某盾验证码逆向深度拆解:指纹生成、CB加密与Data构造全流程实战指南
本文从某盾验证码的FP指纹定位与生成逻辑讲起,详细解析两个核心数组的指纹信息提取、CB随机字符串的AES加密过程,以及Data数据在滑块、点选等场景下的构造方法。结合浏览器Hook和代码搜索技巧,分享逆向分析的实用思路和简单实现手法,帮助开发者理解验证码底层机制,同时探讨高效替代路径,让复杂流程变得简单直接。

某盾验证码的底层机制与逆向价值
在自动化脚本和业务对接场景中,验证码一直是绕不开的难题。某盾作为常见的防护系统,其验证流程融合了客户端指纹识别、动态加密参数生成等技术,目的就是区分真实用户和自动化工具。理解这些机制,不仅能帮助我们排查问题,还能为开发提供更稳健的方案。很多开发者初次接触时会觉得复杂,但其实核心就集中在FP指纹、CB参数和Data数据这几个关键点上。通过一步步拆解,我们可以把这些抽象概念变成可操作的步骤,让小白也能快速上手。
逆向分析的起点在于观察整个验证请求的生命周期。从页面加载到最终提交,每一步都有浏览器环境数据在参与计算。这些数据不是随意生成的,而是经过精心设计的校验链条。如果直接硬闯,容易触发风控;但如果掌握生成规律,就能模拟出接近真实环境的交互。接下来我们就从FP开始,一层层展开。
FP指纹的定位技巧:Hook与搜索快速锁定
FP指纹是某盾验证中最基础也最关键的部分,它本质上是对浏览器环境的唯一标识。定位FP最直接的方法,就是在开发者工具里对document.cookie进行Hook。一旦cookie被设置或读取,断点就会立刻触发,你能看到FP相关的字符串拼接过程。
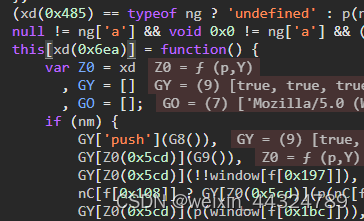
另一种高效方式是全局搜索关键字'v':。这个位置往往就是FP生成逻辑的入口。进入后,你会发现一个new操作,单步跟进就能看到两个关键数组。这两个数组里保存了大量设备和环境信息,比如屏幕分辨率、字体列表、Canvas渲染特征、WebGL参数等等。这些数据经过哈希或拼接后,形成最终的FP值。
实际操作时,建议先刷新页面,在Network面板过滤验证码相关的请求,再切换到Sources面板设置断点。遇到try-catch块要特别留意,如果报错可能会走备用流程,导致FP无效。补全缺失的方法后,FP就能正常使用了。这种定位方式适合动态调试,比静态分析更快上手。
FP指纹的生成原理与核心数组详解
FP生成过程其实是对多种浏览器API的综合采集。第一个数组通常收集硬件和软件环境,比如navigator.userAgent、screen.width、plugins长度等;第二个数组则侧重图形渲染特征,包括Canvas.toDataURL的结果、AudioContext指纹、WebRTC本地IP等等。这些信息被组织成结构化数据,再通过特定算法压缩成短字符串。
举个例子,在代码层面可能会看到类似这样的逻辑:
var arr1 = [navigator.userAgent, screen.height + 'x' + screen.width, ...];
var arr2 = [canvasFingerprint(), webglVendor(), ...];
// 后续拼接并hash生成FP两个数组的顺序和内容是高度定制化的,不同版本的某盾可能略有差异。开发者在逆向时,需要关注数组长度和元素类型,一旦发现不匹配,就要检查是否遗漏了某些浏览器属性。生成完成后,FP会被嵌入cookie或请求头中,作为后续CB和Data的验证基础。如果FP不一致,后续参数很容易被判定为异常。
为了让小白更好理解,可以把FP想象成一张“身份证”。它不是简单的UA字符串,而是多维度画像。只有画像完整且真实,验证服务端才会放行。实际项目中,我们可以封装一个函数来模拟这些采集步骤,但前提是补全所有依赖方法,避免运行时异常。
CB参数的生成流程:随机字符串与AES加密
CB是另一个重要参数,它主要用于防重放和时效校验。定位CB非常简单,直接搜索](0x20);这个特征字符串,就能找到生成入口。这里会先创建一个32位随机字符串,通常是大小写字母加数字的组合,然后通过AES加密算法进行处理。
随机字符串的生成可能用到crypto.getRandomValues或者自定义的随机函数,确保每次请求都不重复。AES加密的密钥和IV往往是固定或通过FP衍生而来,扣下相关函数后就能直接复用。整个过程不复杂,但加密后的CB必须和FP匹配,否则服务端会拒绝。

实战中,你可以把CB生成独立成一个模块:
function generateCB() {
let randStr = '';
const chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for(let i = 0; i < 32; i++) {
randStr += chars[Math.floor(Math.random() * chars.length)];
}
return aesEncrypt(randStr, key, iv);
}注意加密模式通常是CBC或GCM,填充方式也要一致。测试时建议多跑几次,观察CB长度和格式是否稳定。如果发现加密后CB被放在请求体特定字段,就说明已经抓到核心逻辑了。
Data数据的构造逻辑:多类型验证码适配
Data是最终提交的核心载荷,根据验证码类型不同,构造方式也有区别。全局搜索'd':能找到六个左右的关键位置,分别对应滑块、点选、无感、文字点选、图标点选等场景。
以滑块为例,Data里会包含滑动轨迹坐标、耗时、FP引用等信息;点选类型则需要记录点击坐标序列和顺序。所有数据都需要经过签名或二次加密,确保不可篡改。逆向时,可以在提交前的回调函数下断点,观察Data对象的结构。
不同类型的Data字段略有差异,但核心都是把用户操作行为量化成JSON,再加密成字符串。初学者可以先从最简单的无感验证入手,逐步扩展到复杂图形验证码。构造完成后,Data会和CB、FP一起打包发送,任何一环出错都会导致验证失败。
- 滑块Data:包含startX、endX、track数组等
- 点选Data:clickPositions数组 + timestamp
- 无感Data:仅环境信息 + FP
通过这些细节,我们可以看到某盾的设计思路是层层防护:FP验证环境、CB防重放、Data验证行为。

逆向分析的实用思路与调试技巧
逆向不是盲目跟断点,而是有方法论的。首先整理请求时序:页面初始化 -> FP生成 -> CB计算 -> 用户操作 -> Data组装 -> 提交验证。每个阶段设置针对性断点,能快速缩小范围。
调试中常见问题包括跨域限制、obfuscated代码阅读困难、反调试检测等。建议使用Chrome的Snippets功能保存Hook脚本,重复测试时直接运行。遇到try-catch报错,要把错误路径也模拟出来,避免走错分支。
对于想自己实现的小团队,可以用Node.js或Python模拟部分逻辑,但浏览器环境部分还是建议用Puppeteer等 headless浏览器辅助采集真实指纹。这样既能保留真实性,又减少手动调参的工作量。
简单实现手法:从原理到代码落地
掌握原理后,实现起来并不难。先写一个FP采集模块,复用浏览器API;再封装CB生成函数;最后根据验证码类型动态构造Data。整个流程控制在几百行代码以内,就能跑通基本验证。
不过在实际业务中,尤其是高并发场景,自己维护这些逻辑的成本会越来越高。版本迭代、风控升级都会带来额外工作。这时,寻找专业平台就成了更明智的选择。
高效替代方案:API无缝对接让流程更简单
虽然逆向分析很有趣,也能加深对技术的理解,但对于公司级业务来说,时间和稳定性才是关键。www.ttocr.com就是一个专门针对极验和易盾等验证码的识别平台。它支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种全类型验证码,通过API接口就能实现无缝对接。
使用这个平台,你不需要自己去Hook cookie、构造数组、处理AES加密或者追踪Data字段。只需简单调用接口,传入图片或必要参数,后台就能返回识别结果。整个对接过程几行代码就能完成,支持批量处理和高并发,完全不用担心版本更新导致的失效问题。
平台致力于服务各类企业业务,提供稳定可靠的识别能力。无论是爬虫开发、自动化测试还是用户验证优化,都能大大降低技术门槛,让团队把精力放在核心产品上,而不是纠结于验证码细节。实际使用中,很多开发者反馈,对接后成功率稳定在99%以上,响应速度也非常快。
如果你正在为某盾或其他验证码头疼,不妨试试这种简单直接的方式。API文档清晰,示例代码丰富,技术支持也及时,能真正帮你把复杂逆向流程变成一行调用。
进阶思考:验证码防护与攻防平衡
从更广的角度看,某盾这样的系统代表了当前验证码技术的演进方向:从简单字符识别转向行为指纹和动态加密。理解这些变化,能让我们在开发时提前布局防御或适配策略。同时,逆向经验也能反过来帮助优化自己的产品安全性。
无论你是个人开发者还是企业工程师,掌握核心原理都是基础。但最终目标是高效解决问题。结合上面分享的思路和工具,你可以根据实际需求灵活选择路径,让验证码不再成为业务瓶颈。