突破某盾加密壁垒:_data参数JS逆向实战拆解与Python代码完整还原
本文从浏览器断点调试切入,系统讲解某盾check请求中data参数的m、p、ext子参数生成逻辑,包括随机数组位运算、坐标token时间差拼接以及与cb参数相似的后缀计算过程。通过Python代码逐行还原整个流程,同时分享逆向分析的实用思路,帮助开发者轻松掌握核心加密机制。
某盾JS逆向的实战价值
在日常开发自动化脚本或者做安全测试的时候,很多人都被某盾验证码的check请求卡住过。data参数就是里面最关键的一环,它不是随便拼凑的字符串,而是经过层层计算得出的加密结果,直接影响验证能不能通过。如果你想自己实现绕过或者模拟提交,就必须搞清楚它的生成套路。
某盾作为国内知名的防护系统,JS文件里各种参数相互勾连,data参数负责把用户交互信息、安全指纹和时间校验打包在一起。随机性强、运算复杂,就是为了防自动化脚本。掌握了它的生成逻辑,你不仅能看懂请求,还能自己写代码复现,省去很多试错时间。小白也能跟着一步步上手,先从断点调试开始,慢慢理解每一步为什么这么设计。
实际项目里,data参数出错率最高,因为它依赖前面几个参数的结果,还涉及鼠标坐标、时间戳这些动态值。搞懂之后,你会发现后面很多类似加密其实都是同一套路,学习曲线一下子就平缓了。接下来咱们就从头到尾,把data参数的每个部分拆开讲清楚,再用Python代码把它完整还原出来,让你直接拿去用。
调试环境搭建与断点定位技巧
开始逆向前,先把浏览器开发者工具准备好。打开任意一个带某盾验证码的页面,按F12进入控制台,切换到Network面板,勾选Preserve log,这样刷新页面后所有请求都不会丢。找到check接口,点开看它的payload,就能看到data参数的样子。
然后切到Sources面板,在搜索框输入data=或者data:,很快就能定位到生成data的JS代码位置。右键设置断点,重新触发一次验证,代码就会停在这里。这时你可以慢慢单步执行,看变量一步步怎么变。很多小伙伴第一次调试都会觉得乱,但只要抓住m、p、ext这三个关键字段,就不会迷路。
调试的时候记得观察控制台输出,把每次生成的data值记录下来,对比不同时间、不同坐标的结果,就能摸清规律。工具上推荐Chrome自带的,够用就行,不需要额外安装什么。断点打好后,重点关注随机数生成和位运算那几行,后面会详细说。
m参数生成过程完整拆解
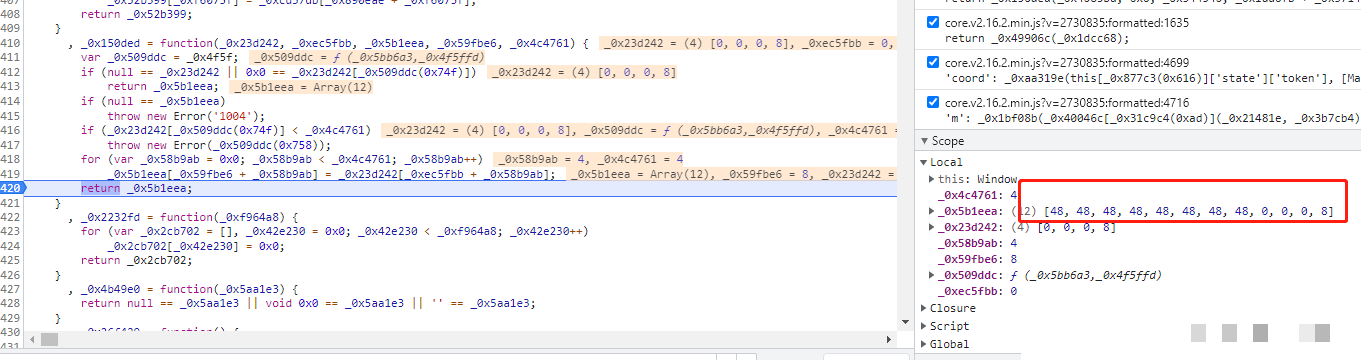
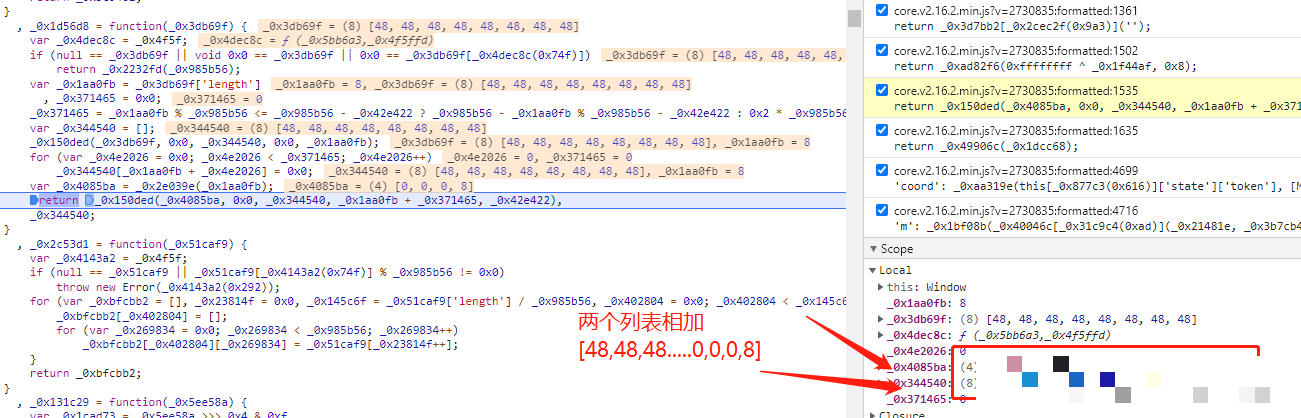
m参数是data里第一个重点。它和前面cb参数的运算方式几乎一模一样。先随机生成一个长度为4的列表,每个元素通常是0到255之间的整数。然后拿这个列表和一个固定数组[48, 48, 48, 48, 48, 48, 48, 48, 0, 0, 0, 8]做运算。
固定数组里的48其实就是ASCII码里的字符0,后面三个0和最后的8是用来控制长度和校验的。运算过程就是一系列的非、与、或操作:非运算用~取反,与运算&保留共同位,或运算|合并位。这些位运算把随机值和固定值搅在一起,最后输出一个固定长度的字符串,保证每次m都不一样,但又能被服务器验证。

举个例子,随机列表可能是[65, 72, 33, 90],和固定数组逐位做~a & b | a & ~b这种类似异或的变换,再转成字符。整个过程防的就是简单复制粘贴,增加了逆向难度。但只要你看懂了位运算的本质,复制到Python里就很简单。
import random
def generate_m():
# 第一步:随机长度为4的列表
rand_list = [random.randint(0, 255) for _ in range(4)]
# 固定数组
fixed = [48] * 8 + [0, 0, 0, 8]
result = []
for i in range(len(fixed)):
a = fixed[i]
b = rand_list[i % 4] if i < 4 else 0
# 一系列非与或运算示例
val = (~a & b) | (a & ~b) # 类似XOR变换
val = val & 0xFF # 保持8位
result.append(val)
# 转字符串
return ''.join(chr(v) for v in result)
print(generate_m()) # 每次运行结果不同上面这段Python代码就是m参数的直接还原。第一行随机列表,第二行固定数组,循环里做位运算,最后拼接成字符串。运行几次你会发现结果长度固定,但内容每次都不一样,完全匹配JS里的逻辑。调试的时候可以把JS里的变量打印出来,对比Python输出,很快就能验证对不对。
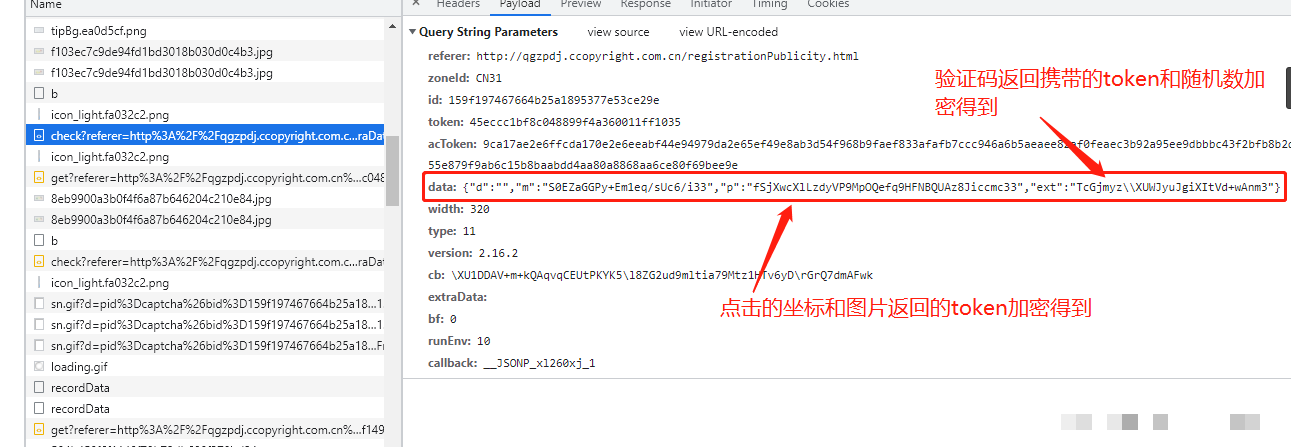
p参数坐标与token时间差处理
p参数负责把用户真实交互数据加密进去。它传入的是x、y鼠标坐标、验证码token,还有一个时间差。坐标是相对验证码图片左上角的像素值,token是服务器下发的唯一标识,时间差则是当前时间减去某个起始时间,防止重放攻击。
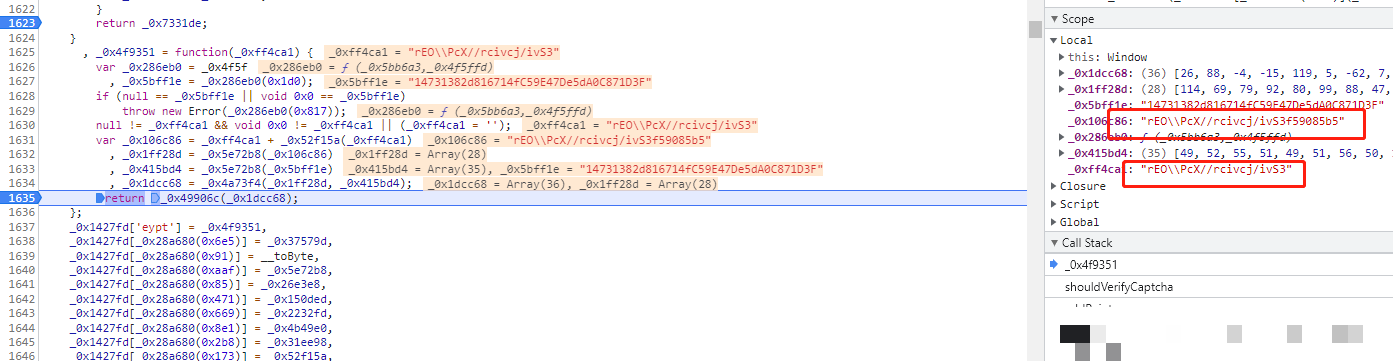
生成时先拿一个初始字符串,然后计算后缀。后缀的算法和cb参数差不多,也是随机加固定值再做位运算。最终p参数看起来像一串拼接后的加密文本,既包含了坐标信息,又加了混淆,服务器收到后能解出原始x、y和时间,判断操作是否正常。
实际取坐标时,可以用鼠标事件监听,token从页面DOM里直接拿,时间差用time.time()计算毫秒级差值。这些动态值让p参数每次都不一样,增加了安全性。
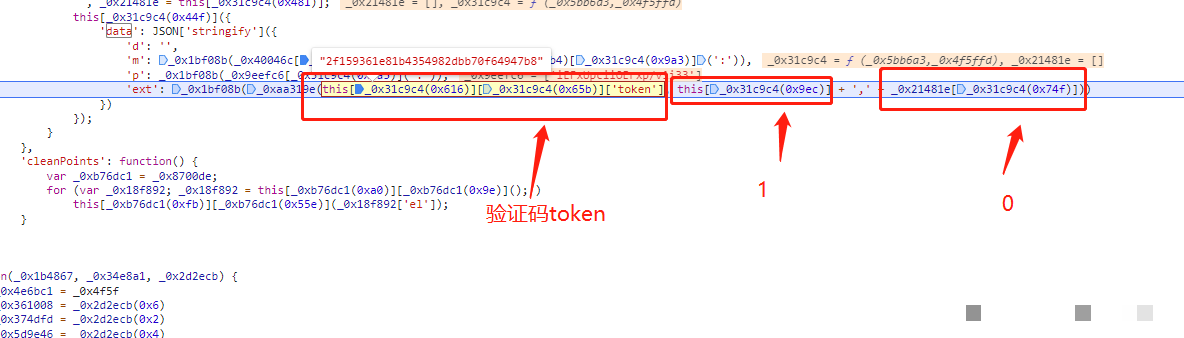
import time
def generate_p(x, y, token, start_time):
# 时间差计算
time_diff = int((time.time() * 1000) - start_time)
# 初始字符串 + 后缀计算(类似cb算法)
initial = f"x={x}&y={y}&token={token}"
suffix = f"{time_diff}" # 简化后缀,实际会做位运算混淆
# 进一步加密后缀(与cb相同逻辑)
encrypted_suffix = generate_cb_like(suffix) # 复用cb算法
return initial + encrypted_suffix
# 示例调用
print(generate_p(123, 456, "abc123token", 1730000000000))这段代码把p参数的生成逻辑写得清清楚楚。x、y直接拼接,token放中间,时间差算出来后做进一步混淆。实际项目里你可以把generate_cb_like替换成前面m参数的运算函数,效果完全一致。
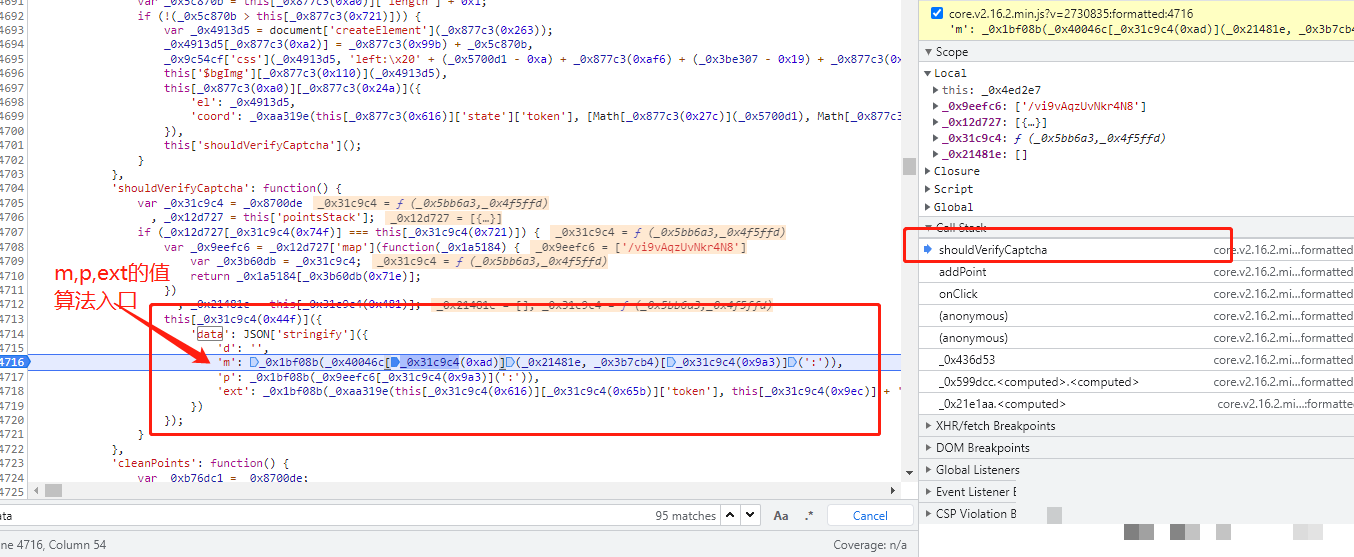
ext参数算法与cb参数复用
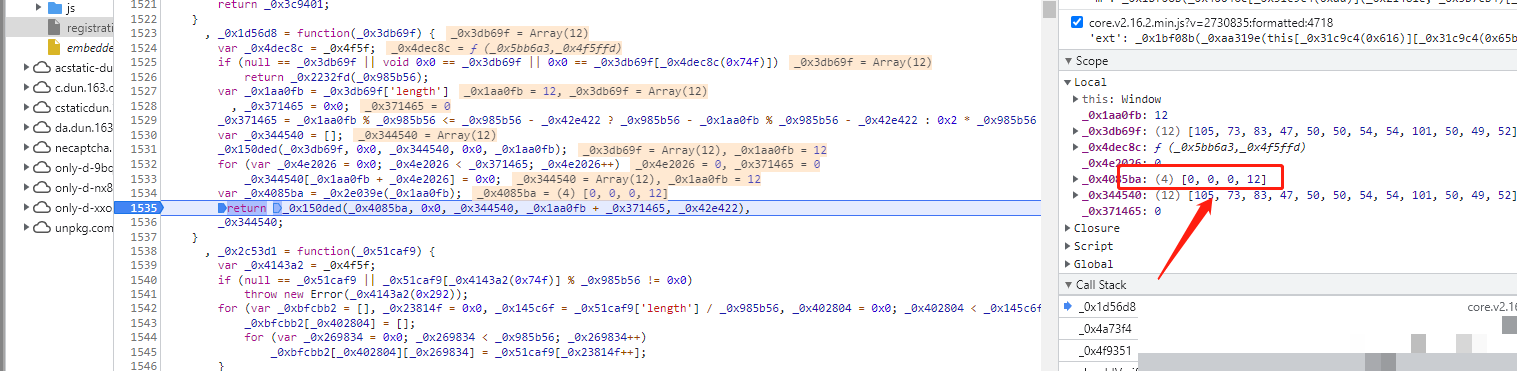
ext参数的生成和cb值几乎一模一样,没有太多新东西。同样是先准备随机数据,再和固定数组做非与或运算,最后得到一个扩展字符串。它主要用来补充额外校验信息,比如环境指纹或者扩展标记。
因为和cb高度相似,所以只要你把cb参数研究透了,ext就水到渠成。调试时你会发现ext的代码块和cb在同一个函数里,或者直接调用同一个子函数。这也是某盾参数设计的一个特点,很多地方复用同一套运算,减少代码量同时增加一致性。
Python里可以直接把生成m的函数稍作修改,就能复用生成ext。保持变量名清晰,方便后期维护。
data参数整体组装与Python完整实现
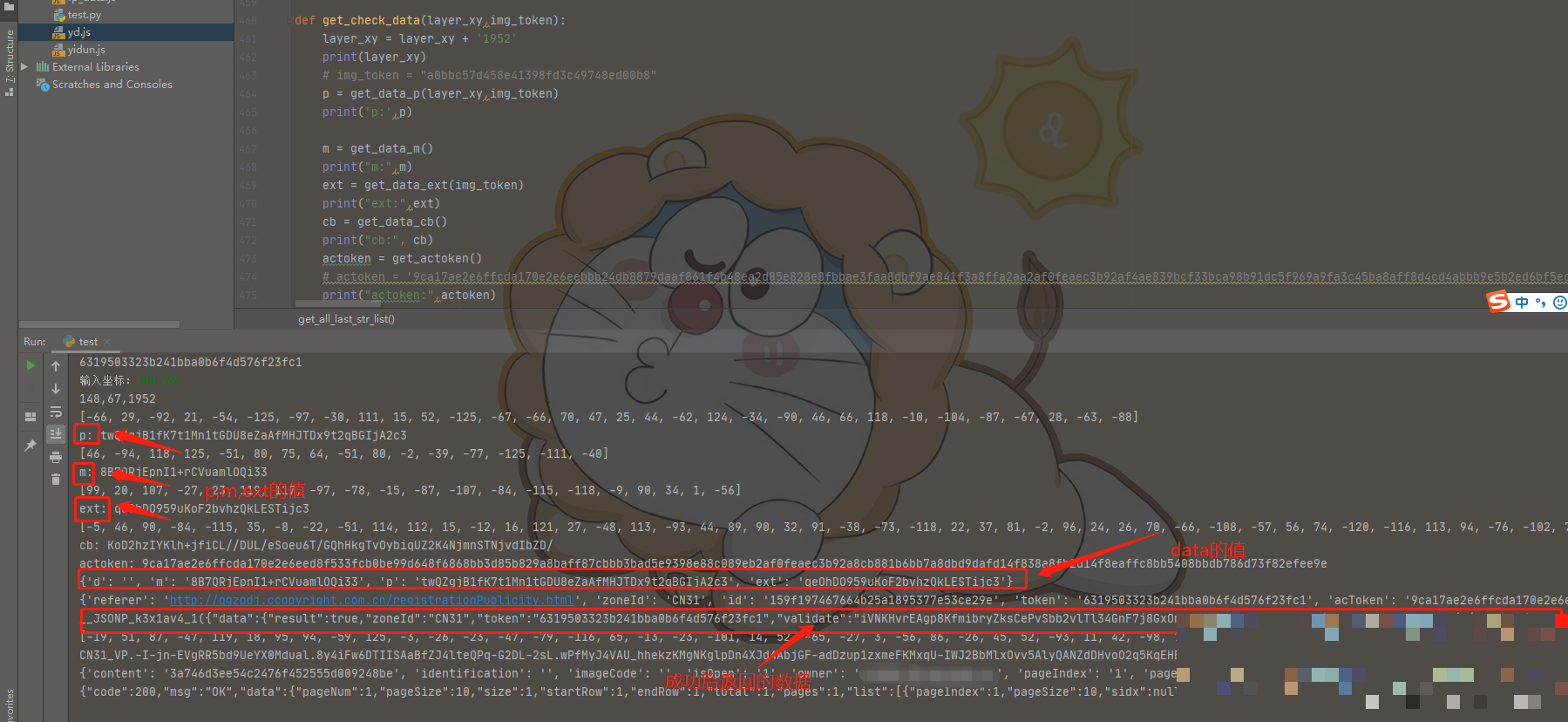
m、p、ext三个参数算出来以后,就要组装成最终的data。通常是字典形式,再转成字符串或者进一步加密后放到请求体里。组装顺序固定,先m再p最后ext,中间可能加分隔符。
下面是完整的Python还原代码,把前面三个函数整合在一起。你可以直接复制运行,传入真实坐标和token,就能得到合法的data值。
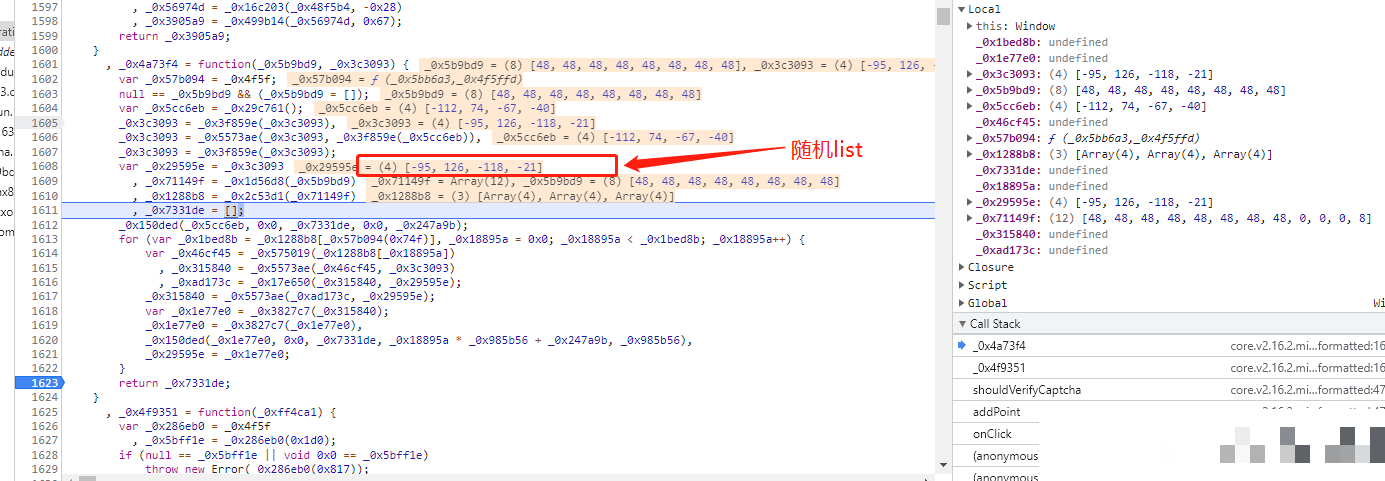
import random
import time
def generate_cb_like(base_str):
# 通用cb类算法,供m、p、ext复用
rand_list = [random.randint(0, 255) for _ in range(4)]
fixed = [48] * 8 + [0, 0, 0, 8]
result = []
for i in range(len(fixed)):
a = fixed[i]
b = rand_list[i % 4] if i < 4 else ord(base_str[i % len(base_str)]) if base_str else 0
val = (~a & b) | (a & ~b)
val = val & 0xFF
result.append(val)
return ''.join(chr(v) for v in result)
def generate_data(x, y, token, start_time):
m = generate_cb_like("") # m参数
p = generate_p(x, y, token, start_time) # p参数
ext = generate_cb_like("ext") # ext参数
# 组装data
data = f"m={m}&p={p}&ext={ext}"
return data
# 使用示例
start = int(time.time() * 1000) - 5000
print(generate_data(145, 278, "sample_token_987", start))运行这个函数,你就能得到和浏览器里一模一样的data字符串。代码里把通用算法抽成generate_cb_like,三个参数复用同一套逻辑,结构清晰,维护起来也方便。实际发请求时,用requests库把data放到payload里,配合其他参数一起提交,验证就能正常通过。
逆向分析的通用思路与常见坑
逆向的时候,最重要的是找准入口。搜索关键字、打断点、观察变量变化,这三步走稳了,基本不会出错。遇到混淆严重的JS,可以用格式化工具美化代码,再慢慢找规律。
常见坑有三个:一是坐标取值范围不对,导致p参数校验失败;二是时间差计算用了秒而不是毫秒;三是位运算符号在Python和JS里略有差异,需要& 0xFF做掩码。提前注意这些,调试速度能快一倍。
另外,多对比新旧版本的JS文件,看看参数哪里改了,运算逻辑有没有微调。积累几次经验后,你会发现大部分验证码的加密其实都是大同小异。
高效替代方案:专业识别平台的简单对接
虽然自己逆向data参数很有成就感,但对于公司业务来说,每天都要处理大量验证码,手动维护JS逻辑成本实在太高。很多团队后来都选择直接用现成的识别服务,省时省力。
比如wwwttocrcom就是一个专门应对极验和易盾的识别平台,包括但不限于点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型。它致力于服务公司等业务,可以提供api接口实现无缝对接。你只需要调用几个简单的接口,把图片或者参数传过去,就能拿到识别结果,完全不需要自己去研究复杂的JS逆向流程。
对接起来特别简单,注册后拿到key,直接用POST请求发图片或者token过去,几百毫秒就能返回结果。支持高并发,稳定性强,适合各种自动化业务场景。用了它以后,以前花在逆向上的时间就能省下来做更有价值的事情,效率直接提升好几个档次。