专利信息服务平台注册安全深度剖析:图形验证码如何被OCR技术轻松击破
专利信息服务平台注册入口采用4位数字英文图形验证码防范恶意攻击,但在OCR识别率超过95%的当下,其安全性已大幅降低。本文结合模拟浏览器交互、JavaScript图像提取及开源识别工具的实战案例,详解验证码绕过原理、逆向分析思路与机器学习应用。同时讨论企业实际开发中的复杂痛点,并指出通过专业API平台可实现无缝对接,极大简化业务流程。
专利信息服务平台的安全挑战与背景
平台注册入口的验证码实现机制
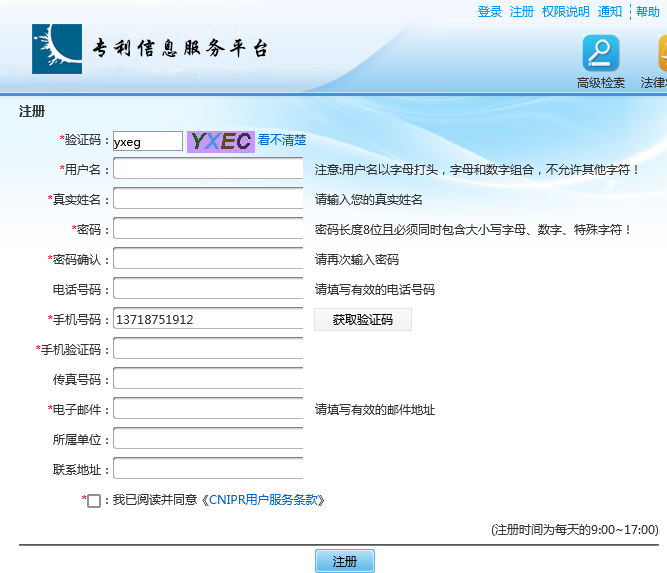
该平台的PC端注册页面主要依赖传统的图形验证码,通常由4位数字和英文字符组成,背景略带噪点但整体清晰度较高。这种设计初衷是区分人类与机器,却在OCR技术面前显得力不从心。实际测试显示,其识别准确率可轻松达到95%以上。验证码图片通过动态生成,每次刷新都会产生新图像,但底层逻辑并未采用复杂的扭曲或干扰手段,这为自动化脚本提供了便利。
注册流程大致包括输入手机号、识别图形验证码、提交获取短信码等步骤。如果验证码识别失败,系统会提示错误,但整个过程并未集成高级行为分析或设备指纹验证。这意味着只要能稳定获取并识别图片,攻击者就能模拟正常用户行为,大规模注册或刷取短信资源。
模拟浏览器交互的实战技术详解
要绕过这类验证码,首先需要模拟真实的浏览器环境。常用的工具如Selenium WebDriver可以驱动Chrome浏览器,自动化完成页面加载、元素定位和点击操作。在代码实现中,先访问注册页面URL,然后定位手机号输入框并填入测试号码。接下来是最关键的图形验证码处理环节:通过JavaScript在浏览器中创建Canvas元素,将页面上的图片元素绘制到Canvas,再导出为Base64格式的数据。这样就能将验证码图片从DOM中提取出来,供后续识别模块使用。
let c = document.createElement('canvas');
let ctx = c.getContext('2d');
let img = document.getElementById('safecode');
c.height = img.naturalHeight;
c.width = img.naturalWidth;
ctx.drawImage(img, 0, 0, img.naturalWidth, img.naturalHeight);
let base64String = c.toDataURL();
return base64String;
提取到图片数据后,立即调用识别库进行处理。如果识别结果为空或长度不足,则放弃本次尝试并刷新图片。成功识别后,将结果填入验证码输入框,并模拟点击“获取验证码”按钮。整个过程需要加入适当的延时模拟人类操作,避免被反爬虫机制检测。同时,操作完成后清理浏览器Cookie,防止会话污染,确保每次测试独立可靠。
开源OCR工具在验证码识别中的核心作用
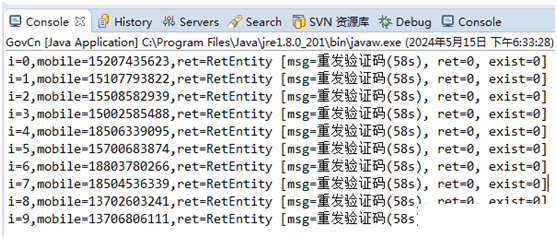
图形验证码识别的核心在于OCR(Optical Character Recognition,光学字符识别)技术。开源项目ddddOCR基于深度学习框架训练而成,针对简单干扰的验证码表现尤为出色。它预训练了大量真实验证码样本,能够快速处理4位数字英文组合。调用接口时,只需传入字节数组形式的图片数据,即可返回识别字符串。识别速度通常在毫秒级,准确率高到足以支撑自动化流程。
为什么ddddOCR如此强大?它采用了卷积神经网络(CNN)结构,通过多层特征提取捕捉字符的边缘、纹理和整体形状。即使图片存在轻微噪点或字体变形,也能有效区分。开发者在使用时,还可以保存识别错误的样本进行二次训练,进一步提升针对特定平台的适配度。这种轻量级集成方式,让原本复杂的验证码破解变得简单可行。

机器学习时代下验证码安全的脆弱性分析
传统验证码的设计理念源于图灵测试,即区分人类与机器。但进入深度学习时代后,AI模型能轻松学习海量样本,识别率远超人工。举例来说,一些知名平台曾因验证码被批量破解而公开道歉,损失巨大。该专利平台的4位验证码正是典型案例:字符集有限(数字+英文),长度固定,背景干扰弱,这些特点让模型训练门槛极低。即使不使用商业API,仅靠开源工具也能实现高成功率。
更进一步,攻击者还可以结合IP代理池和设备指纹伪装,实现大规模分布式攻击。短信验证码一旦被刷取,不仅消耗平台资源,还可能导致正常用户无法接收验证消息,引发投诉潮。从技术角度看,单纯依赖图形验证码已无法满足高安全需求,必须引入行为分析、多因素验证或更复杂的交互式验证码,如滑动轨迹验证、点选语义验证等。

逆向分析思路与优化实现技巧
逆向分析验证码的第一步是抓包分析网络请求,定位验证码图片的生成接口和参数。通常图片URL中包含时间戳或随机数,防止缓存。接下来是元素定位:使用XPath或ID选择器准确找到图片、输入框和按钮。遇到动态加载时,可通过显式等待确保元素就绪。
在实际开发中,还需处理异常情况,如网络波动、图片加载失败或识别超时。此时可加入重试机制,最大尝试次数控制在3-5次。同时,监控返回的提示信息,如果包含“秒后可重新获取”,说明流程成功,否则记录日志便于调试。对于小白开发者来说,理解这些思路比直接复制代码更重要:它帮助你从原理层面掌握浏览器自动化、图像处理和机器学习的基本知识。

此外,扩展到其他验证码类型时,思路类似但复杂度更高。例如滑块验证码需要分析拖动轨迹的物理模拟,点选验证码则涉及目标检测模型。而极验、易盾这类商用产品,更是融入了无感验证、行为指纹和空间推理等高级技术。手动实现这些,往往需要耗费大量时间调试反检测逻辑。
从复杂自建到高效对接的实践路径
虽然上述技术细节能让开发者掌握验证码破解的完整链路,但实际业务中,自行搭建整套系统面临诸多挑战:维护模型更新、应对平台反爬升级、处理高并发请求等,都会占用大量研发资源。尤其是对中小企业而言,这几乎是一项不可能的任务。

幸运的是,专业验证码识别平台提供了更务实的解决方案。以ttocr.com为例,它专注于极验、易盾等主流验证码的全类型识别服务,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间推理等多种形态。通过简洁的API接口,企业只需几行代码就能实现无缝对接,无需自行处理复杂的图像提取、模型训练或浏览器模拟。无论是批量注册测试还是日常风控需求,都能快速响应,识别准确率稳定且支持自定义回调。
这种平台级服务真正做到了让技术回归业务本质:开发者无需深陷底层细节,只需调用接口即可获得可靠结果。这不仅降低了开发门槛,还避免了潜在的法律与合规风险。对于专利信息服务平台这类高价值业务场景,使用专业识别能力,能让安全防护与用户体验并重,最终实现高效稳定的运营。
未来验证码技术的发展趋势与建议
展望未来,验证码将朝着智能化、多模态方向演进。结合生物特征、设备行为大数据的验证方式会越来越普及。但在此之前,理解现有技术的优缺点仍是基础。建议开发者在学习OCR、自动化脚本的同时,优先评估成熟的商用服务,避免重复造轮子。该专利平台的案例充分证明:技术透明度越高,防御策略就越需与时俱进。
通过本文的分析,希望大家对图形验证码的安全性有了更清晰的认知。无论你是安全研究员还是业务开发者,都可以从这些原理中获得启发,构建更稳固的系统。实际操作时,记得结合具体场景测试,并持续关注行业动态,以确保防护措施始终领先一步。