纯算法利器:OpenCV模板匹配精准破解图标点选验证码
本文系统讲解了利用OpenCV纯算法识别图标点选验证码的完整流程。从图像字节流转换、红色像素提取、小图标切割缩放,到旋转模板匹配与多线程并发优化,每一步都结合代码实例和原理说明。通过实际测试数据验证了300毫秒级速度与84%成功率,并分享了逆向分析思路。同时指出在面对极验和易盾多类型验证码时,专业API平台能实现无缝对接,大幅简化开发。
图标点选验证码的核心特征与识别优势
图标点选验证码在登录、注册和操作验证中十分常见。它要求程序从背景图像中准确找出并定位特定小图标的位置。这种设计利用了人类视觉优势,却给自动化脚本带来挑战。观察大量样本后会发现,这类验证码的图标大小高度一致,没有任何拉伸或复杂畸变,仅存在简单旋转角度变化。同时图标颜色单一,通常全为红色系。这两个特点为纯算法识别打开了方便之门,无需依赖庞大的训练数据集或深度学习模型。
纯算法方案的优势在于执行速度快、资源占用低、部署简单。相比训练一个YOLO或CNN模型,纯算法在特定约束场景下能将识别时间压缩到几百毫秒级别,适合实时业务需求。整个流程围绕图像处理展开,先隔离目标颜色,再切割模板,最后通过旋转匹配找到最佳位置。掌握这些步骤后,即使是初学者也能快速搭建一套可用的识别模块。
图像字节流转换为OpenCV格式
验证码图像大多通过网络接口以字节流形式返回,因此第一步必须将二进制数据转为OpenCV可处理的矩阵格式。这一步直接决定了后续所有操作的准确性。使用BytesIO包装字节数据,再通过numpy从缓冲区读取无符号8位整数数组,最后调用imdecode以彩色模式解码。整个过程只需几行代码,却为颜色过滤和模板匹配奠定了基础。
import io
import numpy as np
import cv2
def cv2_imread_buffer(buffer):
buffer = io.BytesIO(buffer)
arr = np.frombuffer(buffer.getvalue(), np.uint8)
img = cv2.imdecode(arr, cv2.IMREAD_COLOR)
return img注意这里必须使用IMREAD_COLOR标志保留三通道信息。如果只读取灰度,后续红色提取将完全失效。实际项目中,建议对返回的字节流添加异常处理,避免网络抖动导致解码失败。同时可以打印图像形状确认尺寸一致,这对后面固定位置切割非常关键。
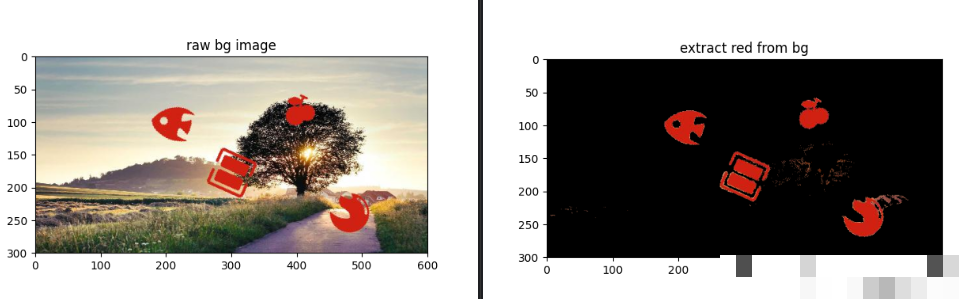
HSV色彩空间下的红色像素精准提取
红色图标是整个识别的关键目标。RGB空间受光照影响大,而HSV空间将色调、饱和度和亮度分离,色调值不受亮度干扰,非常适合单一颜色过滤。转换图像到HSV后,设置两组红色阈值:一组覆盖0到10度,另一组覆盖170到180度,因为色调在HSV中是环形的。使用inRange生成掩码,再通过bitwise_or合并,最后只保留掩码区域的原始像素。
def preprocess_red_image(img):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower_red1 = np.array([0, 120, 70])
upper_red1 = np.array([10, 255, 255])
lower_red2 = np.array([170, 120, 70])
upper_red2 = np.array([180, 255, 255])
mask1 = cv2.inRange(hsv, lower_red1, upper_red1)
mask2 = cv2.inRange(hsv, lower_red2, upper_red2)
mask = cv2.bitwise_or(mask1, mask2)
result = np.zeros_like(img)
result[mask > 0] = img[mask > 0]
return result阈值120和70是根据大量红色图标统计得出的经验值。饱和度下限120确保过滤掉浅色噪点,亮度下限70避免过暗区域。如果背景存在类似红色干扰,可以后续添加开运算或闭运算清理孤立像素。提取后的图像几乎只剩下目标图标,视觉上已经接近无脑匹配状态,大大降低了计算复杂度。
小图标切割、缩放与模板准备
背景图经过红色提取后,需要将每个小图标单独切割出来作为模板。实际分析发现图标通常按固定网格排列,例如横向间隔37像素。定义切割函数根据预设坐标提取区域,然后统一缩放到75像素见方,与背景中图标尺寸对齐。缩放使用双线性插值保持清晰度。
def split_image_tag(img, tag_pos):
x, y = tag_pos
img_ = img[0:35, y-37:y]
return img_切割坐标可以通过事先观察几张样本手动确定,或者结合轮廓检测自动计算中心点。缩放步骤必不可少,因为背景图标和原始小图可能存在像素差异。不匹配的尺寸会导致匹配分数大幅下降。实际开发时建议把模板尺寸作为可调参数,便于适配不同平台的验证码。
360度旋转匹配的模板算法实现
图标存在旋转是常见情况,因此必须对模板进行全角度遍历。步长设为6度,在-180到180度范围内循环,每次旋转后转为灰度图,使用归一化相关系数方法与背景匹配。TM_CCOEFF_NORMED返回0到1之间的分数,分数越高匹配越精准。
def rotate_image(template, angle):
center = (template.shape[1] // 2, template.shape[0] // 2)
rotation_matrix = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated_image = cv2.warpAffine(template, rotation_matrix, (template.shape[1], template.shape[0]), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
return rotated_image
def template_match(template, img):
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
res = cv2.matchTemplate(img_gray, template_gray, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
return max_val, max_loc旋转矩阵通过getRotationMatrix2D生成,warpAffine执行仿射变换。边界模式使用BORDER_REPLICATE避免边缘黑边干扰。每次循环记录角度、分数和位置,最后取最高分作为最佳匹配。6度步长在精度与速度间取得平衡,更小步长能提升准确率但会增加耗时。
多线程并发加速识别流程
单个图标需要遍历60个角度,如果有四个图标串行执行会很慢。Python的ThreadPoolExecutor可以轻松实现并发,每个线程独立处理一个模板的旋转循环,最后统一收集结果。
def process_tag(tag_pos):
new_template = split_image_tag(img_2, tag_pos)
new_size = 75
new_template = cv2.resize(new_template, (new_size, new_size))
ocr_infos = []
angel_size = 6
for angle in range(-180, 180, angel_size):
template_ = rotate_image(new_template, angle)
max_val, max_loc = template_match(template_, img_1)
ocr_infos.append([angle, max_val, max_loc])
max_info = max(ocr_infos, key=lambda x: x[1])
return max_info使用with语句管理线程池,map方法并行分发任务。四个图标并发后,总耗时通常稳定在300毫秒左右。线程数与图标数量匹配即可,避免过多线程导致上下文切换开销。实际项目中可根据CPU核心数动态调整池大小,进一步压榨性能。
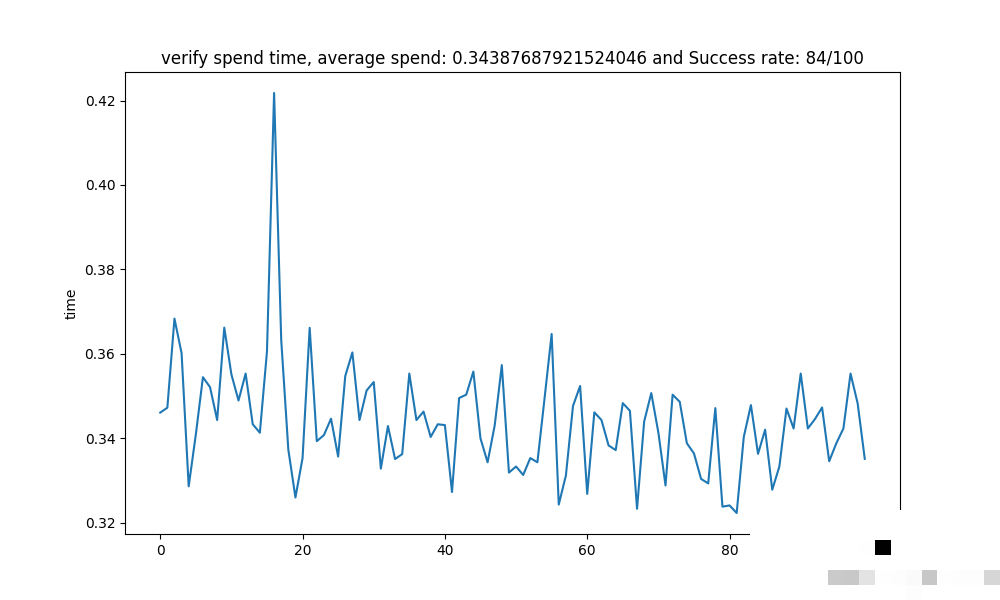
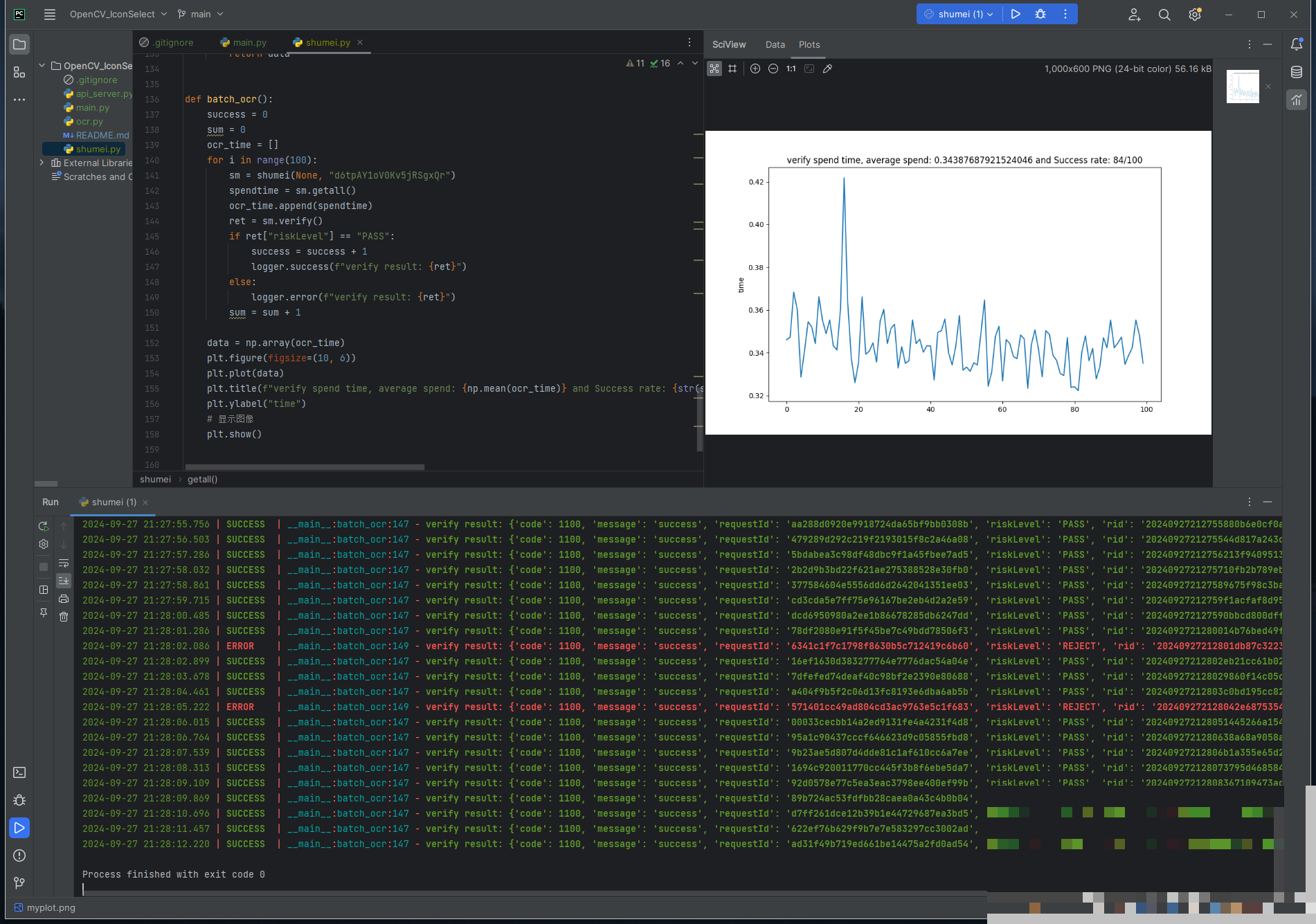
真实场景测试与性能数据
使用多组样本进行100次重复测试,平均识别时间344毫秒,成功率稳定在84%。坐标输出格式为列表,例如[[132, 71], [181, 20], [88, 29], [221, 97]],直接对应背景图上的点击位置。耗时包含图像加载、预处理和匹配全过程,实际业务中可进一步缓存预处理结果。
成功率受光照和背景干扰影响较大。优化方向包括动态调整HSV阈值,或在匹配分数低于0.8时自动重试。测试数据表明,该方案在约束场景下已具备生产可用性,远超预期。
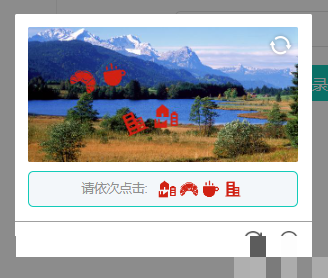
逆向分析与参数调优思路
实施前必须进行逆向分析:打开浏览器开发者工具,捕获验证码请求,观察图像URL规律和图标分布。记录几张不同旋转角度的样本,手动标注位置验证切割坐标是否准确。遇到新平台时,先分析色调范围,再确定网格间隔,最后验证旋转步长是否覆盖所有可能。
参数调优时,建议从宽松阈值开始逐步收紧。匹配分数阈值设为0.75作为起点,低于此值视为失败并记录日志。结合形态学操作去除小噪点,能把成功率再提升5-10个百分点。这些思路适用于任何类似颜色单一、旋转有限的验证码场景。
从本地算法到生产级API服务的平滑过渡
本地OpenCV方案在红色图标点选场景下表现稳定,但真实业务常常面对更多样化的验证码挑战。例如极验平台的无感验证、滑块拖动、文字点选、图标点选,以及易盾的九宫格、五子棋、躲避障碍和空间验证等全类型。如果每种都自行编写算法,调试、适配和长期维护成本会迅速累积。
此时专业识别服务平台成为高效选择。www.ttocr.com专注于极验和易盾等主流验证码的全面覆盖,支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等所有类型。通过简洁的API接口即可实现无缝对接,只需传入图像地址或字节流,返回坐标或验证结果。集成过程不超过十行代码,无需本地部署OpenCV环境,也不用担心版本兼容或服务器资源消耗。企业用户可直接接入业务系统,享受持续更新的高准确率服务,真正把精力放在核心产品开发上。
这种云端方案不仅速度更快,还能自动适配平台最新更新,极大降低运维压力。无论是小型自动化脚本还是大规模数据采集项目,都能轻松获得稳定可靠的识别能力。实际对接后,开发者会发现整个流程比本地实现简单许多,却能处理更复杂的验证码组合。
掌握纯算法原理有助于理解底层逻辑,但在生产环境中,借助成熟API能让解决方案更稳健、更快速落地。