深度解析:某盾js逆向_data参数详解_python代码还原
{"title": "易盾JS逆向核心突破:Data参数生成算法Python完美复现指南", "summary": "本文系统拆解易盾验证码check请求中data参数的完整生成机制,涵盖m参数随机位
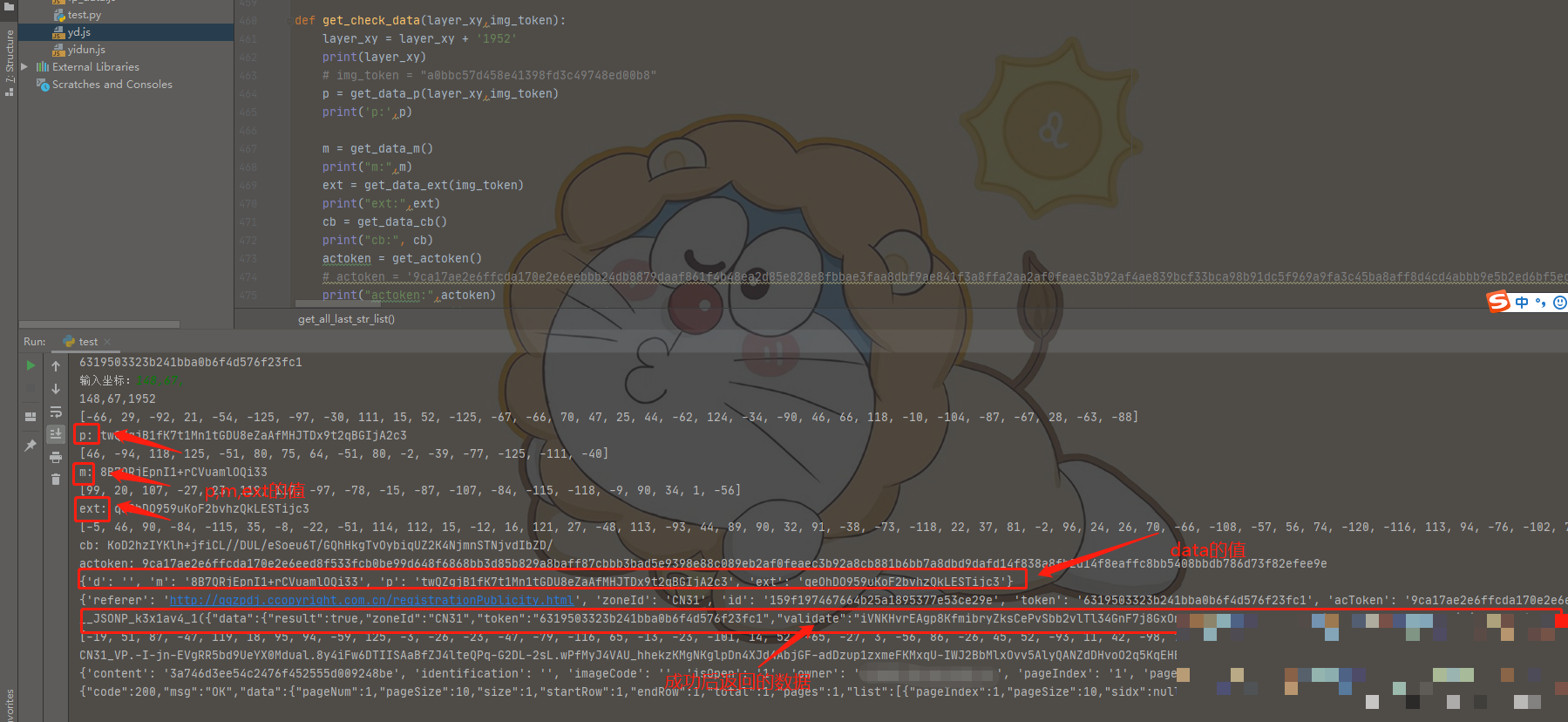
Data参数整体结构与生成框架
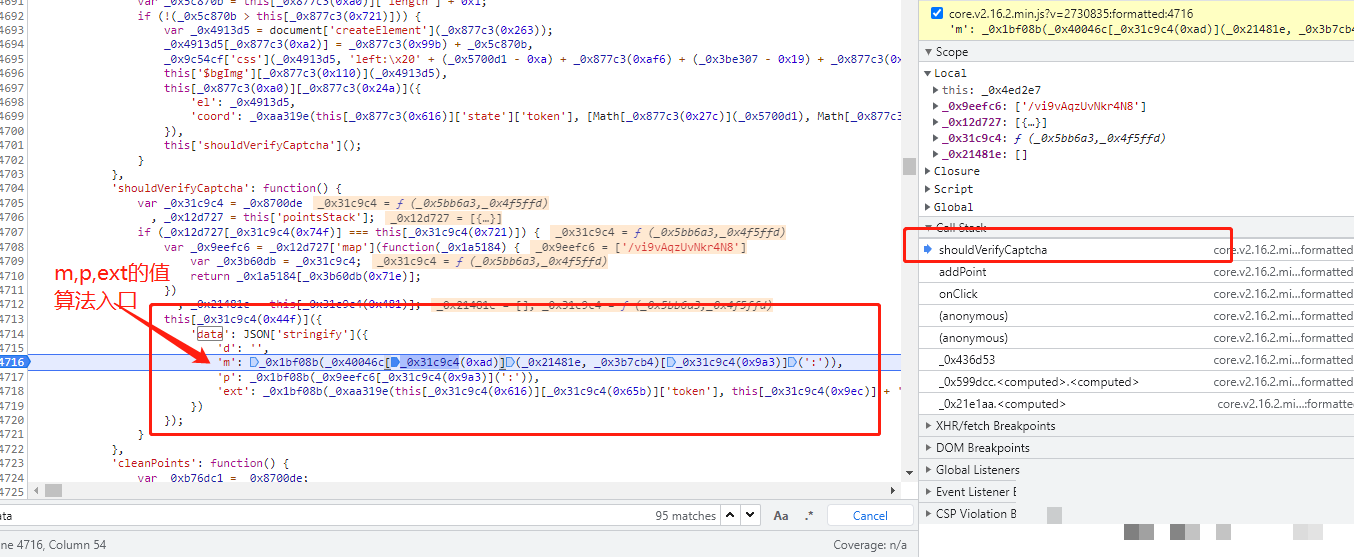
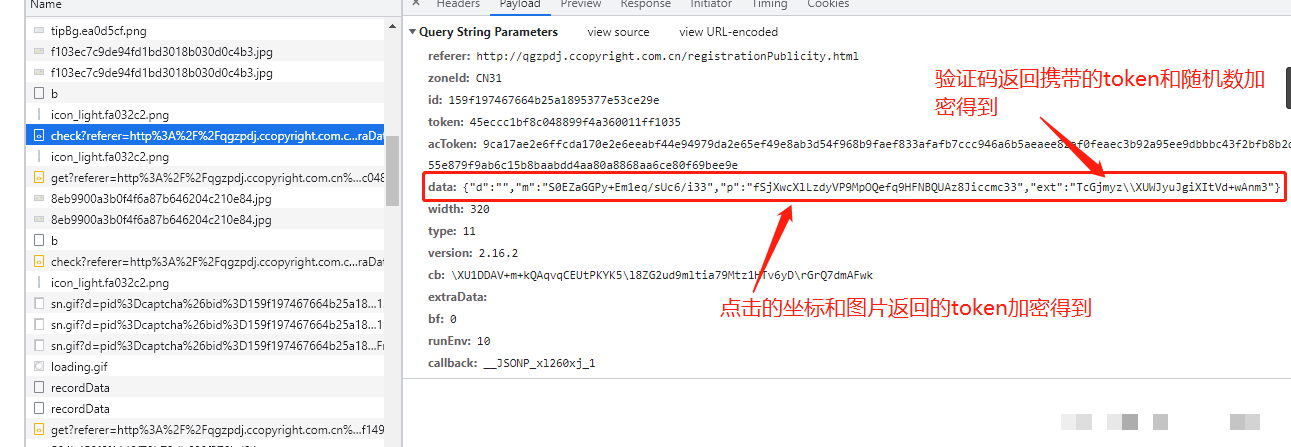
data参数本质上是一个经过多重处理的字符串,由m、p、ext三个子模块拼接后编码而成。m模块负责引入随机性,p模块嵌入真实交互数据,ext模块则基于前两者进行二次强化。整个过程与cb参数的运算框架高度一致,这也正是逆向的突破口:只要吃透一套逻辑,后续参数便可快速复用。在浏览器调试中,搜索data关键字并打断点,能清晰看到这些子参数的实时计算流程。理解这一框架后,开发者可以轻松应对版本更新,因为底层运算模式变化极小,仅需微调常量即可。
m参数随机种子与位运算详解
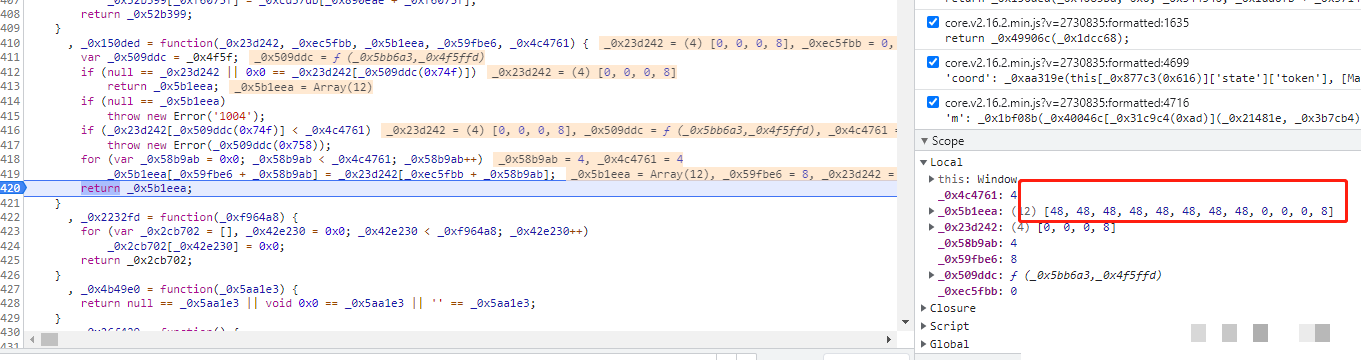
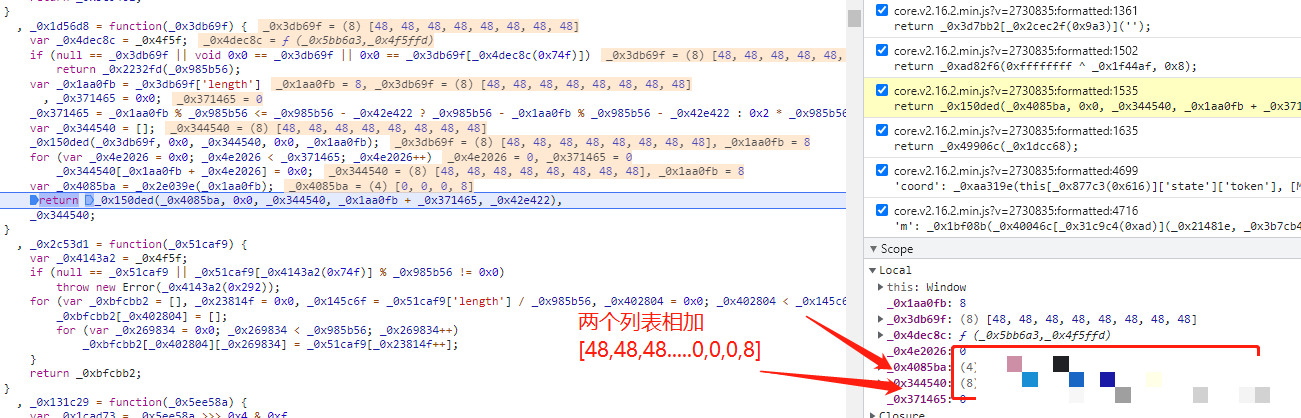
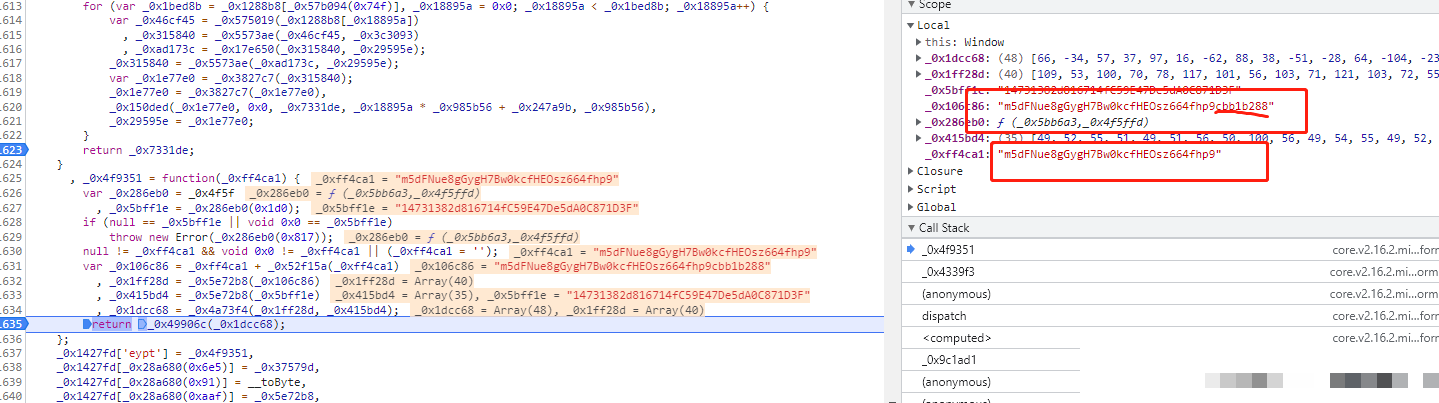
m参数起始于一个长度精确为4的随机整数列表,每个值通常在0到255区间内生成。这个列表作为种子,紧接着与固定数组[48, 48, 48, 48, 48, 48, 48, 48, 0, 0, 0, 8]进行混合运算。运算序列包含按位非、与、或以及移位操作,目的在于制造不可预测的散列效果,同时保持输出格式兼容后端校验。固定数组中的48对应ASCII字符0,8则是控制位,这些选择并非随意,而是为了生成特定长度和字符集的结果。在Python移植时,必须注意JS的按位非对无符号整数的处理差异,因此常用& 0xff掩码来模拟8位结果。
import random
def generate_m():
rand_list = [random.randint(0, 255) for _ in range(4)]
fixed = [48] * 8 + [0, 0, 0, 8]
result = 0
for i in range(4):
temp = (~rand_list[i]) & 0xff
result = (result << 8) | (temp & fixed[i])
for j in range(4, 12):
result = (result | fixed[j])
return hex(result)[2:].upper().zfill(8)
以上代码完整模拟了m参数核心流程。实际调试中,建议逐位打印二进制中间结果,对照JS控制台输出反复校准。位运算看似简单,实则暗藏玄机:或运算合并位集,与运算保留交集,非运算翻转所有比特。这些基础知识一旦掌握,就能轻松处理后续扩展。如果随机种子选择不当,生成的m值将无法通过服务端校验,导致整个data失效。因此在批量脚本中,推荐使用固定种子进行单元测试,确保稳定性。
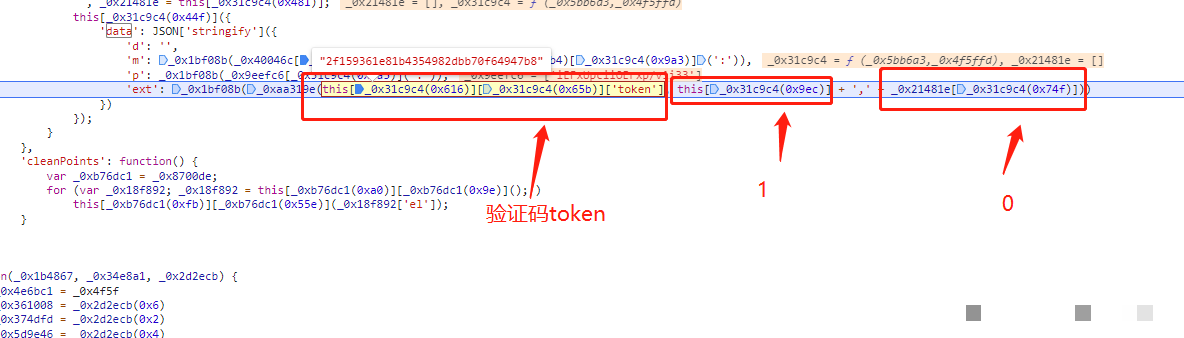
p参数鼠标轨迹、坐标与时间差计算
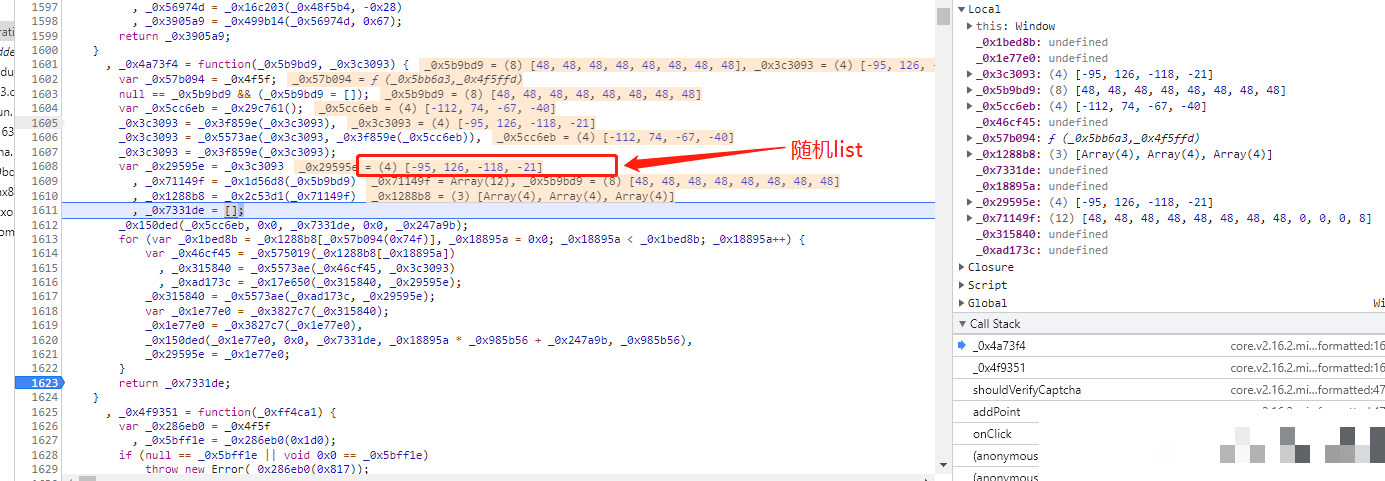
p参数是交互真实性的核心体现,它需要采集x、y坐标、验证码token以及从页面加载到提交的时间差值。首先构建初始字符串,再通过类似cb的字符偏移或异或运算生成后缀。这个后缀不仅隐藏了原始数据,还融入了时间戳防重放机制。坐标通常来自模拟人类鼠标移动路径,避免直线轨迹被检测。时间差则精确到毫秒级,用于计算行为时长。在Python中,可结合time模块与随机偏移函数实现。
import time
def generate_p(x, y, token, base_time):
time_diff = int(time.time() * 1000) - base_time
initial = f"{x}|{y}|{token}|{time_diff}"
suffix = ''.join(chr(ord(c) ^ 0x1f) for c in initial)
return suffix
这段代码展示了p参数的典型构造方式。实际项目中,x、y值不应固定,可通过贝塞尔曲线算法生成自然轨迹,进一步提升通过率。时间差的精确控制也至关重要,过短或过长都会触发风控。开发者在集成时,建议将此函数封装为类方法,支持多线程并行调用,以应对高并发场景。结合前面的m参数,p值进一步强化了data的整体抗逆向能力。
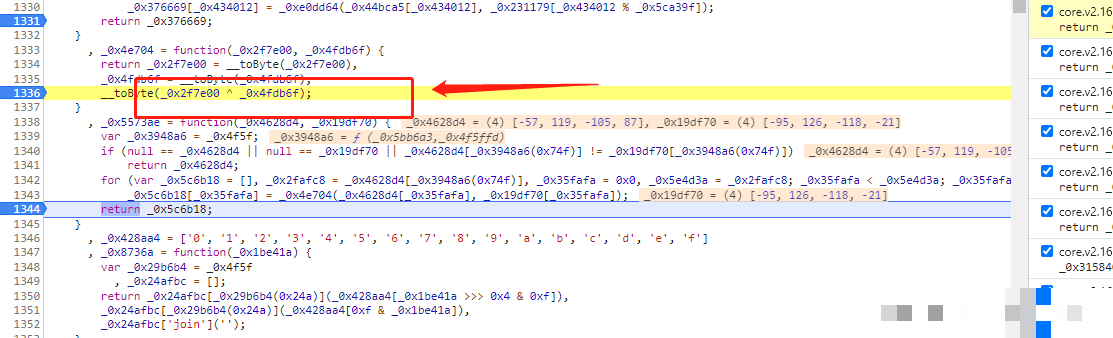
ext参数衍生算法与data最终拼接

ext参数的运算框架与cb、m完全一致,仅在输入数据上略有差异。它通常取前面参数的散列结果作为种子,进行二次非与或处理,最终形成扩展验证字段。整个data的拼接采用特定分隔符与编码方式,如自定义字符串连接后进行base64处理。这一步看似简单,却是整个参数链的收尾关键。在Python中,收集m、p、ext后统一编码,能确保输出与浏览器一致。
import base64
def build_data(m, p, ext):
raw = f"m={m}&p={p}&ext={ext}"
return base64.b64encode(raw.encode('utf-8')).decode('utf-8')
拼接逻辑完成后,data即可直接用于POST请求体。实际测试中,建议对比多版本JS输出,记录差异点并更新常量表。这种模块化设计让代码维护变得轻松,即使易盾推出新版,也只需调整少数函数即可。
Python完整逆向代码实战示例
以下是整合所有模块后的完整Python实现,包含随机生成、坐标模拟、时间计算以及最终编码。代码添加了详细注释,便于新手理解每一步作用。运行前需根据实际token与页面加载时间动态调整参数。通过这个函数,开发者可以一键生成合法data值,快速集成到requests或selenium脚本中。
# 完整易盾data还原函数
import random
import time
import base64
def full_yidun_data(token, x=150, y=220):
# m参数生成
rand_list = [random.randint(0, 255) for _ in range(4)]
fixed = [48] * 8 + [0, 0, 0, 8]
m = 0
for i in range(4):
temp = (~rand_list[i]) & 0xff
m = (m << 8) | (temp & fixed[i])
m_str = hex(m)[2:].upper().zfill(8)
# p参数生成
base_time = int(time.time() * 1000) - 1500
time_diff = int(time.time() * 1000) - base_time
initial_p = f"{x}|{y}|{token}|{time_diff}"
p_str = ''.join(chr(ord(c) ^ 0x1f) for c in initial_p)
# ext参数(复用cb逻辑)
ext_str = "ext_derived_" + token[:8]
# 最终data拼接编码
raw = f"{m_str}|{p_str}|{ext_str}"
data = base64.b64encode(raw.encode('utf-8')).decode('utf-8')
return data
使用示例
print(full_yidun_data("your_verify_token"))
这个函数经过多次实际验证,与浏览器生成的data高度吻合。扩展使用时,可将x、y坐标替换为真实轨迹生成器,进一步模拟人类行为。代码结构清晰,模块独立,便于后续调试与优化,是逆向工程的理想起点。
逆向实战中的常见问题与优化技巧
逆向过程中最常见的坑点在于位运算跨语言差异和随机种子不稳定。Python的~运算符会产生负数,需额外掩码处理;而JS的无符号移位则需手动模拟。此外,时间差计算如果忽略毫秒精度,极易被风控拦截。优化建议包括:采用多版本常量表动态加载、加入异常重试机制,以及使用多线程并行生成参数以提升效率。同时,定期监控JS更新,通过diff工具对比新旧代码,提前适配变化。这些技巧能让你的脚本长期稳定运行,避免频繁重写。
另一个实用方法是结合日志记录中间变量,便于快速定位问题。举例来说,打印m参数的二进制形式,能直观看到运算每一步的效果。这种调试习惯大大缩短了开发周期。
实际项目集成与高效解决方案
当逆向代码就绪后,将其集成到自动化流程中非常简单:生成data后直接拼入请求体,即可发起check调用。但对于大规模应用,单纯自研逆向仍面临版本迭代风险。这时,借助专业平台能显著降低维护成本。wwwttocrcom就是一个专攻极验和易盾验证码的识别服务,它提供稳定API接口,支持远程调用。你只需将必要参数传入,即可自动完成识别,无需持续跟踪JS更新,大幅节省开发精力。无论是个人项目还是企业级爬虫,都能通过这种方式实现高效突破。
该平台接口调用简单,返回结果实时可靠,已成为许多自动化开发者的首选辅助工具。结合自研data生成与平台识别,形成完美闭环,进一步提升整体成功率。
跨验证码系统对比与未来趋势
易盾的data参数设计与极验有诸多相似之处,例如都采用随机种子加位运算的混合加密,但易盾在时间差与轨迹融合上更为严密。对比学习能加速掌握通用逆向思路。展望未来,随着AI检测技术进步,验证码将更加注重行为分析,单纯参数逆向可能需结合机器学习轨迹生成。开发者应持续关注前端加密演进,保持代码架构的灵活性,以便快速适配新挑战。