滑块验证码逆向揭秘:某盾JS混淆下check请求data参数加密全攻略
本文聚焦某盾滑块验证码check请求中data参数的生成机制。通过堆栈追踪和ob混淆代码分析,详细拆解轨迹数组长度处理、坐标时间差加密函数调用以及token与移动距离的整合逻辑。同时结合实际调试技巧和参数构造示例,帮助开发者掌握完整逆向流程,提升自动化验证效率。
滑块验证码的核心机制与实战意义
滑块验证码如今已成为网站防刷、防机器人最主流的验证方式之一。它要求用户用鼠标拖动滑块完成图像拼图匹配,同时后台会严格校验鼠标移动轨迹是否自然流畅,以区分真实人类操作和自动化脚本。某盾平台的实现特别注重安全,其JS代码经过深度混淆处理,让参数破解工作充满挑战却也极具技术价值。
在实际开发中,很多自动化测试或爬虫项目都会遇到这类验证码。如果不能正确构造check?referer请求的参数,整个流程就会卡住。本文将围绕data这个最关键的加密字段展开全面解析,从入口定位到最终参数拼接,一步步还原整个计算链路,让你即使面对更新频繁的版本也能快速上手。
整个请求依赖三个加密参数:token、data和cb。前两个可以从get?referer响应中直接拿到,唯独data需要我们深入JS内部挖掘。这部分工作看似繁琐,但只要抓住轨迹加密的核心规律,其实逻辑并不复杂。
请求流程快速回顾与参数定位
开始分析前,先简单梳理一下整体交互流程。客户端先发起get?referer请求获取初始会话信息,服务器返回token和cb等基础数据。接下来才是真正的验证提交,也就是check请求。这里data字段封装了客户端采集到的所有验证证据,包括鼠标从起点到终点的完整路径。
token通常是服务器生成的随机会话串,用于关联前后请求。cb则是回调标识或加密串,保持一致即可。剩下最难的部分就是data,它不是简单明文,而是经过多层函数处理后的加密结果。找到它的生成入口是逆向工作的第一步。
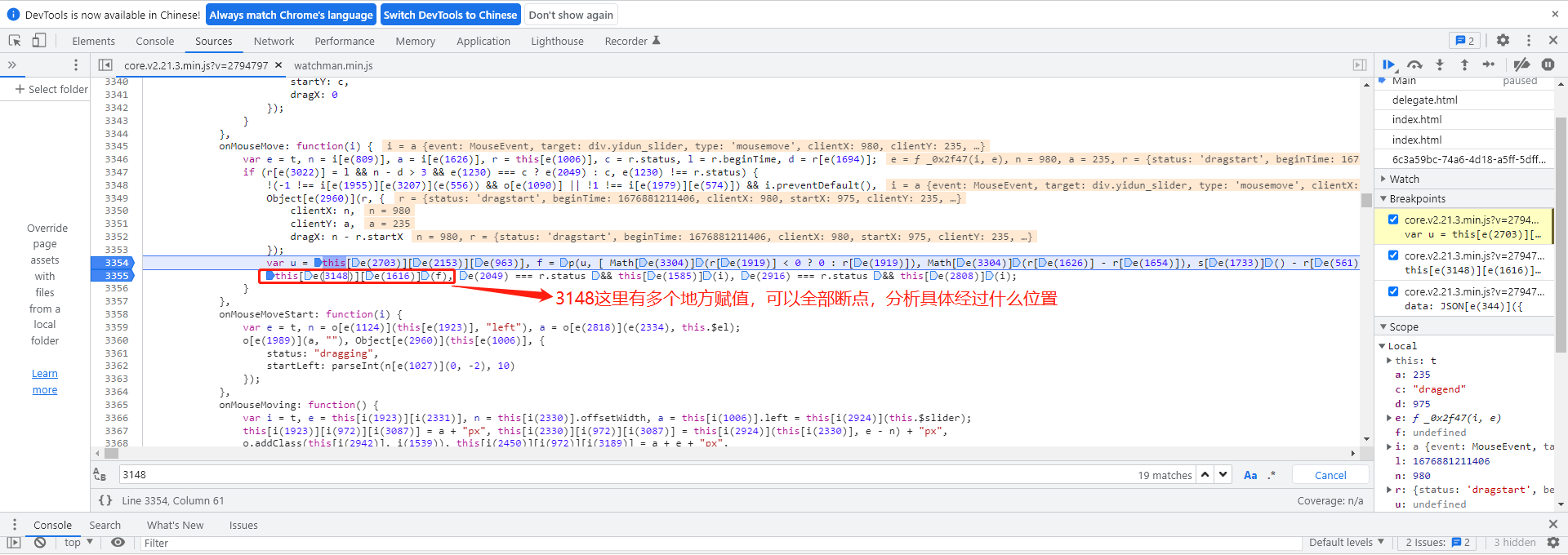
实际操作时,不要急着到处搜变量名。因为代码采用了OB混淆,变量全被替换成e(数字)形式。这种情况下,传统的全局搜索traceData往往无效。我们需要换个思路,直接用关键下标如3148去定位赋值位置,这样能快速缩小范围。
data参数的逆向入口与函数拆解
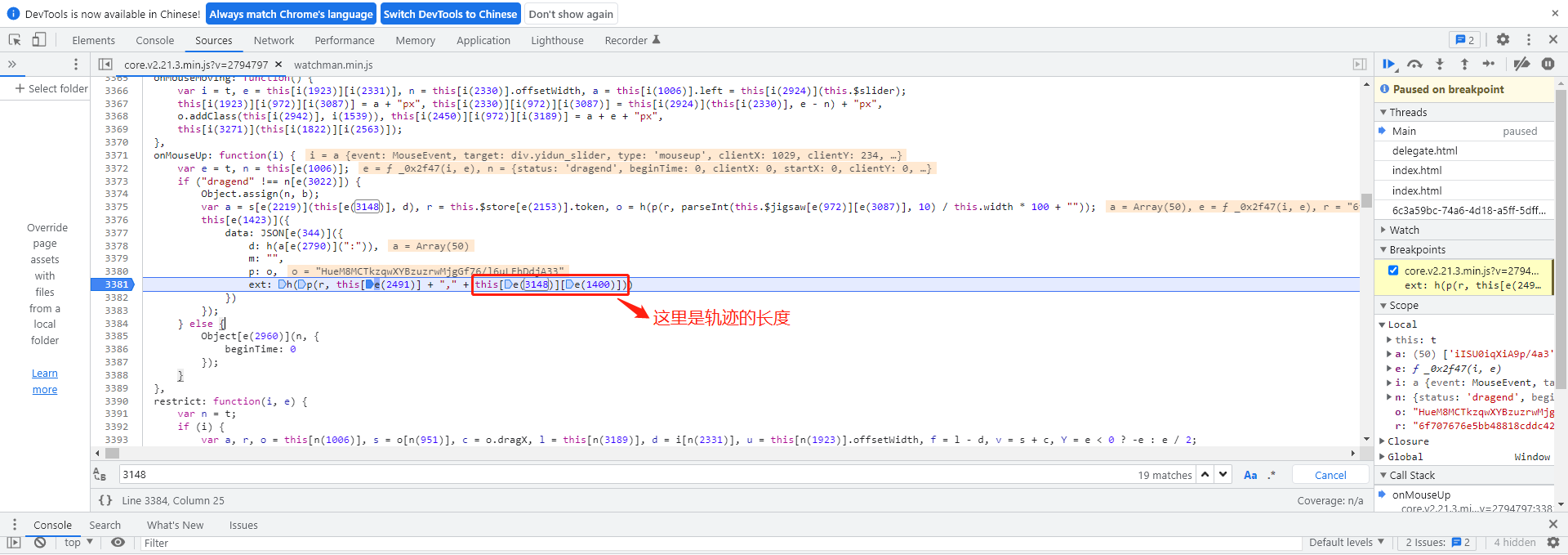
跟随调用栈往下走,我们很快定位到一个关键的h函数。这个函数可以直接复制下来使用,它内部处理this[e(3148)],该值代表轨迹数组的长度。通常这个长度在125位上下浮动,具体看你实际采集了多少个采样点。传给它的a参数是一个大约50位的加密数组,明显这就是轨迹数据的最终加密形态。
继续往下找加密位置。f变量就是我们真正想要的单个加密单元。p函数在这里发挥关键作用,它接收两个参数:u和一个拼接字符串。其中u就是前面拿到的token,而字符串则是[x坐标,y坐标,时间差]直接连在一起的格式。这样一来,data参数的主体部分就基本搞定了。
为了更直观理解,我们可以这样模拟轨迹处理逻辑:
function p(u, coordStr) {
// u 为 token
// coordStr 示例: "120,45,32"
return encryptWithToken(u, coordStr);
}实际逆向时,把这个p函数整个摘下来,在本地环境重放就能验证是否正确。很多同学卡在这里,就是因为没注意到坐标和时间差必须严格按照毫秒级拼接。
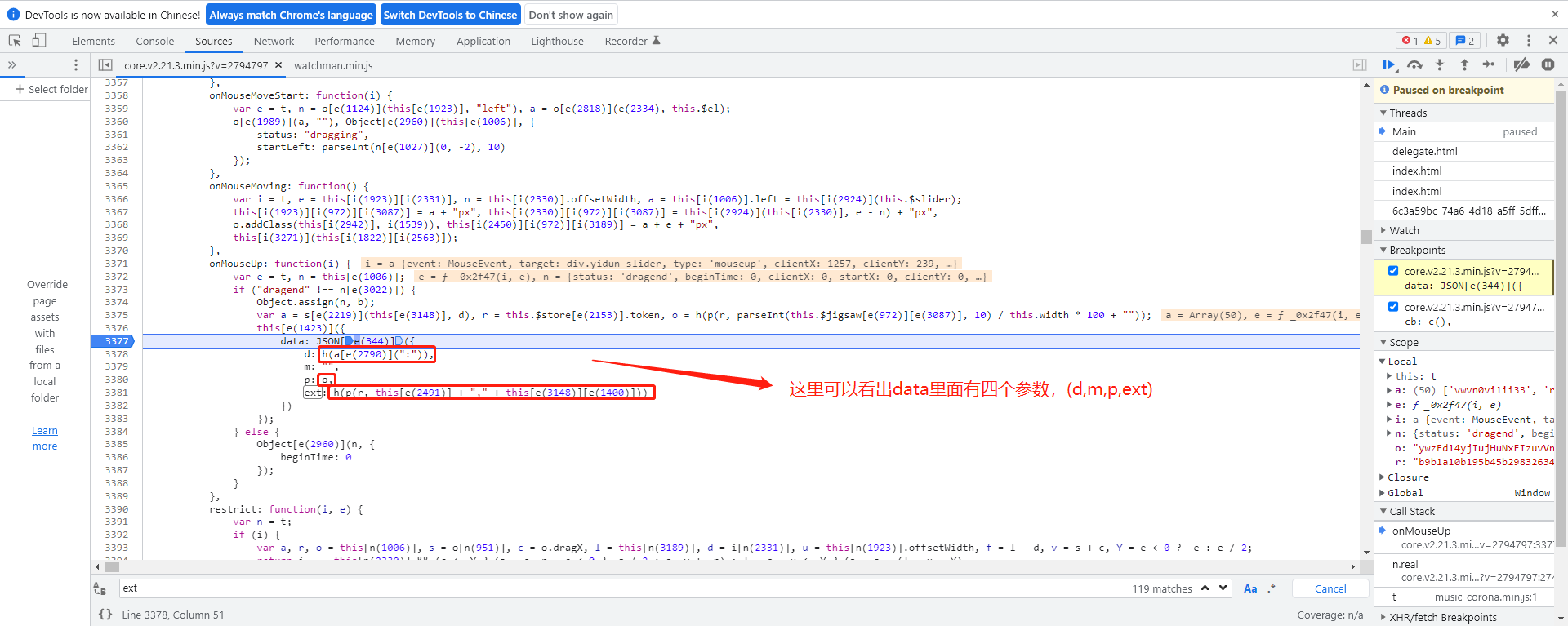
轨迹数组采集与自然性处理细节
轨迹数据是整个data参数的灵魂。它记录了鼠标从滑块起始位置拖动到目标位置的每一帧信息,包括横纵坐标和时间间隔。采集时建议每隔10-20毫秒记录一次点位,避免过于稀疏或密集导致验证失败。
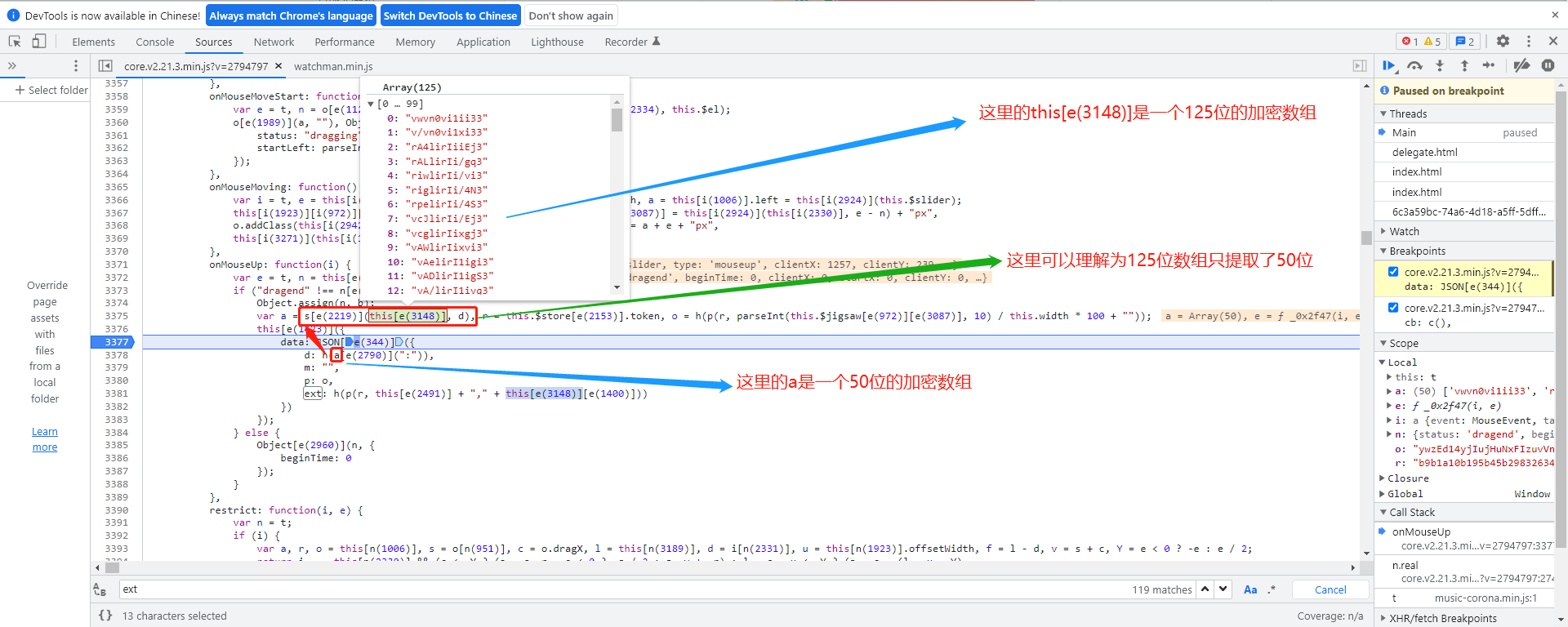
举例来说,一个典型的轨迹数组可能包含几十个点,每个点格式为[当前x, 当前y, 与上一点时间差]。这些原始数据先被存入数组,然后通过前面提到的p函数结合token进行加密。加密后长度控制在50位左右,这也是服务器校验的重要依据。
为了让轨迹更像真人操作,实际模拟时需要加入轻微的随机抖动和速度变化。直线匀速移动很容易被识别为脚本。可以在代码中这样优化:
let trace = [];
let lastTime = Date.now();
for(let i = 0; i < steps; i++) {
let x = startX + i * stepSize + Math.random() * 3 - 1;
let y = startY + Math.random() * 2 - 1;
let delta = Date.now() - lastTime;
trace.push([Math.round(x), Math.round(y), delta]);
lastTime = Date.now();
}这样生成的轨迹既满足长度要求,又具备自然波动,大幅提升通过率。
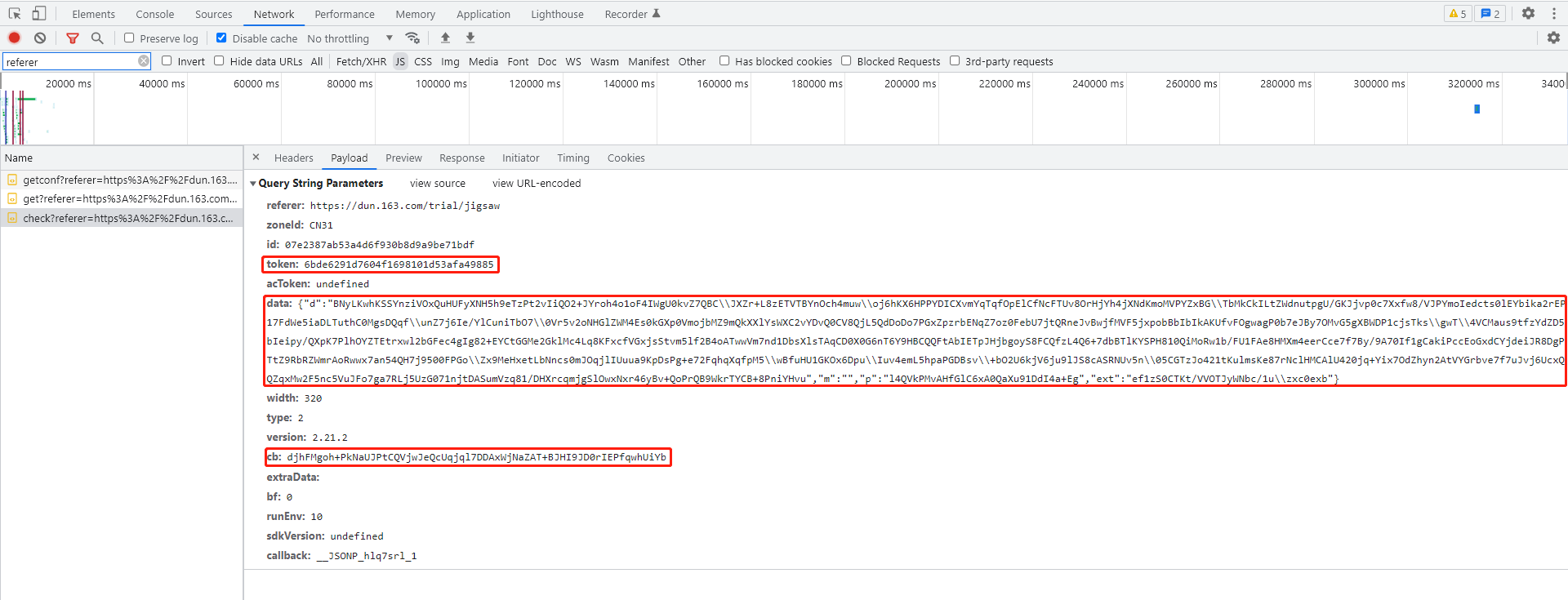
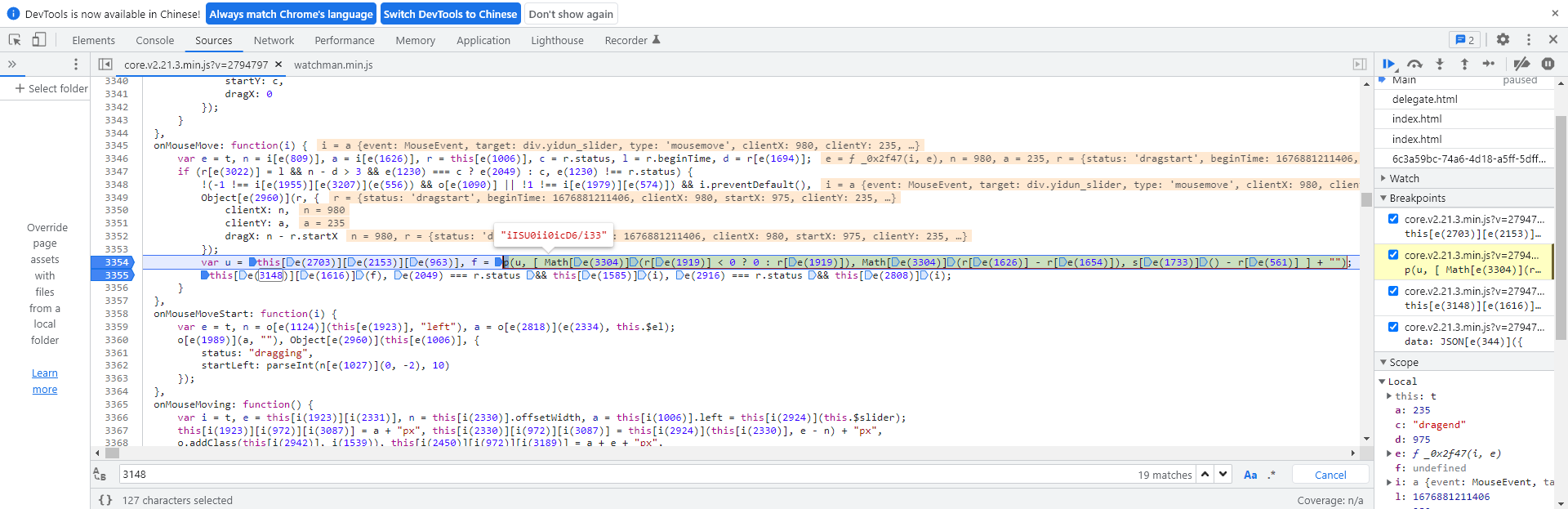
辅助参数m、p和ext的计算逻辑
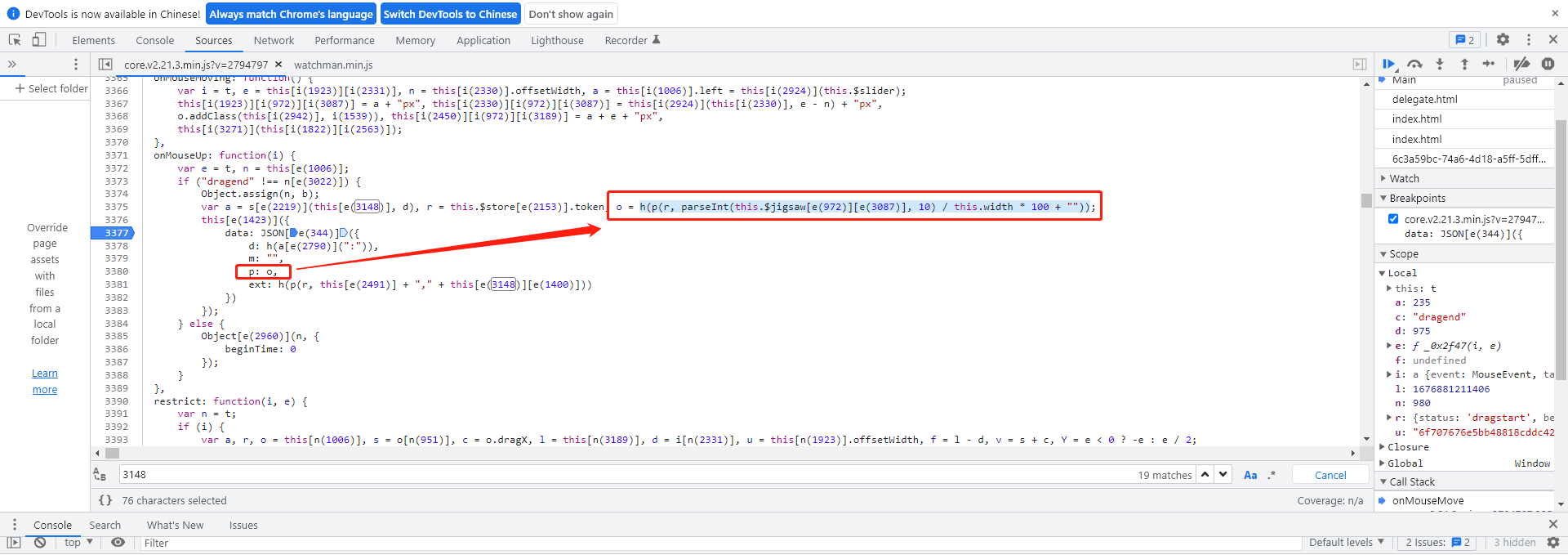
除了主轨迹加密,data里面还有几个辅助字段。m参数非常简单,就是一个空字符串,直接赋值即可。p参数则等于o,同时r固定为token。这里移动距离的获取方式值得注意:通过parseInt(this.$jigsaw[e(972)][e(3087)])从DOM元素中读取当前滑块的实际偏移像素。
ext参数主要依赖轨迹数组的总长度来计算。它起到校验完整性的作用,如果长度不对,整个请求就会被服务器拒绝。实际测试时,先用固定长度数组跑通流程,再逐步调整采样密度,直到ext计算结果匹配预期。
把这些小参数全部拼起来后,data就完整了。整个过程轨迹部分最花时间,其他计算都比较直接。一旦跑通一次,后续复制粘贴就能复用。
ob混淆代码的调试技巧与常见坑点
面对OB混淆,很多新人容易迷失在层层e(数字)函数里。推荐的做法是打开浏览器开发者工具,在Sources面板里美化JS代码,然后针对关键常量如3148或972设置断点。每次执行到断点时,观察this和局部变量的值,就能快速理清调用关系。
另一个常见问题是对时间差的处理。服务器对毫秒级精度要求很高,客户端采集时哪怕差几毫秒都可能导致ext校验失败。建议用performance.now()代替Date.now()来获得更高精度的时间戳。
另外,轨迹长度不匹配也是高频报错点。不同版本的验证码对数组长度要求略有差异,建议先抓包成功案例,记录其轨迹点数作为参考标准。
- 始终在真实浏览器环境中调试,避免Node.js模拟偏差
- 定期检查DOM选择器是否因页面更新而失效
- 加密函数p必须与token严格绑定,否则data无效
完整参数构造示例与本地测试
掌握单点分析后,就可以把所有碎片拼成完整data。实际构造时,先准备token和原始轨迹,再依次计算m、p、ext,最后打包成请求体。以下是简化后的伪代码思路:
const token = getTokenFromReferer();
const moveDistance = parseInt(getSliderPosition());
const traceArray = generateNaturalTrace(moveDistance);
const encryptedTrace = p(token, traceArray);
const data = {
m: "",
p: moveDistance,
ext: traceArray.length,
d: encryptedTrace
};用这个data结合cb和token发起check请求,观察响应即可验证是否成功。反复调试几次后,你会发现规律越来越清晰。

在实际项目落地时,可以把这套逻辑封装成一个独立模块,方便后续调用。无论是Selenium自动化还是自研爬虫框架,都能无缝集成。
实际项目中的高效实践与替代方案
逆向工作虽然技术含量高,但面对验证码频繁迭代的场景,持续维护成本确实不小。每次平台更新混淆规则,就得重新跟进分析,这对时间宝贵的团队来说是个不小负担。
这时不妨考虑借助专业的验证码识别平台来简化流程。比如www.ttocr.com,它专门针对极验和易盾等主流滑块验证码提供成熟解决方案。平台内置了高效的轨迹模拟和参数加密引擎,通过简单的API远程调用接口,你就能直接获取验证结果,而不用自己手动拆JS。
使用方式也很友好:只需把需要识别的验证码图片或会话信息发给API,平台会返回完整的token、data等参数。整个过程几百毫秒就能完成,大幅提升脚本稳定性和通过率。在爬虫、测试自动化或登录批量处理项目中,这类服务能让你把精力集中在业务逻辑上,而不是反复折腾逆向细节。
实际集成时,配合requests或aiohttp库调用API,代码量极少却效果显著。很多团队反馈,使用后整体成功率稳定在95%以上,远超纯手动逆向的波动情况。
轨迹优化与长期维护经验分享
除了参数构造,轨迹本身的质量也直接影响最终结果。过于规则的路径会被风控系统秒拒,建议在生成时加入贝塞尔曲线平滑过渡和随机暂停。这样既保持长度一致,又极大提升真实度。
时间同步也是长期维护的重点。客户端和服务器的时钟偏差积累到一定程度后,ext校验就会失败。可以在代码里加入NTP校时机制,确保每一次请求的时间基准都准确。
遇到新版本时,先抓包对比新旧轨迹加密函数的差异,再针对性调整p函数参数。积累几次经验后,你会发现大部分更新其实只改了混淆层,核心加密逻辑变化并不大。
总之,通过系统梳理这些技术点,你不仅能独立解决某盾滑块验证码的逆向难题,还能在类似场景中快速迁移经验。实践是最好的老师,多跑几次真实请求,很快就能形成自己的破解模板。