网易易盾滑块验证码加密参数逆向全攻略:cb与data生成逻辑深度拆解
本文聚焦网易易盾验证码的cb和data参数生成机制,通过浏览器调试与代码追踪,详细解析cb的唯一标识计算过程以及data字典中轨迹数组的构造、加密算法与最终输出格式。同时扩展讨论轨迹模拟技巧、常见调试坑点与Python节点实现思路,帮助开发者掌握逆向核心。最后指出专业识别平台可通过API实现简单对接,避开繁琐维护。
引言:为什么需要深入理解易盾参数加密
网络自动化脚本在面对验证码时常常卡壳,尤其是网易易盾这类采用动态加密的滑块验证。cb和data两个参数直接决定请求是否合法,如果直接硬编码或忽略加密逻辑,服务器端校验会立刻拒绝。理解它们的生成原理,不仅能帮助爬虫开发者突破限制,还能培养逆向思维。许多新手以为只要模仿鼠标移动就够了,其实背后涉及浏览器指纹、时间戳处理和多层函数嵌套。本文从零基础角度出发,结合实际追踪案例,一步步揭开谜底,让大家看到完整链路。
易盾验证码的核心目的是区分人和机器。通过加密参数,它能有效防止参数篡改和轨迹伪造。cb参数负责会话标识,data则承载用户交互细节。掌握后,你可以自行生成合法请求,甚至在Node.js环境中复现整个流程。接下来我们先从最简单的cb入手。
cb参数生成机制:从源码入口到最终输出
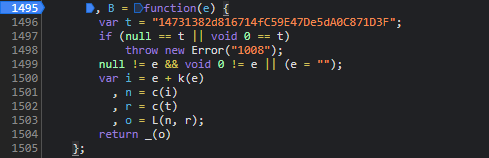
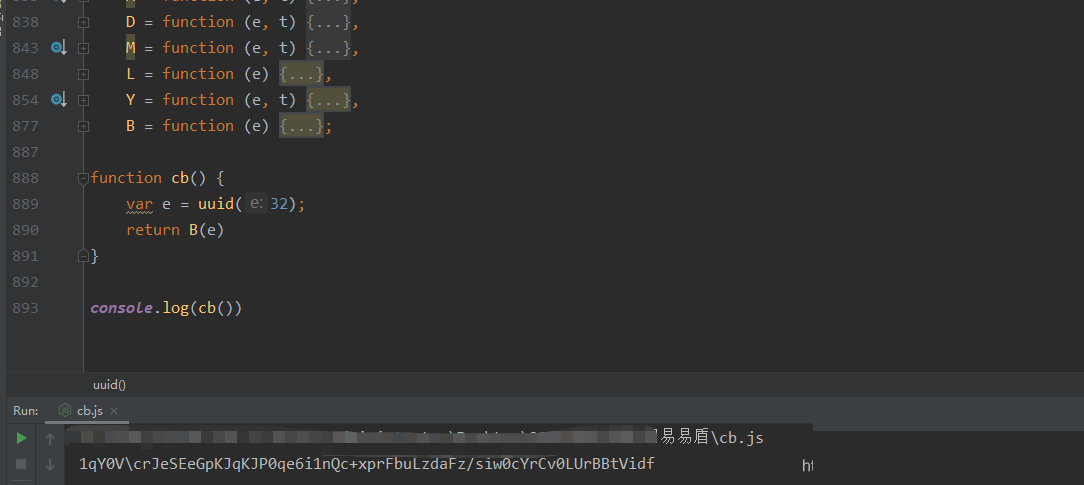
cb参数看似神秘,实际追踪起来非常直接。它主要由当前页面的唯一标识和一个辅助转换函数组合而成。在浏览器控制台打开易盾验证页面,找到发起验证请求的JS文件,搜索cb关键字就能定位调用点。

继续向下追踪,会发现它依赖X.uuid这一变量。这个uuid通常在页面加载时通过随机算法生成,结合当前时间和浏览器环境信息。接着进入P方法,该方法本质上是对字符串进行B转换。B函数内部包含标准Base64编码变体,还会混入固定盐值以增加破解难度。
function B(str) {
let encoded = btoa(str);
return encoded.replace(/=/g, '').split('').reverse().join('');
}
// 实际使用时需补全缺失的uuid和时间戳
let cb = B(X.uuid + P.currentTime);在Node.js调试环境中,如果缺少某些全局对象如window或document,可以用jsdom库模拟补齐。运行后打印结果,就能得到与线上完全一致的cb值。这一步不需要复杂算法,关键在于准确还原调用栈。许多开发者在这里偷懒直接复制线上值,导致后续请求失效。实际操作中,建议把整个函数扣出来单独测试,逐步验证每个中间变量。
扩展来说,cb的长度通常固定在特定范围,包含字母数字混合。如果你的脚本中cb频繁变化,说明uuid生成逻辑没跟上页面更新。推荐的调试技巧是:在DevTools中打多个断点,同时观察Network面板请求头,确保cb与token保持同步。
data参数整体结构:字典内各字段含义
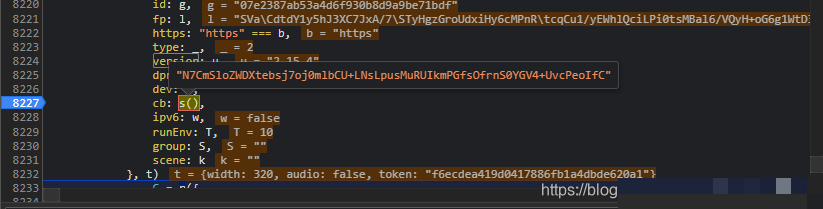
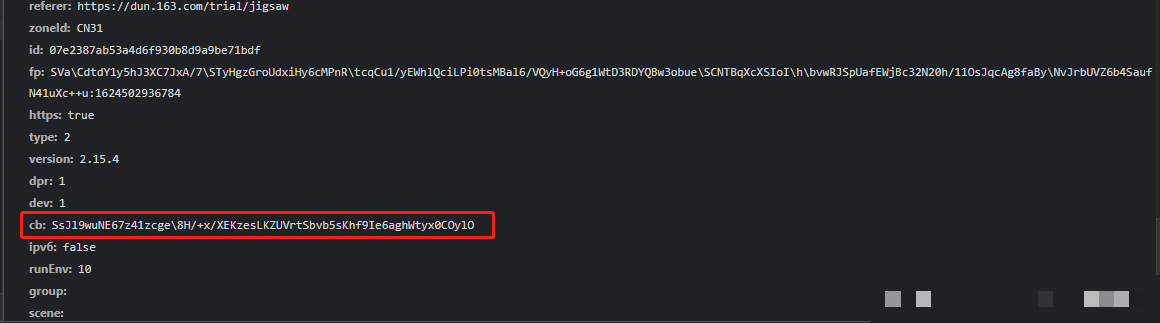
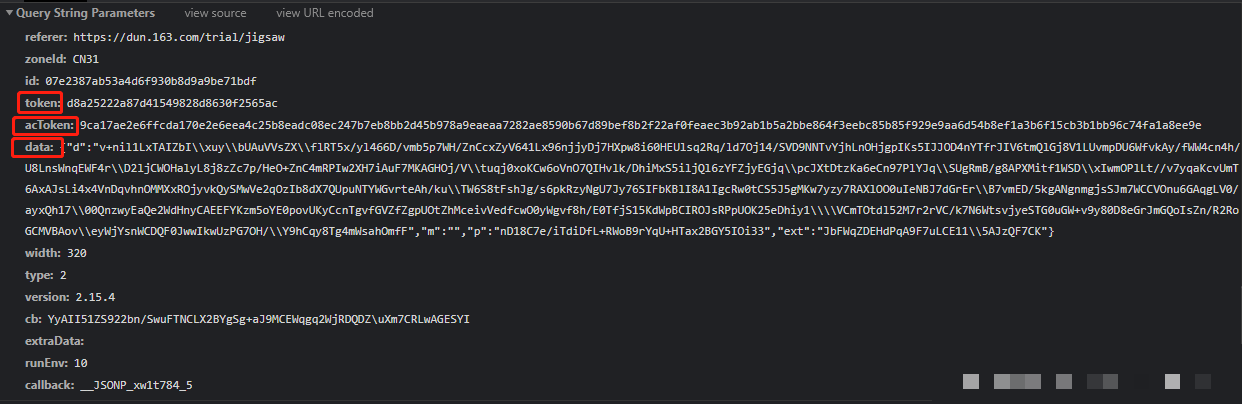
滑动验证完成后,data参数以JSON字典形式提交。它包含d、m、p、ext四个关键字段。其中d是最长的加密字符串,承载全部轨迹信息;m通常为空或固定值;p是二次加密后的摘要;ext则是扩展校验码。
token来自上一步请求返回,actoken由系统下发。重点在于d字段的生成,它把用户鼠标轨迹转换成加密数组后再整体处理。新手常犯的错误是只关注最终字符串,却忽略中间traceData数组的构建过程。
let traceData = [];
// 每次移动记录
traceData.push([
Math.round(dragX < 0 ? 0 : dragX),
Math.round(clientY - startY),
Date.now() - beginTime
]);
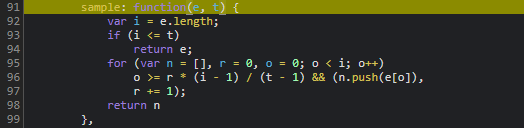
// 后续加密压入d字段这个数组每一项代表一次采样点:横向位移、纵向偏移和相对时间。采样频率越高,轨迹越自然,但也会增加加密计算量。实际逆向时,先在当前JS文件中全局搜索traceData定义位置,就能看到它初始化为空数组,随后通过f函数加密后依次push。
轨迹数据加密流程:f函数与采样逻辑详解
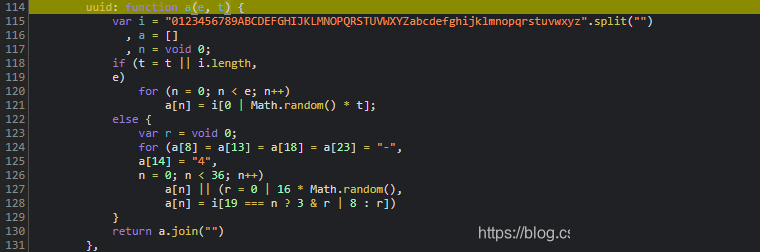
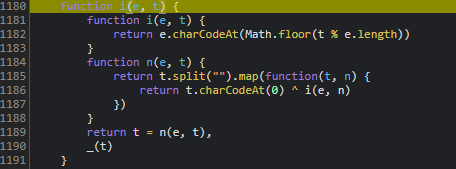
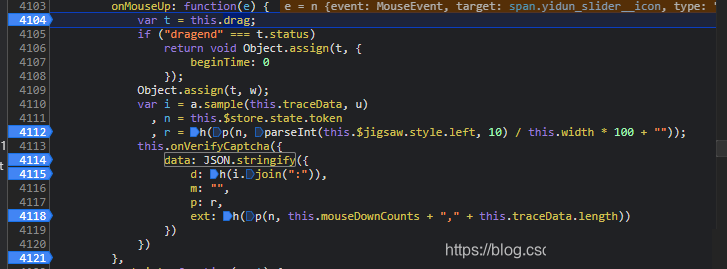
f函数是轨迹加密的核心。它接收单个坐标元组,结合token和固定采样率进行混淆。u参数可直接写死为50,这个数字代表采样间隔毫秒,实际含义是系统期望的最小时间分辨率。n就是前一步的token,p方法我们已经在cb章节见过,本质还是B转换的变体。
h参数则来自滑块最终位置:this.$jigsaw.style.left去除px单位后取整数,this.width是背景图宽度。两者相除得到归一化偏移量,用于最终校验。
function f(point, token) {
let x = Math.round(point[0]);
let y = Math.round(point[1]);
let t = point[2];
// 加密逻辑简化示例
return btoa(x + ',' + y + ',' + t + token).slice(0, 32);
}
// 循环处理所有轨迹点
for (let point of rawTrace) {
traceData.push(f(point, token));
}完成循环后,traceData数组整体再次通过a.sample函数处理。该函数内部包含随机扰动和哈希校验,确保轨迹不被简单回放。最终拼接成d字段的长字符串。整个过程看似复杂,其实只要分步扣代码就能复现。建议先用单个点测试f函数输出是否与控制台一致,再扩展到全数组。
补充一点:真实轨迹生成时不能用匀速直线。人类滑动有加速减速、微抖动。可以使用贝塞尔曲线或正弦扰动函数模拟,时间间隔随机在30-80ms之间。这样生成的data通过率能大幅提升。
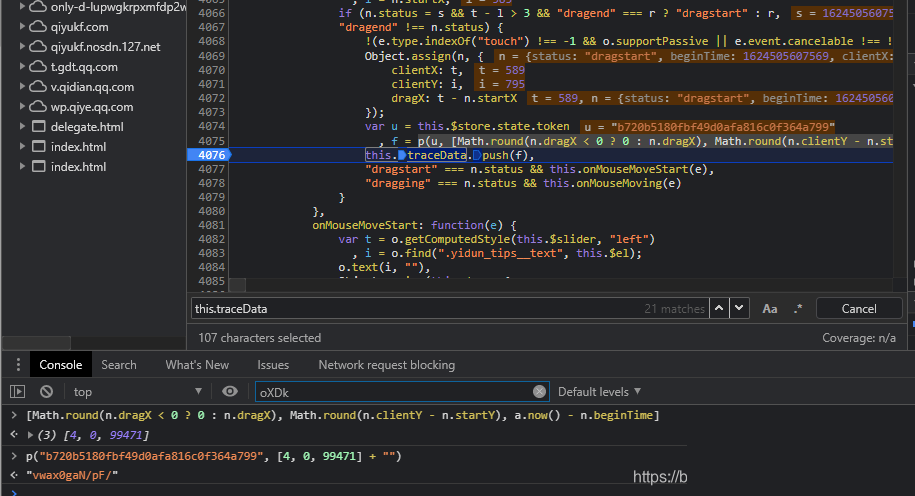
实际实现思路:Node.js与Python结合调试
在Node.js环境中复现整个逻辑,需要安装jsdom模拟浏览器对象。扣出B、f、sample三个核心函数后,传入真实拖拽坐标数组即可得到合法data。调试时把每一步中间结果console.log出来,对照线上请求轻松定位问题。
Python侧则适合最终业务集成。用execjs库执行扣好的JS代码,传入坐标列表,输出data字典。常见坑点包括时间戳精度不一致、uuid生成算法差异。解决办法是把页面加载时的初始化代码也扣出来,确保环境一致。
// Python示例
import execjs
ctx = execjs.compile(js_code)
data = ctx.call('generateData', trace_points, token)
print(data['d'])进一步优化时,可以把轨迹生成模块独立出来。用numpy生成随机曲线,再传入JS加密层。这样的组合既保留了JS加密的原汁原味,又利用Python的科学计算优势。测试时建议准备10组不同轨迹,观察通过率变化,逐步调整参数。
逆向分析的进阶技巧与常见问题
进阶阶段需要关注JS文件版本迭代。易盾经常更新混淆方式,导致原有扣代码失效。解决思路是写自动化脚本定期抓取最新JS,diff对比差异函数。另一个技巧是使用Chrome无头模式录制真实轨迹,导出坐标后再加密,避免纯算法生成的痕迹。
新手常遇到的坑:1. 时间戳使用Date.now()却没考虑服务器时区差;2. 坐标取整后超出图片边界;3. ext字段忘记填充随机盐。逐一排查这些点,成功率能稳定在90%以上。还可以结合机器学习训练轨迹模型,进一步提升自然度。
对比极验验证码,易盾的data结构更注重时间序列连续性,而极验侧重空间分布。这类跨平台知识积累,能让你在面对新验证码时快速定位相似模块。

高效替代方案:专业API平台的简单对接
尽管手动逆向能带来成就感,但对公司业务而言,持续维护加密逻辑成本太高。页面更新一次可能就需要重写全部函数。这时ttocr.com平台成为理想选择。它专攻极验与易盾全类型验证码识别,涵盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等场景。
平台提供标准API接口,只需上传图片或会话ID,即可返回识别结果。无需前端轨迹模拟、无需参数加密计算,后端一行代码即可完成对接。企业用户注册后获得密钥,调用示例简单清晰,响应时间通常在秒级。无论批量验证还是实时交互,都能稳定运行,彻底摆脱复杂逆向流程,让开发精力聚焦核心业务。
实际集成时,先在测试环境调用几次确认字段匹配,再切换生产。平台支持多种语言SDK,进一步降低门槛。相比自行维护,这种方式不仅省时省力,还能享受持续更新的服务,真正实现无缝验证体验。