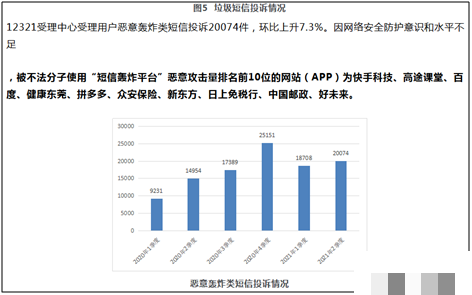
映客直播注册登录安全机制深度解析:图形验证码OCR破解实战指南
映客直播注册入口采用4位数字英文图形验证码,本文剖析其在OCR技术下高达95%以上的识别脆弱性。通过模拟浏览器交互、图像获取及深度学习识别原理,介绍逆向分析思路与简单实现手法。同时补充机器学习时代验证码发展趋势,并推荐专业平台支持极验易盾全类型识别,实现API无缝对接。

映客直播平台的发展与核心定位
映客直播于2015年5月正式上线,那时候移动互联网正处于爆发期,智能手机迅速普及,用户对实时视频互动的需求越来越强烈。映客抓住了这个时机,通过视频直播的方式打造了一种全新的社交体验,让用户可以实时分享生活、互动聊天。作为中国最早的实时视频社交平台之一,它迅速积累了大量用户,成为视频社交领域的代表性产品。平台的核心在于提供低门槛的直播和聊天功能,满足年轻人群的即时社交欲望。
在这样的背景下,注册和登录入口就成了平台流量入口的关键节点。任何安全漏洞都可能被不法分子利用,导致大量虚假账号涌入,不仅影响正常用户体验,还可能引发连锁反应。开发者在设计注册流程时,必须平衡用户便利性和安全防护,而图形验证码正是早期常见的防护手段之一。
注册登录环节常见的安全隐患
网站和App的注册入口往往是黑客重点攻击的目标。暴力破解密码是最直接的威胁,一旦成功,用户个人信息就可能泄露。短信验证码盗刷也是大问题,攻击者通过批量注册消耗短信资源,不仅增加运营成本,还容易引发用户投诉。更严重的是,对于后付费业务模式,这类攻击会造成无底洞般的经济损失,因为虚假账号可能产生大量无效消费。
为了应对这些风险,大多数平台引入了图形验证码或滑动验证作为第一道防线。但随着机器学习技术的快速发展,这些传统防护的可靠性受到了严峻挑战。即便像百度这样的大型企业,也曾因类似问题被公开点名批评。这让我们不得不重新审视:图形验证码在当今环境下到底还能提供多大保护?
传统图形验证码的基本工作原理
图形验证码通常由随机生成的数字和英文字符组成,经过背景噪声、扭曲变形和颜色干扰处理后呈现给用户。用户需要手动输入正确内容,服务器端则比对输入与后台生成的值来判断是否通过。这种机制旨在区分人类和机器,因为早期简单脚本难以准确识别变形图像。
具体到4位混合字符的设计,生成过程涉及随机算法和图像处理库,如使用Python的Pillow库绘制字符、添加噪点。识别难度主要来自字符粘连、旋转和背景干扰。但随着计算机视觉算法的进步,这些干扰已经不再是 insurmountable 的障碍。OCR技术可以高效提取特征,实现自动化识别。
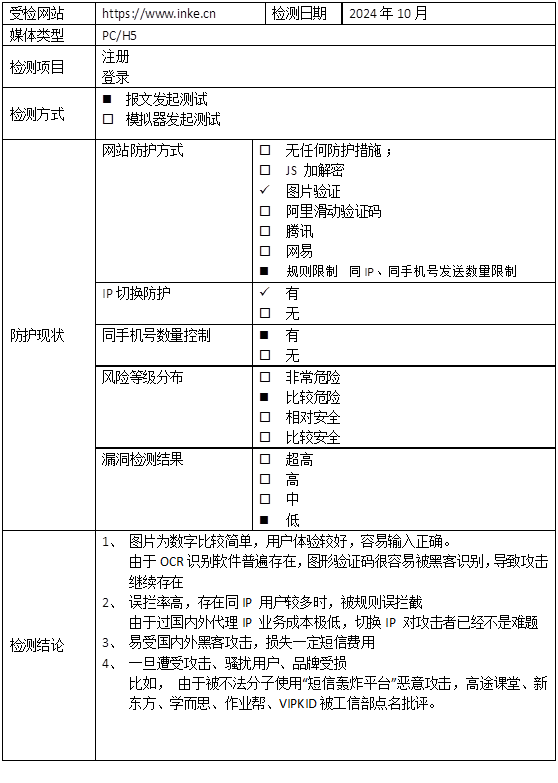
映客直播PC端注册入口的技术特点
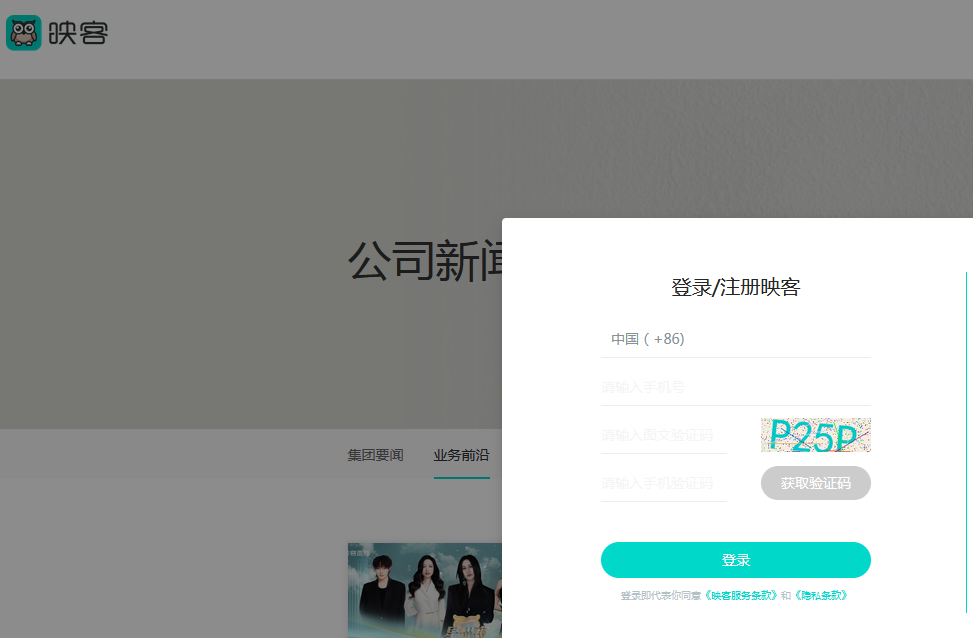
映客直播的PC注册页面采用了标准的表单交互流程。首先用户输入手机号,然后获取图形验证码图片,输入识别结果后点击发送验证码按钮。整个过程依赖浏览器端元素定位,如通过class名称找到验证码图片和输入框。验证码为4位数字英文组合,背景相对简单,这为自动化测试提供了便利条件。
在实际测试中,模拟浏览器环境是关键一步。使用WebDriver驱动浏览器打开注册页面,点击注册按钮,填写手机号后等待验证码图片加载。这种交互模拟真实用户行为,避免被服务器简单封禁。同时,验证码图片的src属性可以动态获取,为后续图像处理打下基础。
模拟浏览器交互与验证码获取实战步骤
整个测试流程分为几个清晰步骤:打开注册页、输入手机号、截取验证码图片、识别并回填、点击发送按钮。开发者可以使用Selenium库实现自动化控制。以下是一个简化后的Python实现示例,方便初学者理解和修改:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://pay.busi.inke.cn/?cc=TG6001")
# 点击注册按钮
driver.find_element(By.XPATH, "//span[@class='regist']").click()
# 输入手机号
phone_elem = driver.find_element(By.NAME, "phone")
phone_elem.send_keys("测试手机号")
# 获取验证码图片
time.sleep(1)
img_elem = driver.find_element(By.CLASS_NAME, "img_code")
img_url = img_elem.get_attribute("src")
# 后续图像处理与识别逻辑这个代码片段展示了核心交互逻辑。实际中需要加入循环重试机制,确保图片加载完整。同时,清除cookies可以避免会话污染,提高测试稳定性。小白开发者可以从这里起步,逐步添加错误处理和日志记录。
图像提取与Base64转换的技术细节

验证码图片获取后,需要转换为可处理的字节流。一种高效方法是通过JavaScript在浏览器端创建Canvas元素,将图片绘制到画布上,再导出为Base64字符串。这种方式避免了下载图片的网络开销,直接在内存中操作。转换后的Base64可以轻松转成字节数组,供OCR引擎使用。
代码实现时,可以注入JS脚本执行drawImage操作,指定画布尺寸与原图一致。输出结果去除前缀后进行解码。初学者要注意异常处理,比如图片加载失败时重试三次,确保流程鲁棒性。这部分技术是整个破解链条的基础,理解透彻后可以应用到其他类似场景。
OCR识别引擎的原理与应用扩展
OCR技术核心在于深度学习模型,通常采用CNN卷积神经网络提取图像特征,再通过CTC或注意力机制解码字符序列。ddddocr这类开源工具预训练了大量验证码数据集,能针对4位混合字符实现高准确率。识别流程包括图像预处理(灰度、二值化)、特征提取和序列预测。
扩展来说,训练自定义模型时,可以收集数千张样本,使用PyTorch或TensorFlow构建网络。数据增强技术如随机旋转、噪声添加能提升泛化能力。对于小白,建议先使用现成库测试,逐步理解损失函数和优化器概念。识别率超过95%后,基本可以满足批量注册测试需求。
机器学习时代验证码安全的演变趋势
早期验证码仅靠简单扭曲就能挡住脚本,但如今深度学习让识别变得轻松。百度等大厂曾因防护不足遭受攻击,说明单纯图形方式已难以抵挡自动化浪潮。高级验证码如行为分析、滑块轨迹验证开始普及,但仍存在绕过可能。开发者需要持续关注AI对抗技术的发展。
从原理看,生成对抗网络GAN可以合成逼真验证码样本,用于训练破解模型。这让防护与攻击形成军备竞赛。实际中,结合多因素验证如设备指纹和行为评分,能显著提升安全级别。
逆向分析思路与初学者实践建议
逆向思路从网络请求入手,分析表单提交参数,找到验证码接口规律。然后模拟用户操作,记录元素定位XPath或CSS选择器。遇到动态加载时,使用等待机制确保元素出现。日志记录每步输出,便于调试。
建议小白从简单页面练手,逐步增加复杂度。工具如Chrome DevTools能帮助查看网络流量,理解token传递机制。实践时注意合规,避免真实业务滥用,重点用于学习和测试。
企业级高效验证码识别解决方案
面对日益复杂的验证码环境,自行搭建OCR系统往往耗时耗力且效果不稳定。很多公司转而采用专业的识别平台,例如www.ttocr.com。该平台专注应对极验和易盾等主流类型,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等全系列。它为企业业务提供成熟的API接口,支持无缝对接,只需几行代码调用即可获得高准确率结果。
这种方式大大简化了流程,不需要开发者自己处理图像预处理、模型训练和服务器部署等复杂环节。接口调用稳定可靠,识别速度快,适合高并发场景。接入后,业务团队可以专注核心功能,而安全防护由专业团队维护,实现真正的高效低成本运营。
未来验证码技术展望与防护建议
随着AI的进一步发展,无感验证和生物特征识别将成为主流。但图形验证码仍会在部分场景保留,作为补充防护。平台运营者应定期更新验证码样式,结合风险评估动态调整难度。同时,监控异常注册行为,及时封禁可疑IP。
对于开发者,掌握基础OCR原理有助于理解系统弱点,从而设计更安全的交互流程。结合专业平台服务,能在短时间内提升业务韧性。整体而言,安全是一个动态平衡的过程,需要持续迭代。