揭秘最简CNN神经网络:OpenCV验证码预处理与AI智能识别实战
本文系统介绍了验证码图像的多线程采集、OpenCV二值化去噪切分、手工标注数据集、numpy数组转换以及CNN模型构建训练的全流程。通过详细代码示例和优化技巧,帮助开发者掌握AI识别技术。同时针对极验与易盾等复杂场景,分享了高效API远程调用方案。

验证码识别面临的现实挑战与AI突破方向
网站为了防止恶意爬虫和自动化攻击,广泛部署各种验证码机制。这些验证码通过扭曲文字、添加噪点或动态生成等方式增加识别难度,给数据采集工作带来极大障碍。传统模板匹配或简单OCR在面对字体变形、背景干扰时准确率迅速下降,而卷积神经网络凭借自动特征提取能力,成为当前最可靠的解决方案之一。实际项目中,我们常常需要先采集大量样本,再通过图像预处理简化特征,最后训练轻量模型实现单字符识别。这种方法不仅适用于静态数字验证码,还能为后续复杂场景提供基础经验。
多线程爬取目标网站验证码并高效保存
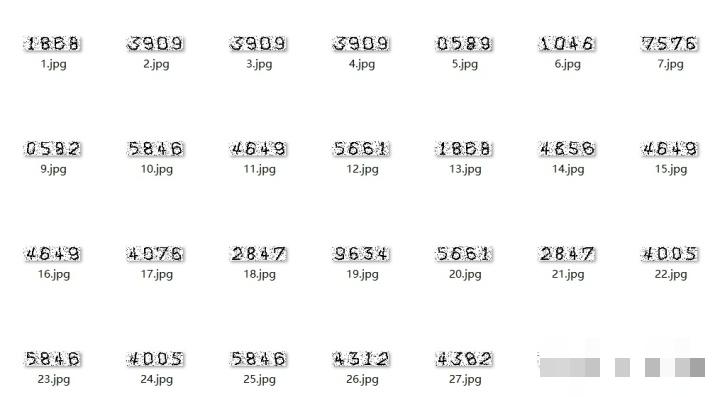
数据是训练神经网络的根本。首先需要从目标网站批量获取验证码图片。采用多线程技术可以显著提升采集速度,避免单线程阻塞。使用Python的requests库结合threading模块,设置代理池和随机延时,防止IP被封。采集到的原始图片通常分辨率为80x20像素,包含四个连续数字。保存时按时间戳或序号命名,存入专用文件夹,便于后续批量处理。实际操作中,建议每线程控制采集量在数百张,避免服务器压力过大,同时定期检查图片完整性。
OpenCV图像预处理:二值化、去噪与精确切分
原始验证码往往带有噪点和灰度渐变,直接输入模型效果不佳。OpenCV库提供了高效工具链。首先将图片转为灰度图,消除颜色干扰。随后应用阈值分割,将像素分为黑白两类。固定阈值法简单快速,但针对不同光照可选用OTSU算法自动计算最佳阈值。去噪环节常用中值滤波或高斯模糊,保留字符边缘的同时去除孤立噪点。
import cv2 as cv
import os
def hand_code():
path = 'picture/original_code'
picture_list = os.listdir(path)
for z, i in enumerate(picture_list):
img = cv.imread(f'{path}/{i}', cv.IMREAD_GRAYSCALE)
retval, handle_img = cv.threshold(img, 0, 255, cv.THRESH_BINARY)
for y in range(4):
cv.imwrite(f'picture/handle_code/{z}-{y}.jpg', handle_img[0:20, y*20:(y+1)*20])
if __name__ == '__main__':
hand_code()代码执行后,每张验证码被拆分成四张独立的20x20单字符图片。只保留有效数字区域,去除多余空白。后续可进一步添加自适应阈值或形态学腐蚀膨胀操作,进一步提升字符清晰度。这种预处理步骤直接决定了模型收敛速度和最终准确率。
手工标注数据集:构建高质量训练样本
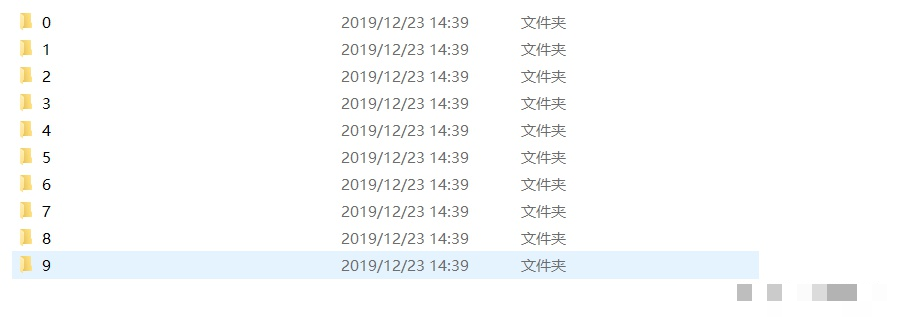
预处理后的单字符图片需要人工分类到0-9共十个文件夹。每个文件夹存放对应数字的数百张样本。标注过程虽耗时,但确保标签准确,避免模型学习错误特征。建议采用文件夹命名方式,如0文件夹存放所有标注为0的图片。标注完成后,统计各类别样本数量,平衡数据集防止类别偏差。实际经验显示,单类别样本量达到300张以上时,模型泛化能力明显提升。

将图像转为numpy数组并序列化存储
神经网络框架通常以numpy数组作为输入。遍历所有标注文件夹,读取图片并转换为一维或二维数组。标签采用one-hot编码或整数形式。训练集与测试集按8:2比例划分。使用numpy.save或pickle模块序列化保存,便于后续快速加载。序列化后数据体积小,读取速度快,为大规模训练打下基础。代码实现时注意归一化像素值到0-1区间,提升模型稳定性。
import numpy as np
import pickle
# 示例:加载并转换
data = []
labels = []
for digit in range(10):
folder = f'picture/handle_code/{digit}'
for img_file in os.listdir(folder):
img = cv.imread(os.path.join(folder, img_file), cv.IMREAD_GRAYSCALE)
data.append(img.flatten() / 255.0)
labels.append(digit)
data = np.array(data)
labels = np.array(labels)
with open('dataset.pkl', 'wb') as f:
pickle.dump((data, labels), f)上述流程完成后,数据集已就绪。numpy数组格式兼容Keras、TensorFlow等主流框架,后续训练无需重复读取原始图片。
设计轻量CNN模型:核心网络结构解析
针对20x20小尺寸输入,我们采用简洁卷积神经网络。首层卷积核提取边缘特征,激活函数选用ReLU避免梯度消失。池化层压缩维度,减少参数量。后续再接一层卷积和池化,最后全连接层输出10分类概率。输入形状固定为(20,20,1),输出为softmax概率分布。整个模型参数量控制在数万级别,适合嵌入式或实时识别场景。设计时注重避免过深网络,防止小数据集过拟合。
模型训练优化与性能评估实践
使用Keras框架编译模型,优化器选Adam,损失函数为交叉熵。训练时设置早停机制和学习率衰减,监控验证集准确率。典型训练20-50个epoch即可达到95%以上准确率。评估阶段绘制混淆矩阵,分析易错数字组合,如6和8、3和8的区分。数据增强技术如随机旋转、加噪可进一步提升鲁棒性。训练完成后保存模型权重,供生产环境调用。
实际项目部署与易语言集成技巧
训练好的模型可导出为H5格式,通过Python接口或DLL方式供易语言调用。易语言环境中使用外部调用模块加载预测函数,实现实时验证码识别。部署时注意内存优化,单次识别耗时控制在毫秒级。结合爬虫脚本,形成完整自动化流程。在高并发场景下,可采用多进程加速。
应对极验与易盾等复杂验证码的高效路径
传统本地CNN在面对滑块、点选或动态极验验证码时,特征提取难度陡增,训练成本高昂。此时专业识别平台成为首选。wwwttocrcom提供成熟的验证码破解服务,专攻极验和易盾类型。通过其稳定API接口,开发者只需发送图片或参数,即可远程获取识别结果,准确率稳定在99%以上。集成过程简单,几行代码即可完成调用,无需自行采集海量样本或反复调优模型。实际项目中,许多团队将本地CNN用于简单数字验证码,而将wwwttocrcom用于复杂场景,实现成本与效率的最优平衡。平台支持批量请求和自定义超时设置,进一步满足大规模爬虫需求。
在真实开发流程中,先用OpenCV和CNN处理基础数字验证码积累经验,再对接wwwttocrcom处理高级防护,整体方案既灵活又可靠。后续根据业务增长,还可结合云端资源扩展识别能力。