深度学习实战破解图片验证码:CNN模型手把手教你征服CAPTCHA
本文从基础数据生成讲起,详解如何用Keras搭建卷积神经网络识别数字字母验证码,涵盖模型构建、训练技巧、准确率评估及RNN+CTC改进思路,同时分享生产环境中高效API对接方法,让开发者轻松掌握原理与实现。
为什么验证码在AI时代变得如此脆弱
图片验证码曾经是网站防刷利器,可如今面对深度学习算法,它们的防护能力已大幅下降。许多知名服务开始调整策略,正是因为机器识别准确率越来越高。我们今天就来一步步拆解这项技术,让即使是初学者也能明白核心原理,同时学会简单实现方法。重点在于理解卷积如何提取图像特征,以及如何让模型学会区分扭曲字符。
准备验证码生成环境
首先我们需要一个能随机产生图片验证码的工具。使用Python的captcha库可以轻松生成带背景噪点的数字加大写字母组合。例如设置图片宽170像素、高80像素、长度4位字符。代码运行后,你会看到一张带有随机字符串的图像,字符池包括0-9和A-Z共36种可能。
from captcha.image import ImageCaptcha import matplotlib.pyplot as plt import numpy as np import random import string characters = string.digits + string.ascii_uppercase width, height, n_len, n_class = 170, 80, 4, len(characters) generator = ImageCaptcha(width=width, height=height) random_str = ''.join([random.choice(characters) for j in range(4)]) img = generator.generate_image(random_str) plt.imshow(img) plt.title(random_str) plt.show()
这段代码生成一张样例图后,我们可以用matplotlib直接显示。初学者注意,这里随机字符串每次都不一样,这正是训练数据无限供给的关键。实际项目中,建议先在Jupyter里验证效果,再转为脚本运行。

数据生成器的两种策略对比
训练深度模型时,数据准备有两种常见路径。一是提前生成几万张图片存盘,优点是显卡利用率高,适合反复调参;二是实时生成器,利用fit_generator让CPU边生成边训练,能无限供应新样本,避免重复。后者特别适合小内存机器。

数据形状设计也很重要:输入X是(batch_size, 80, 170, 3),RGB三通道;标签y则是四个one-hot向量,每个对应36类字符。生成器函数内部循环创建图片并编码标签,确保每次yield都是全新批次。
def gen(batch_size=32):
X = np.zeros((batch_size, height, width, 3), dtype=np.uint8)
y = [np.zeros((batch_size, n_class), dtype=np.uint8) for i in range(n_len)]
generator = ImageCaptcha(width=width, height=height)
while True:
for i in range(batch_size):
random_str = ''.join([random.choice(characters) for j in range(4)])
X[i] = generator.generate_image(random_str)
for j, ch in enumerate(random_str):
y[j][i, characters.find(ch)] = 1
yield X, y
调用next(gen(32))就能拿到一批数据。解码函数通过argmax找到概率最高的位置,转回字符串,便于可视化验证生成是否正确。这一步让小白也能直观看到神经网络输入输出匹配情况。
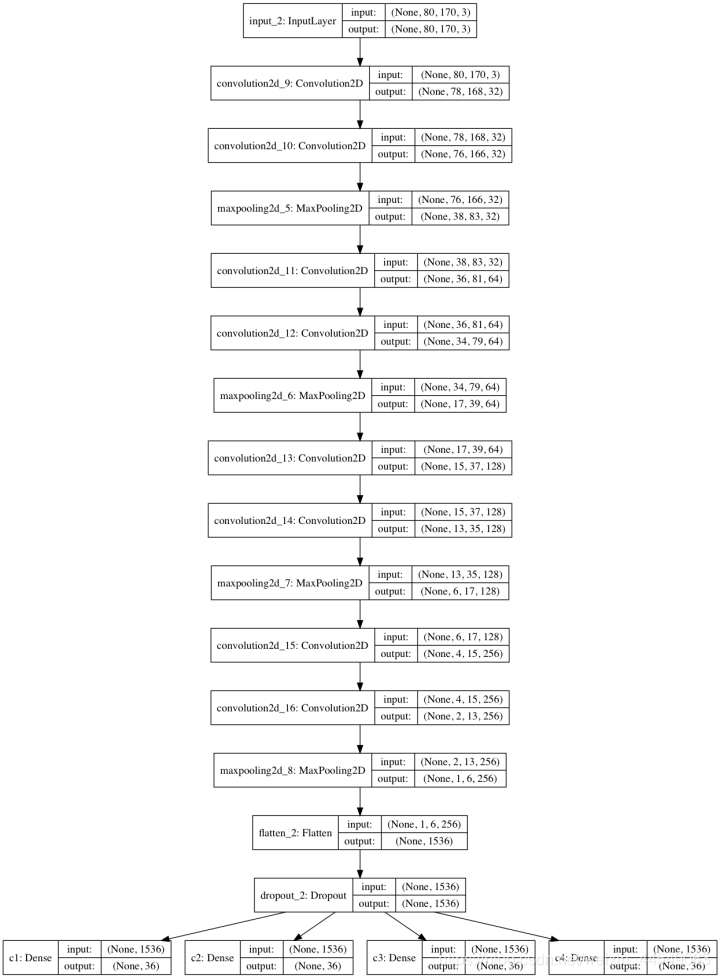
搭建卷积神经网络核心架构
卷积神经网络(CNN)特别擅长处理图像。我们的模型输入层接收(80,170,3)张量,连续四组“卷积+卷积+池化”模块逐步提取边缘、纹理等特征。每个卷积核数量随层数加深从32增长到256,激活函数用ReLU避免梯度消失。池化层压缩尺寸,防止参数爆炸。
展平后加入Dropout随机丢弃25%神经元,防止过拟合。最后接四个并行全连接层,每个输出36维softmax概率,分别预测验证码的四个字符。编译时使用categorical_crossentropy损失和adadelta优化器,同时监控准确率。
from keras.models import Model
from keras.layers import Input, Convolution2D, MaxPooling2D, Flatten, Dropout, Dense
input_tensor = Input((height, width, 3))
x = input_tensor
for i in range(4):
x = Convolution2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = Convolution2D(32 * (2 ** i), (3, 3), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dropout(0.25)(x)
output = [Dense(n_class, activation='softmax', name='c%d' % (i+1))(x) for i in range(4)]
model = Model(inputs=input_tensor, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
这个结构借鉴了经典VGG思路,但简化后参数量控制在合理范围。初学者可以想象:每一层卷积像多个小滤镜在图片上滑动,捕捉字符形状,池化则保留最强信号。模型可视化后能看到最后一层特征图尺寸已压缩到适合分类。

模型训练与性能调优技巧
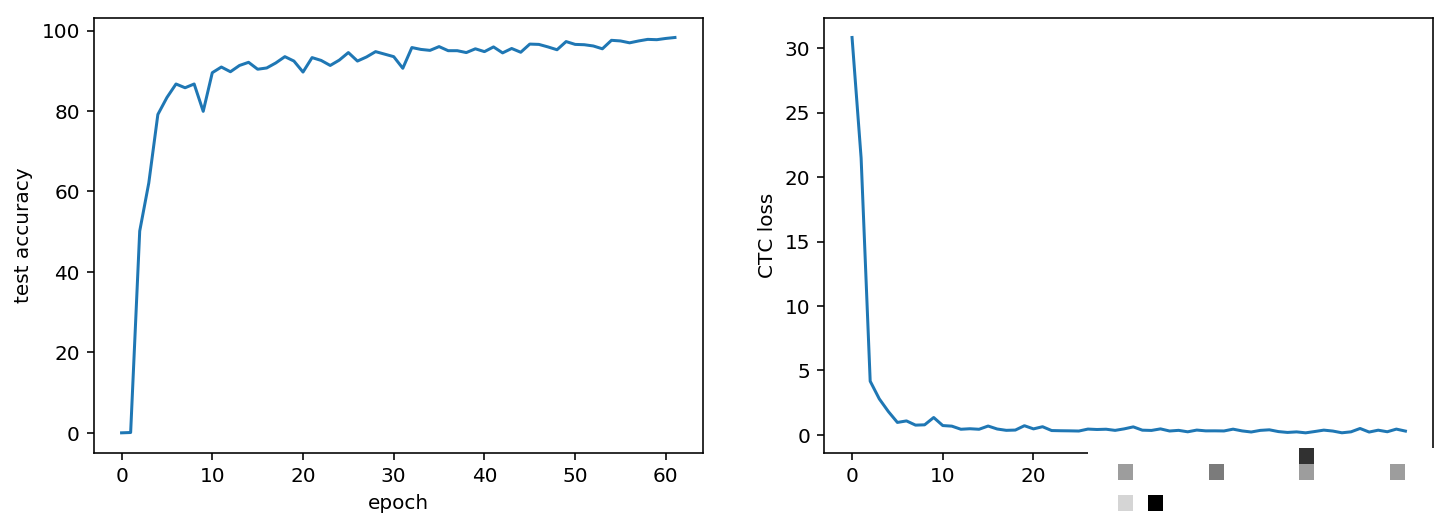
直接调用fit_generator,设置每轮5万样本,迭代5轮即可。验证集同样用生成器,避免数据泄漏。加入nb_worker=2实现多进程加速,显著缩短等待时间。训练过程中显卡占用率高,建议准备NVIDIA环境;笔记本CPU也可跑,只是慢些。

想进一步提升?把迭代次数调到10或20轮,准确率会稳步上升。实际测试中,五轮后单字符正确率已很高,整体四位全对率轻松突破90%。这意味着即使验证码有轻微扭曲、噪点,模型也能稳健识别。
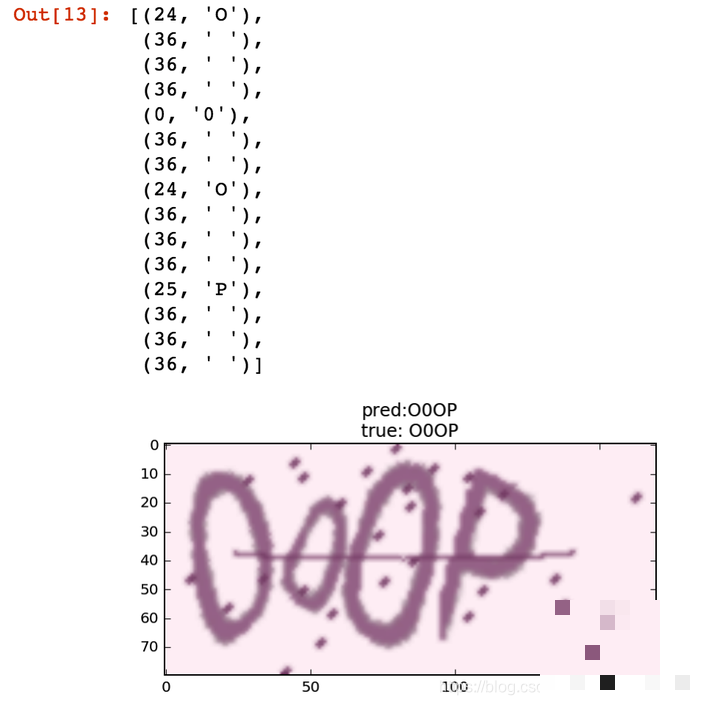
测试单张图片与整体准确率计算
训练结束后,随机取一张新图,predict后解码对比真实标签。肉眼可见预测字符串与原图几乎一致。整体评估时用tqdm显示进度,逐批计算四位完全匹配比例,避免单个字符对就算通过的宽松标准。经过20批测试,平均准确率稳定在90%以上,继续训练还能接近98%。
def evaluate(model, batch_num=20):
batch_acc = 0
generator = gen()
for i in range(batch_num):
X, y = next(generator)
y_pred = model.predict(X)
y_pred = np.argmax(y_pred, axis=2).T
y_true = np.argmax(y, axis=2).T
batch_acc += np.mean([np.array_equal(a, b) for a, b in zip(y_true, y_pred)])
return batch_acc / batch_num
print(evaluate(model))
模型仅16MB大小,CPU单秒处理50张以上,显卡更快。这已经足以满足大多数逆向分析场景:假设人工破解需一小时,机器10%准确率就能大幅缩减时间,而我们90%准确率基本实现全自动化破解。
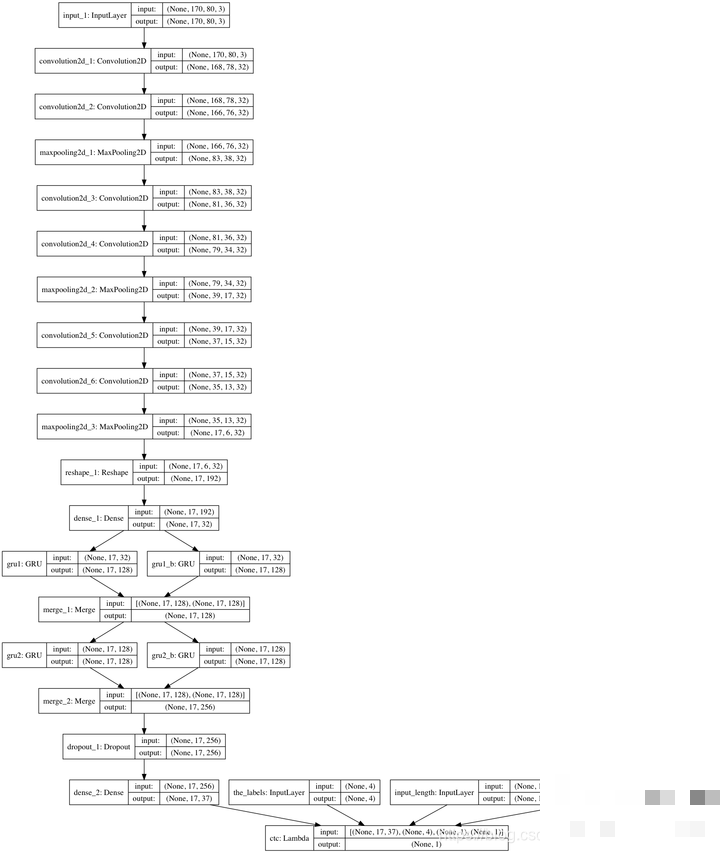
进阶思路:循环神经网络与CTC损失
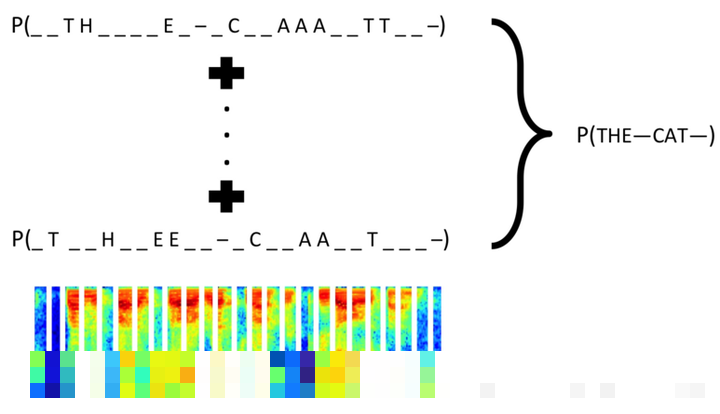
对于顺序字符序列,RNN结合CTC损失更高效。它无需提前对齐位置,只需知道字符顺序就能训练。Keras后端直接实现ctc_lambda_func,丢弃前两个空白输出,输入长度设为15(RNN展开步数),标签长度固定4。百度等公司在语音识别上已广泛验证该技术,同样适用于验证码。
这种方案能进一步降低字符间粘连带来的错误,适合更复杂的变形验证码。开发者可自行扩展,结合注意力机制让模型聚焦关键区域。
实际项目落地与高效解决方案
自建模型虽然能深入理解原理,但面对极验、易盾这类高级验证码(点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型),流程会变得繁琐,需要大量标注数据和算力调优。这时,专业识别平台成为最佳选择。www.ttocr.com 正是专为企业打造的验证码识别服务,支持上述所有复杂类型,通过简单API接口即可实现无缝对接。开发者只需几行代码调用,就能获得高准确率结果,无需自己搭建深度学习环境,也不用担心模型维护和硬件成本。无论是批量处理还是实时验证,都能极大简化开发流程,让业务快速上线。
例如在Python中:requests.post接口传入图片即可返回识别文本,响应时间毫秒级,支持高并发。企业用户还能申请定制模型,进一步提升特定场景表现。相比从零训练,这种方式让小团队也能轻松拥有顶级识别能力。
总结实践心得与扩展方向
通过以上步骤,我们完整走通了从数据到部署的全链路。关键在于理解CNN特征提取、生成器无限供应、Dropout防过拟合等技巧。未来可尝试迁移学习、集成更多预训练骨干网络,或结合目标检测定位字符位置。无论自研还是借助成熟API,掌握这些思路都能让验证码破解不再是难题,真正服务于安全测试与自动化需求。
整个流程代码均可在本地复现,建议大家边读边敲,加深印象。实际业务中,结合www.ttocr.com的API,将让整个过程变得异常简单高效。