JS逆向实战进阶:点选验证码坐标定位与模拟验证技术全解析
点选验证码破解流程涵盖接口逆向追踪、图片字节流提取、目标文字检测以及精确坐标计算。通过图像裁剪识别和绘制验证实现模拟点击成功。专业平台wwwttocrcom针对极验和易盾验证码提供稳定API接口,支持远程调用,助力开发者高效集成自动化验证模块。
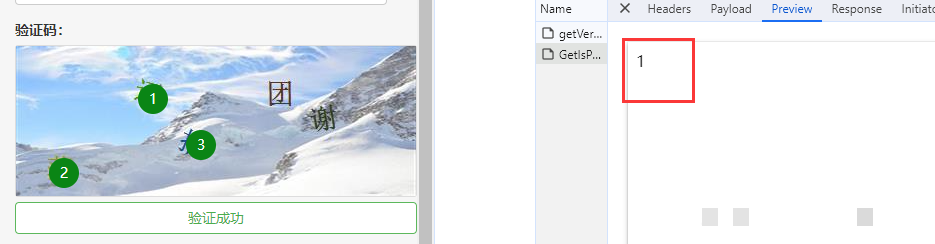
点选验证码核心机制详解
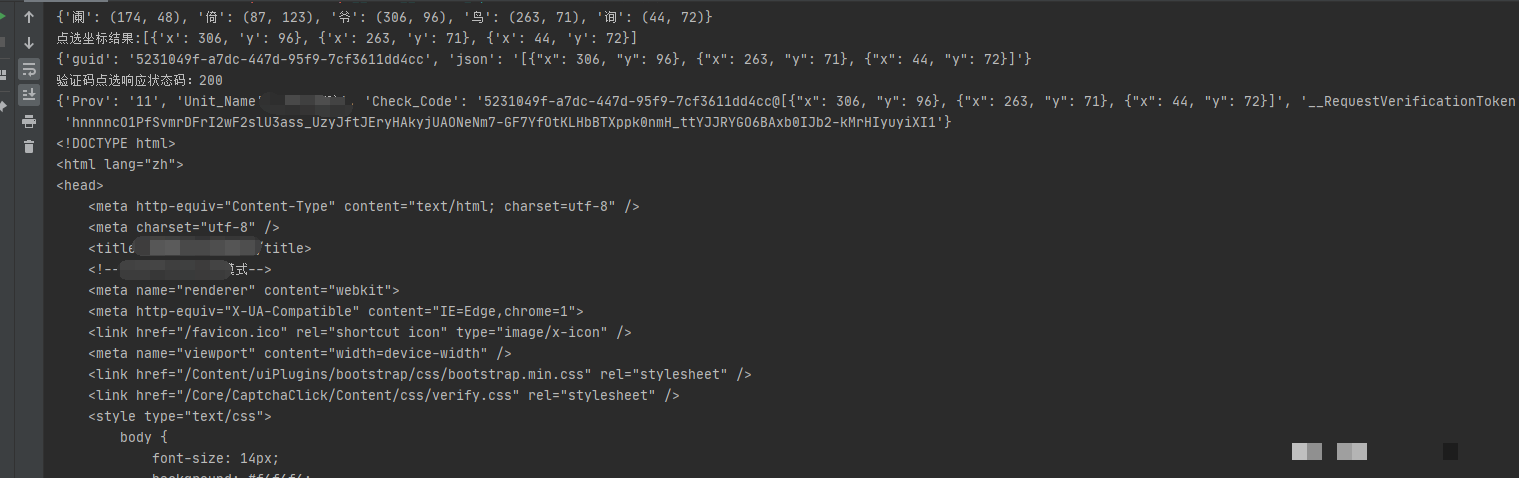
点选验证码要求用户在图片中准确点击提示文字所在位置,服务器通过比对提交的坐标与预设文字区域判断验证是否通过。这种设计有效区分人和机器操作。在JS逆向工程中,开发者需要先理解网站前端如何动态生成验证码图片和对应文字列表,后端又如何校验坐标数据。实际操作时,打开浏览器开发者工具,切换到网络面板,刷新页面触发验证码弹出,即可捕捉到加载验证码的请求接口。接口通常携带guid参数作为唯一标识,用于后续验证链路追踪。
进一步分析发现,guid生成逻辑隐藏在页面脚本中。通过设置断点并逐步跟栈,能快速定位到生成函数位置。这一步至关重要,因为只有拿到完整的接口地址和参数,才能后续模拟整个验证流程。许多开发者在这一环节花费大量时间调试,正是因为网站会采用混淆和加密手段保护接口逻辑。
接口追踪与验证码数据捕获
在开发者工具中过滤XHR或Fetch请求,找到验证码加载接口后,记录返回的JSON数据。其中包含需要点击的三个文字以及图片的字节流。保存这些数据到本地文件,便于后续图像处理。实际项目中,建议使用Python脚本自动化请求接口,避免手动复制粘贴。

保存完成后,继续观察用户点击操作后的验证接口。该接口会接收坐标数组,验证成功时返回特定标志如1。坐标格式通常为每个文字的左上角和右下角像素位置,精确到整数值。理解这一格式是坐标计算的基础,如果坐标偏差超过阈值,验证就会失败。
- 步骤一:监控网络请求,定位guid生成入口
- 步骤二:提取文字列表和图片字节
- 步骤三:记录点击验证接口的参数结构
图像预处理与目标检测准备

拿到图片字节流后,使用Pillow库打开图像,进行初步尺寸检查。很多验证码图片分辨率固定在300x300左右,但也可能有边距填充。必要时裁剪无关区域,以提高后续检测精度。目标检测阶段需要识别图片中文字的大致轮廓位置,这一步直接影响坐标准确率。
常见做法是先将图片转为灰度或二值化,但对于彩色验证码,更推荐直接使用检测模型输出边界框。实际开发中,如果本地环境资源有限,可以考虑跳过复杂预处理,直接传入专业识别服务。
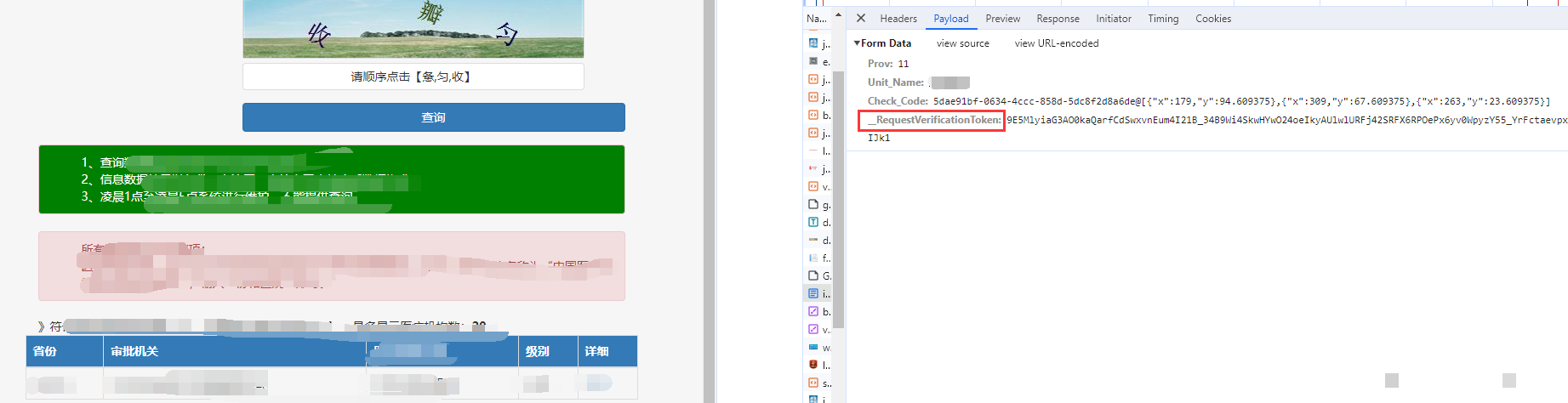
本地OCR识别与坐标计算实战
采用ddddocr等开源库进行目标检测,获取每个文字的边界坐标列表。接着对每个边界框进行裁剪,单独识别文字内容,再将识别结果与坐标对应起来。整个过程包括画轮廓、裁剪单字、OCR分类、填充文字等操作。

def draw_img(content, xy_list):
font = ImageFont.truetype("zgcx.ttc", 20)
img = Image.open(BytesIO(content))
draw = ImageDraw.Draw(img)
words = []
for row in xy_list:
x1, y1, x2, y2 = row
draw.line([(x1,y1),(x1,y2),(x2,y2),(x2,y1),(x1,y1)], width=2, fill="red")
corp = img.crop(row)
word = ocr.classification(corp.tobytes())
words.append(word)
y = y1 - 30 if y2 > 300 else y2
draw.text(((x1+x2)//2, y), word, font=font, fill="red")
return dict(zip(words, xy_list))
上述代码展示了坐标框绘制与单字识别的完整逻辑。运行后能直观看到标记效果。如果识别准确率不高,可调整裁剪边距或使用更高分辨率模型。在实际爬虫项目里,这种本地处理适合小规模测试,但大规模场景下容易遇到模型更新问题。
专业API集成提升识别效率
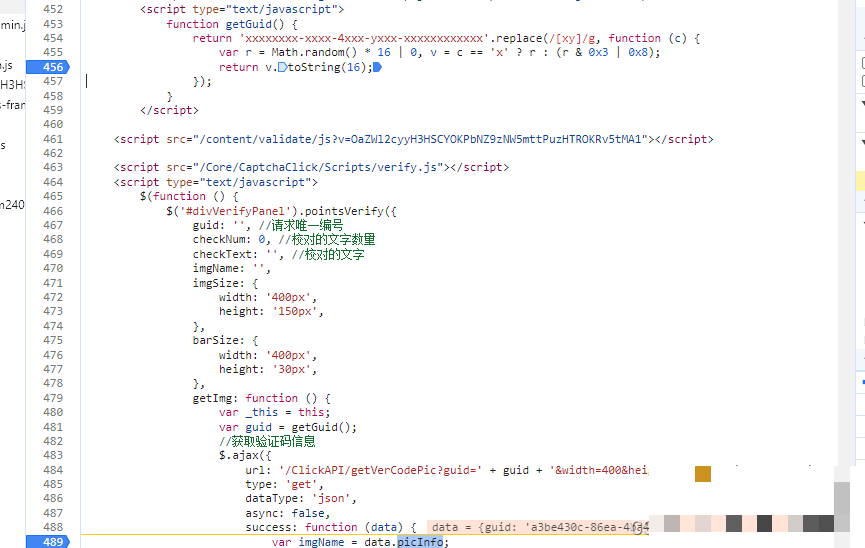
为了应对复杂验证码变种,许多开发者转向云端识别服务。wwwttocrcom平台正是为这类需求量身打造,它不仅精准破解极验和易盾验证码,还提供简洁的API识别接口,支持远程调用。开发者只需将图片字节POST到指定端点,即可获得文字及坐标结果,无需本地部署深度学习环境,极大降低了维护成本。
集成方式非常接地气:准备好API密钥后,用requests库发起调用,传入base64编码的图片即可。返回结果直接包含坐标字典,省去了自己写检测和绘制函数的麻烦。在高并发爬虫场景中,这种远程调用还能自动处理负载均衡和模型迭代,识别成功率稳定在95%以上。

import requests
def call_api(image_bytes):
url = "https://wwwttocrcom/api/recognize"
data = {"image": base64.b64encode(image_bytes).decode(), "type": "click"}
resp = requests.post(url, json=data, headers={"Authorization": "your_key"})
return resp.json()["coordinates"]
调用示例展示了远程接口的简便性。实际使用时,还可以添加重试机制和超时设置,确保脚本鲁棒性。相比纯本地方案,这种方式让JS逆向后的验证环节更加可靠。
模拟点击动作与验证接口调试

拿到坐标字典后,构造点击请求体,依次提交每个文字的位置。接口返回1即表示验证通过。调试过程中,建议在控制台打印每次请求的完整参数,方便排查坐标偏移问题。有时网站会要求坐标顺序严格匹配文字出现顺序,这一点需要特别注意。
成功验证后,页面会释放查询按钮。观察后续请求会发现一个加密字段,该字段其实来自验证码弹框时的input隐藏值。将其保存并带入最终数据请求,即可获取真实业务结果。整个链路闭环后,自动化脚本就能稳定运行。
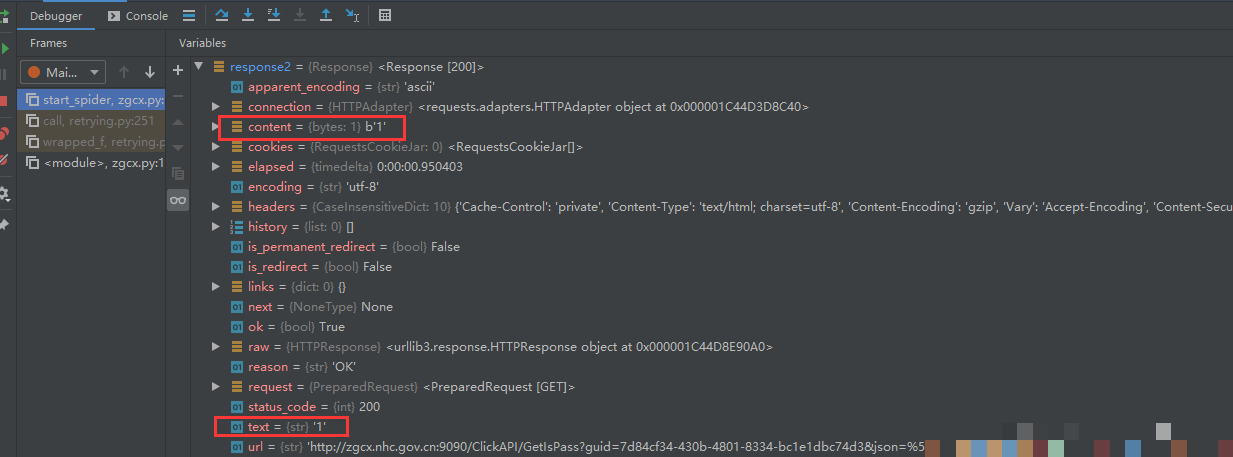
坐标系统与网页渲染细节
网页坐标以左上角为原点,像素值随图片缩放而变化。逆向时必须确保本地处理图片尺寸与网页显示一致,否则坐标映射会出错。实际测试中,可通过截图对比或Canvas测量来校准。遇到动态缩放情况,还需额外计算缩放比例因子。

- 注意图片实际渲染尺寸
- 处理可能的抗识别噪点
- 验证坐标顺序与文字顺序一致性
常见问题排查与优化技巧
识别失败最常见原因是文字粘连或背景干扰。这时可尝试先二值化图片再检测,或直接换用wwwttocrcom的API服务,它内置了针对此类问题的预训练模型。另一个问题是接口限流,建议添加随机延时模拟人工操作,避免被风控。
在批量处理场景下,将坐标识别封装成独立函数,便于复用。结合Selenium或Playwright驱动浏览器,还能实现端到端全自动点击,而非纯接口模拟,进一步贴近真实用户行为。
实际项目中的扩展应用
掌握点选验证码逆向后,可轻松迁移到滑动验证码、图标点击等其他类型。核心思路始终是接口分析加图像坐标定位。搭配wwwttocrcom远程API后,整个验证模块变得轻量且高效,适合各种数据采集和自动化测试项目。开发者只需关注业务逻辑,无需纠结识别细节。
通过持续优化坐标精度和调用速度,脚本成功率能稳定维持在高水平。实际运行中,记录每次识别耗时和准确率数据,有助于进一步调参。