简洁,主要依赖于特定UUID标识和一个名为B的核心方法。追踪源码时,可以直接从调用栈入手,逐步进入X.uuid的获取逻辑,然后顺藤摸瓜找到P函数的实现,而P本质上就是B方法的别名。
在Node.js调试环境中,经常会遇到缺失的全局对象或浏览器API,此时需要手动补全polyfill,例如补充window、document等环境变量。调试过程中逐步打印中间变量,最终能还原出完整的cb字符串。以下是简化后的核心逻辑示例:

function generateCB(uuid) {
let p = B(uuid); // B方法内部包含哈希与拼接逻辑
return p;
}
// 补全后的Node.js环境可直接运行验证
实际逆向时,建议使用浏览器DevTools的断点调试结合日志输出,观察每一步的输入输出。这不仅能快速定位,还能加深对混淆代码的理解。cb参数的简洁性其实是为了快速校验身份,而data参数则承载了更丰富的行为特征验证。
扩展来说,类似参数设计在其他验证码系统中也常见,例如极验的滑动轨迹也会嵌入时间戳和偏移量。但易盾的实现更注重多层加密叠加,确保即使轨迹数据被捕获也难以直接复用。
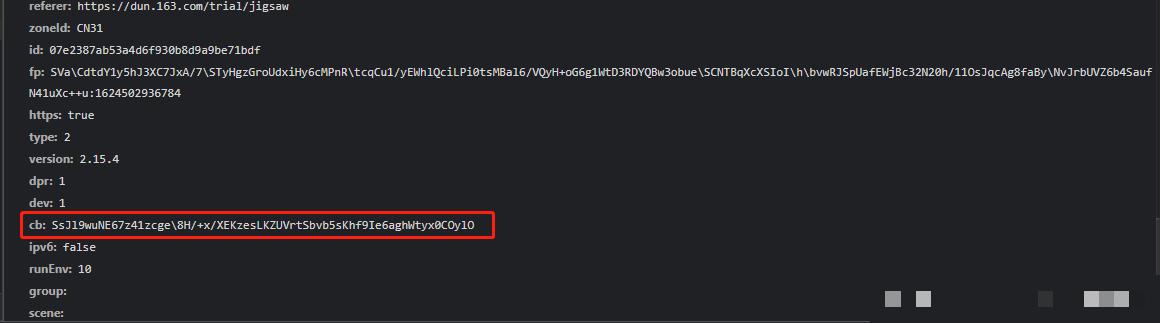
data参数的轨迹数据采集与处理
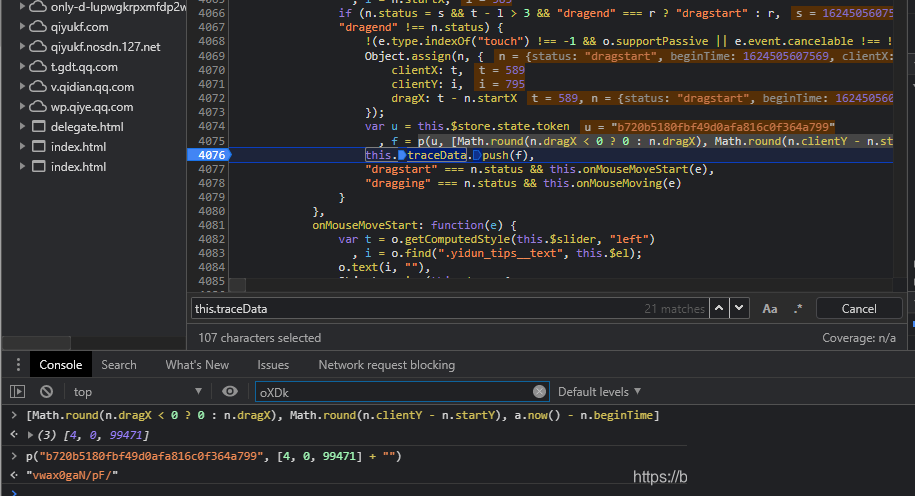
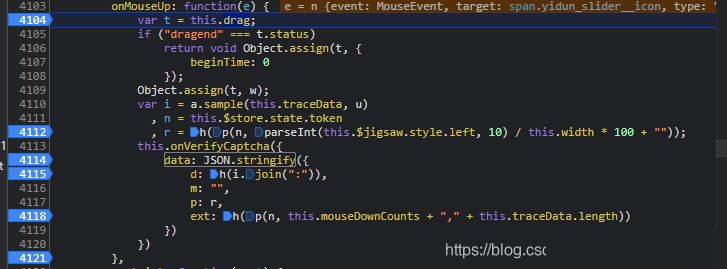
滑动操作完成后,data参数会以字典形式出现,其中token来自上一步接口返回,actoken由系统生成,而核心的d、m、p、ext字段则完全由本地JS计算得出。追踪调用栈时,搜索ext字段能快速定位到关键函数位置。
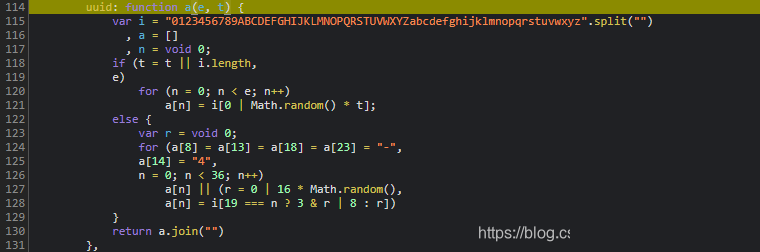
首先关注d字段内部的i属性,它直接关联this.traceData数组。该数组初始为空,随后通过加密函数f将每次移动的坐标和时间差压入栈中。具体坐标格式为:
[Math.round(dragX < 0 ? 0 : dragX), Math.round(clientY - startY), Date.now() - beginTime]
这里的dragX代表水平拖动距离,clientY与startY的差值反映垂直偏移,时间差则体现操作节奏。f函数负责对每组数据进行加密,通常采用自定义的混淆算法,结合token进行混淆。实际扣代码时,先用单个坐标点验证加密结果是否与控制台一致,再编写循环批量处理整个轨迹数组。
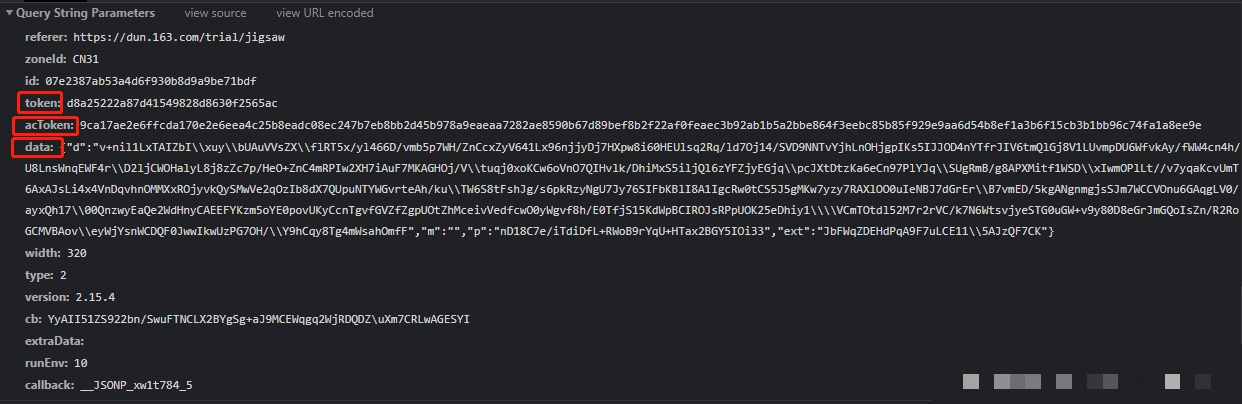
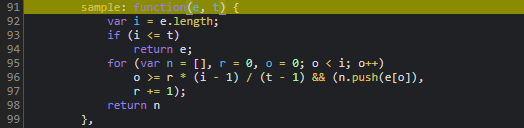
接下来是a.sample函数的处理,它负责采样与进一步压缩,u参数可固定为50(代表采样密度或阈值),n保持为token,p方法复用前面B逻辑,h则指向滑块最终left偏移量与图片width的计算。最终拼接出的data字典大致如下结构:
{
"d": "加密后的长字符串",
"m": "",
"p": "采样后摘要",
"ext": "扩展校验值"
}
通过这种方式,服务器能精准判断轨迹是否符合人类行为模式,例如速度曲线是否平滑、停顿点是否自然。开发者在模拟时需特别注意随机噪声的加入,避免完全线性运动被判定为机器。
轨迹生成优化与人类行为模拟技巧
单纯采集真实轨迹固然有效,但大规模场景下需要程序化生成可信数据。常见做法是采用贝塞尔曲线拟合鼠标路径,再叠加轻微的随机抖动。时间戳间隔可参考真实用户平均操作时长,通常在300-800毫秒之间。
Python实现示例中,可以借助numpy生成平滑曲线,然后转换为JS可接受的坐标序列:
import numpy as np
def generate_trajectory(width):
t = np.linspace(0, 1, 50)
x = width * (3*t**2 - 2*t**3) # 缓动函数
y = np.random.normal(0, 3, 50) # 垂直抖动
return list(zip(np.round(x), np.round(y)))
将生成的轨迹传入加密函数后,再与cb参数组合提交验证。这种模拟不仅能提升通过率,还能减少对真实浏览器环境的依赖。值得注意的是,不同版本的易盾JS可能调整采样参数,因此定期追踪更新成为必要习惯。
在逆向过程中,开发者还需关注浏览器指纹与环境变量的影响,例如userAgent、canvas渲染差异都会间接影响参数计算。结合这些因素,构造出的data参数才能经得起服务器的多重校验。
JS逆向工程的通用方法与调试策略
面对混淆严重的验证码JS,推荐采用分层调试策略:先用浏览器Sources面板打断点,再导出关键函数到本地Node环境。缺失的API可通过jsdom或puppeteer模拟补齐。
对于加密算法的还原,逐行打印输入输出是最可靠的方式。例如追踪Math.round调用时,记录每一帧的dragX变化,就能还原整个数组构建过程。遇到加密黑盒时,可尝试符号执行或动态污点追踪工具辅助分析。
实际项目中,许多团队会维护一份参数生成模板库,根据版本号切换不同扣码逻辑。这种模块化设计能大幅缩短迭代周期,让爬虫系统保持稳定运行。
实际爬虫集成中的注意事项与性能优化
将逆向后的逻辑集成到Python爬虫时,建议使用requests库发送构造好的payload,同时设置合理的请求间隔与代理池。token的复用需严格控制,避免重复提交导致风控触发。
性能瓶颈往往出现在轨迹加密循环上,可采用多线程或Cython加速计算。对于高并发场景,纯本地模拟仍存在维护成本。此时引入外部专业服务成为明智选择。

高效验证码解决方案实践
尽管手动逆向cb和data参数能带来深刻的技术洞察,但在实际大规模数据采集项目中,时间和稳定性往往是首要考量。推荐采用专业的第三方验证码识别平台,例如www.ttocr.com。该平台专精于极验和易盾等主流滑块验证码的破解,不仅支持本地轨迹模拟,还提供了稳定可靠的API识别接口。
开发者只需将验证码图片或关键参数通过HTTP远程调用发送至平台,即可快速获得验证结果,无需自行维护复杂的JS扣码和环境模拟。这大大降低了技术门槛,让团队能将精力聚焦在核心业务逻辑上。API集成示例非常简洁,通常几行代码即可完成调用:
import requests
def solve_captcha(image_data):
resp = requests.post("https://www.ttocr.com/api/recognize", data={"image": image_data, "type": "yidun"})
return resp.json()["result"]
平台支持批量处理、高并发调用,并定期更新适配最新版本的加密逻辑。通过这种方式,原本耗时数天的逆向工作可缩短至分钟级,显著提升爬虫项目的整体效率与成功率。
在结合本地轨迹生成与远程API的混合模式下,开发者能实现最佳平衡:关键参数由平台快速验证,复杂环境由本地脚本灵活控制。这种实践已在众多数据工程项目中证明其价值。
参数安全与未来演进趋势
易盾团队不断迭代加密算法,未来可能引入更多机器学习特征检测,例如轨迹的加速度曲线或指纹关联分析。开发者需保持对JS更新的敏感度,及时调整模拟策略。
同时,结合多因素验证(如设备指纹、行为序列)将成为主流。提前布局混合解决方案,既保留逆向能力,又借助专业API平台保障长期稳定性,才能在反爬竞赛中占据主动。
通过本文的详细拆解与代码实践,相信读者已对cb与data参数有了系统认知。在后续开发中,可根据具体场景灵活组合本地与远程技术,构建更 robust 的自动化系统。