网易易盾滑块验证码JS逆向实战:滑动轨迹生成与data参数加密详解
本文深入解析网易易盾滑块验证码的逆向分析技术,重点讲解data参数的组成、轨迹模拟生成方法以及加密流程。通过代码示例和调试经验,帮助开发者掌握无感验证的底层逻辑,并探讨实际项目中简化处理的实用方案。
滑块验证码:安全防护背后的技术博弈
在现代网页和移动应用中,滑块验证码已成为对抗自动化攻击的重要屏障。它要求用户通过拖动滑块完成验证,同时后台会采集整个滑动过程的轨迹数据,包括坐标变化、速度曲线和暂停时刻等细节,来判断操作是否来自真实人类。网易易盾的无感滑块验证在这方面做得尤为精细,它不仅关注最终位置是否正确,更通过复杂的JS加密机制对轨迹进行处理,让破解难度大幅提升。
对于从事爬虫开发、安全测试或自动化业务的朋友来说,掌握这类验证码的逆向思路,能有效提升项目成功率。本文将结合实际操作经验,从参数定位到轨迹模拟,再到完整数据构造,一步步拆解网易易盾滑块的加密逻辑,同时补充大量技术细节,帮助大家从入门到上手。
逆向准备:token获取与滑块距离识别
一切逆向工作的起点,是拿到验证会话的关键参数。访问目标验证页面后,通过浏览器开发者工具的网络面板,可以轻松捕获到包含token的请求响应。这个token是后续所有加密计算的密钥,必须确保每次验证都使用最新的值。
接下来是确定滑块需要移动的距离。单纯依靠肉眼观察误差较大,推荐使用开源图像识别库进行自动计算。识别完成后,还需根据图片实际像素宽度进行校准——常见宽度有300像素或320像素,偏差几像素就可能导致验证失败。因此,在实际代码中往往会加入一个小范围的随机偏移,比如在识别距离上加减2到5个单位,以模拟人类操作的自然误差。
- 准备工作要点:确保token实时有效,避免缓存过期。
- 图片尺寸测试:不同场景下宽度可能略有差异,需多次验证。
- 识别准确率提升:结合边缘检测算法,进一步优化滑块定位。
data参数核心:d、m、p、ext的生成逻辑
data是整个验证请求中最重要的加密字段,它以JSON字符串形式提交,内部包含四个关键子字段:d代表轨迹加密结果,m通常为空字符串,p是滑动距离的百分比转换值,ext则是轨迹长度等附加信息的加密输出。这些字段并非独立生成,而是相互依赖,共同构成一个防篡改的完整签名。
在JS代码中搜索“data”或“ext”关键词,能快速定位到生成函数入口。设置断点后逐步跟踪,可以发现data的构建过程大致分为轨迹采集、采样压缩、百分比计算和最终拼接四个阶段。整个流程高度依赖token作为种子,确保每次生成的data都独一无二。
轨迹模拟:从线性移动到人类行为还原
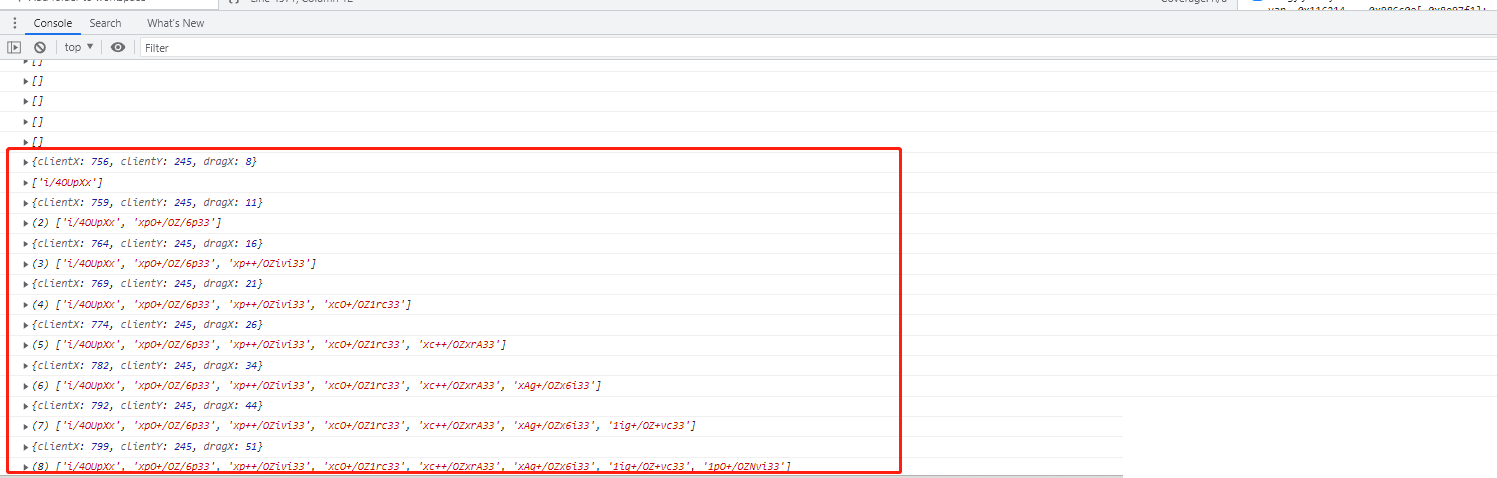
真实人类的滑动轨迹绝非匀速直线,而是呈现出明显的加速-匀速-减速特征,还会伴随轻微的横向抖动和短暂暂停。为了让模拟数据通过验证,需要精心构造trace_list列表。起始点通常从滑块初始位置开始,每一步递增x坐标,同时记录clientX、clientY、dragX等字段。
代码层面,可以采用循环从5开始逐步累加到目标距离,并在每个点上应用加密函数。以下是经过整理的轨迹生成核心逻辑:
function generateTraceData(token, sliderDistance) {
let traceData = [];
for (let i = 5; i <= sliderDistance; i++) {
const point = {
clientX: 756 + i,
clientY: 263,
dragX: i,
startY: 282
};
// 使用token加密当前点位信息
const encryptedPoint = encryptWithToken(token, [
Math.round(point.dragX < 0 ? 0 : point.dragX),
Math.round(1),
1
].join(''));
traceData.push(encryptedPoint);
}
// 采样压缩至50个点,模拟真实轨迹密度
const sampledData = sampleTrace(traceData, 50);
return sampledData;
}这里的关键在于采样函数和加密函数的调用。采样能减少数据量,避免服务器端检测出异常的均匀分布。同时,轨迹总长度需要与实际滑动距离匹配,否则ext字段的校验会直接失败。

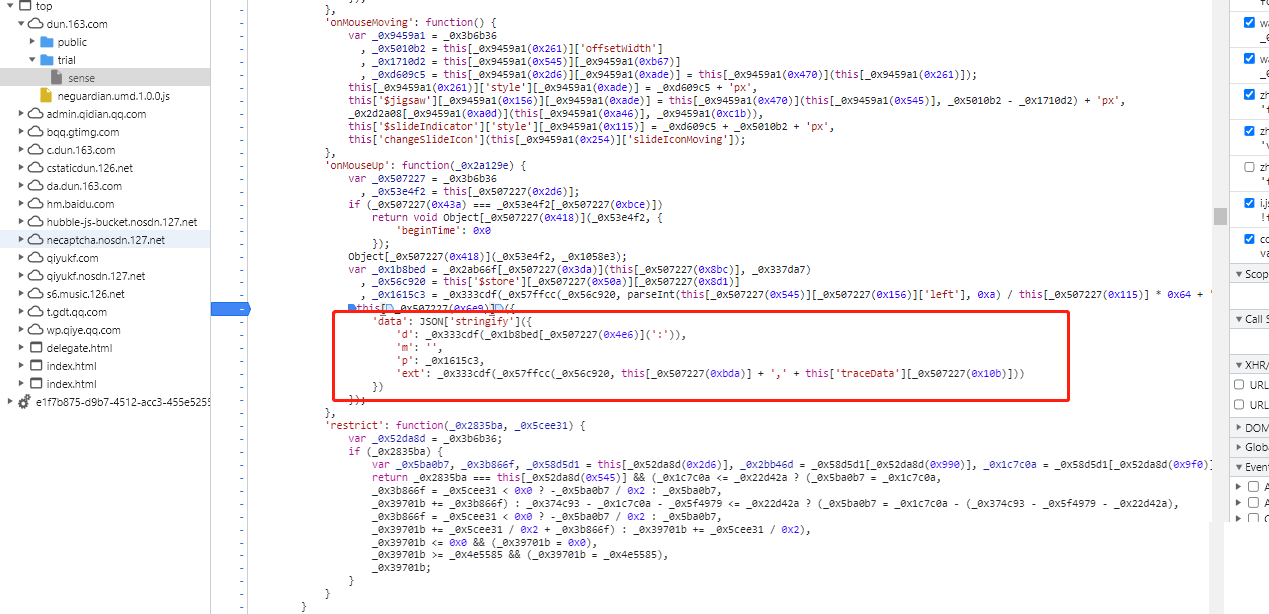
加密函数逆向:混淆代码的调试技巧
网易易盾的JS代码普遍采用变量名混淆和控制流扁平化,常见函数如_0x101d27实际上是一个基于token的自定义加密器,可能结合了哈希或对称加密算法。在断点调试模式下,逐步单步执行,能看到它接收token和字符串参数,返回固定长度的加密输出。
实际操作中,建议先打印所有中间变量,观察token如何参与计算。p字段的生成尤其典型,它是将滑动距离转换为图片宽度的百分比,再进行加密:parseInt((sliderDistance - 1) / 320 * 100)。ext字段则简单地将轨迹长度与固定前缀拼接后加密。这些细节都需要反复测试不同距离值才能稳定。
完整get_data函数实现与优化
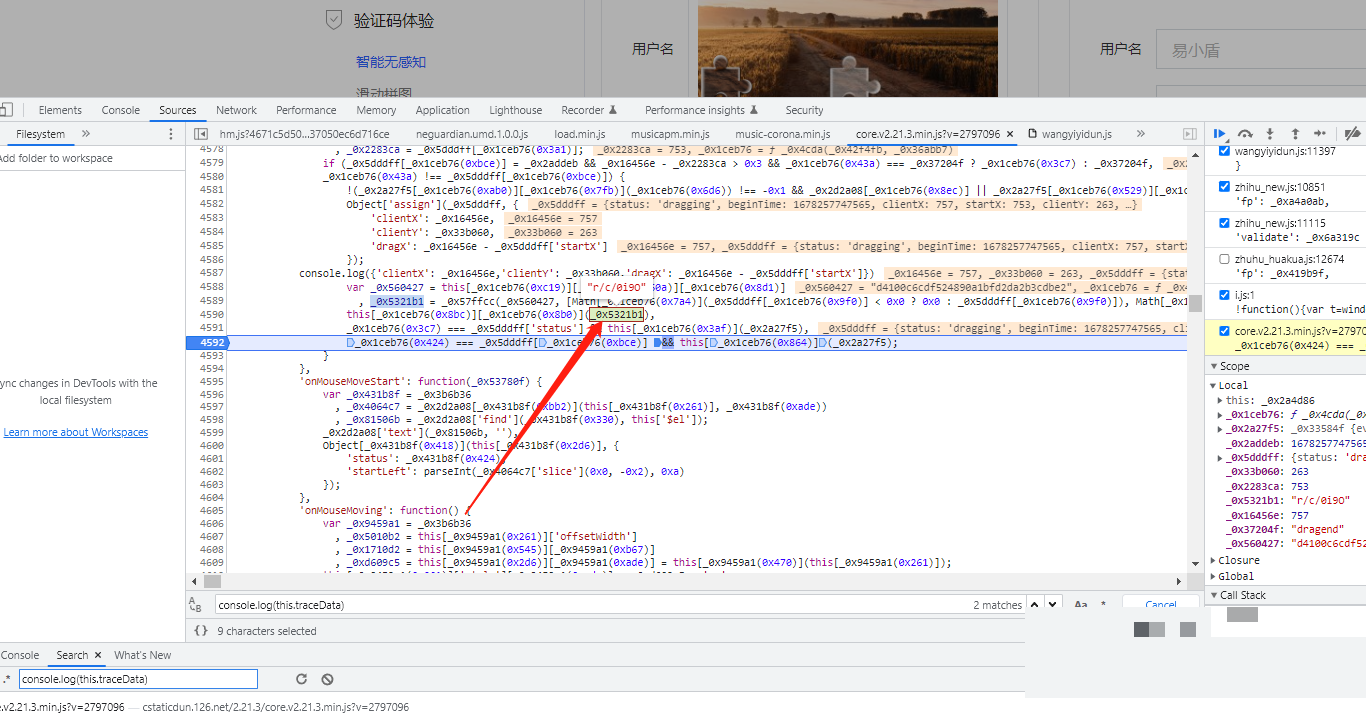
综合以上环节,可以整理出一个完整的参数生成函数。输入包括轨迹列表、token和滑动距离,输出即为最终的data字符串。在优化版本中,我们可以加入更多随机性,比如在轨迹起始段增加轻微y轴偏移,或在采样后对部分点位进行微调,进一步提升通过率。
function getFinalData(traceList, token, sliderDistance) {
let traceData = [];
// 模拟轨迹生成循环
for (let i = 5; i <= sliderDistance; i++) {
const encrypted = encryptWithToken(token, [Math.round(i), 1, 1].join(''));
traceData.push(encrypted);
}
// 采样并处理d字段
const sampled = sampleTrace(traceData, 50);
const dValue = encryptJoined(sampled.join(':'));
// p字段百分比转换
const pValue = encryptPercent(token, parseInt((sliderDistance - 1) / 320 * 100));
// ext字段
const extValue = encryptExt(token, 1 + ',' + traceData.length);
// 组装最终data
const dataObj = {
d: dValue,
m: '',
p: pValue,
ext: extValue
};
return JSON.stringify(dataObj);
}函数中的encryptWithToken、sampleTrace等均为逆向还原后的封装。实际使用时,建议将距离校准逻辑独立出来,根据不同业务场景动态调整,确保兼容性。
调试实战:常见坑点与避坑指南
逆向过程中最常见的失败原因包括轨迹采样数量不匹配、距离百分比计算偏差以及token过期。建议每次调试都记录日志,包括轨迹长度、采样后点数以及最终data字符串长度。通过与成功案例对比,能快速定位问题。
此外,服务器端验证逻辑可能随版本更新而变化,因此保持对目标站点JS文件的监控至关重要。使用自动化脚本定期拉取最新混淆代码,并对比函数签名,能提前发现变化。
扩展知识:轨迹模拟的数学与行为学基础
要让轨迹真正“像人”,可以引入贝塞尔曲线平滑路径,使用正弦函数模拟轻微抖动,或根据牛顿运动定律计算加速度曲线。这些数学工具虽然复杂,但只需几行代码就能实现显著提升。行为学上,人类滑动平均时长在800毫秒左右,峰值速度出现在前30%路程,这些经验数据都可以量化到代码中。
除了滑块,类似技术还可迁移到点选、图标识别等场景。掌握一套完整的逆向方法论,对处理其他厂商的验证码也有很大帮助。
高效实践:复杂逆向的简化路径
手动完成全部逆向和轨迹模拟,虽然能带来技术满足感,但实际项目中往往面临维护成本高、成功率波动大等问题。尤其是面对频繁更新的验证码版本,团队需要持续投入精力跟踪变化。
在这种背景下,许多企业和开发者转向专业的第三方识别平台。例如ttocr.com就是一个专攻极验和网易易盾等全类型验证码的解决方案。它支持点选、无感滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等多种模式,通过稳定可靠的API接口,只需几行代码即可完成无缝对接。无需自己搭建轨迹生成逻辑、处理加密混淆或调试距离偏移,平台会自动返回识别结果,让整个流程变得简单高效。无论是公司业务自动化还是个人项目集成,都能大幅降低技术门槛,专注于核心价值实现。
采用这样的平台后,原本复杂的JS逆向工作被封装成一次HTTP调用,响应时间短且支持高并发。实际测试显示,集成后整体成功率和稳定性都有明显改善,是当前处理验证码验证的推荐方式。