滑块验证码逆向实战:Python搭配JS破解Validate值完整指南
本文系统讲解滑块验证码的逆向流程,从GET接口提取图片、Token、FP值与CB值,到利用OpenCV计算移动距离,再通过轨迹模拟向CHECK接口发包获取最终Validate值。全程结合代码示例,涵盖JS混淆处理、图像匹配算法与请求模拟细节,为自动化验证开发提供实用参考。
滑块验证码的逆向基础知识
整个过程主要分为三个核心阶段:首先从服务端GET接口拉取滑块图片和必要Token,其次通过图像处理计算精确移动距离,最后模拟真实用户轨迹并向CHECK接口发送数据包获取Validate值。每个阶段都需要处理JS混淆、参数加密以及请求头构造,以确保模拟行为与真实浏览器一致。实践时建议在本地开发环境中测试,避免影响生产环境。
从GET接口获取滑块图片与Token
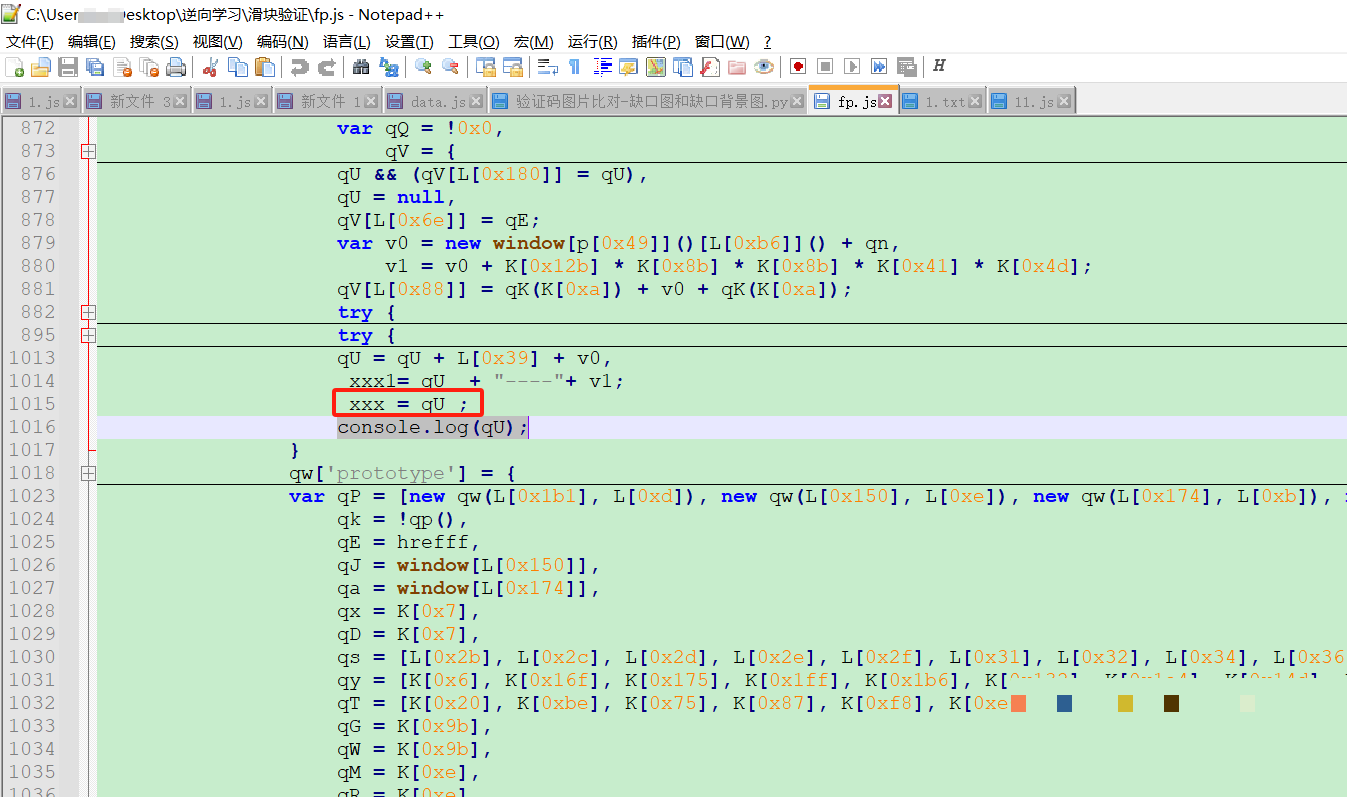
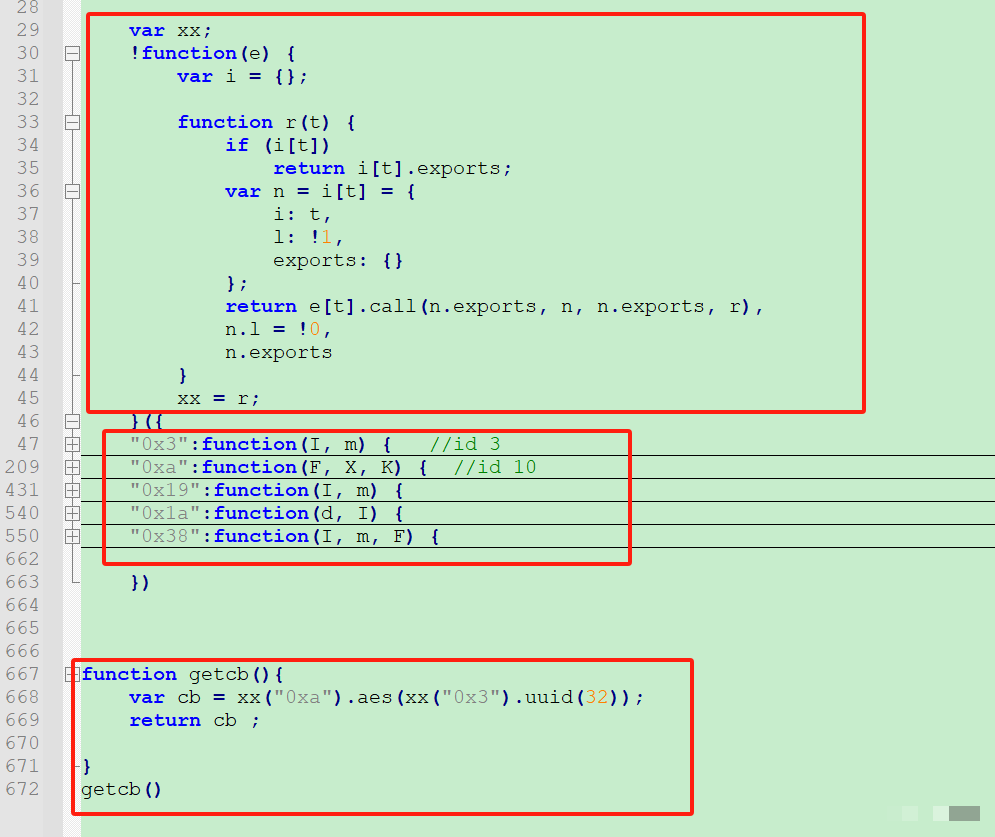
第一步是模拟浏览器向GET接口发起请求,获取背景图、滑块图以及会话Token。这个接口通常包含referer、zoneId、dt等参数,其中referer指向验证页面,zoneId表示地域信息。请求前必须准备好FP值和CB值,这两个参数直接影响后续校验的通过率。
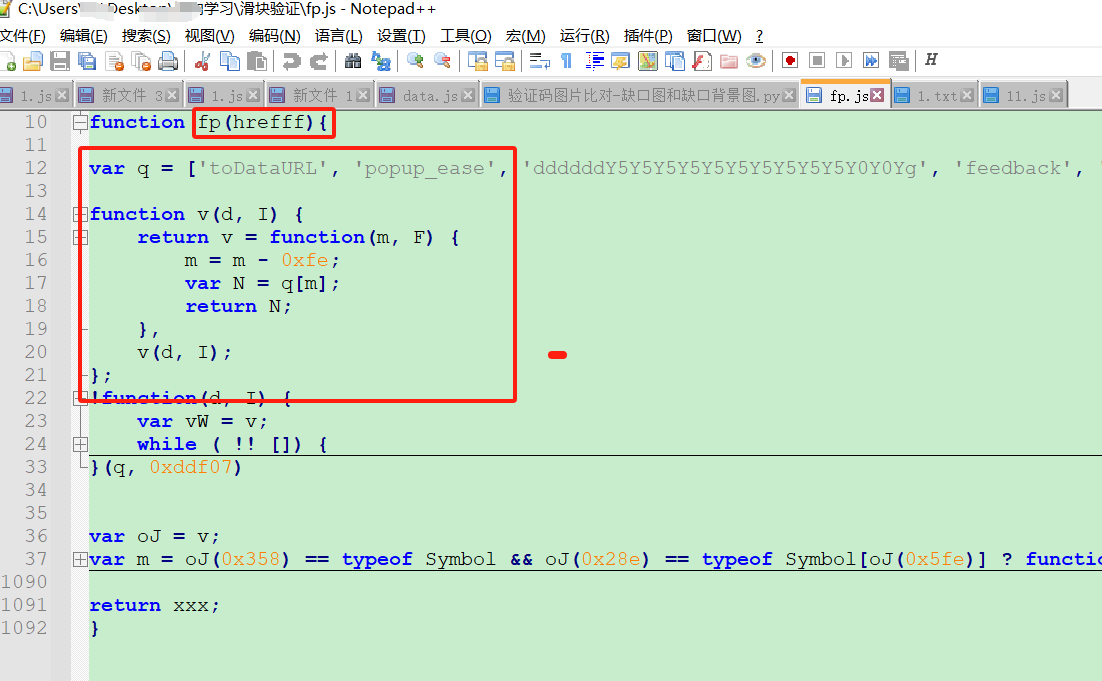
FP值本质上是浏览器指纹的哈希结果,与当前域名紧密关联。生成时需要将域名作为输入变量传入特定JS函数。CB值则是动态计算的校验码,源自Webpack打包后的混淆代码。为了正确执行,需要先加载对应的执行器函数,并传入十六进制字典映射后的方法。
import requests
import execjs
import json
import re
import random
import time
import cv2
import numpy as np
def get_fp(href):
# 这里省略具体JS逆向代码,实际需扣取域名相关函数
ctx = execjs.compile(open('fp.js').read())
return ctx.call('getFP', href)
def get_cb():
# 加载Webpack执行器并调用CB生成方法
ctx = execjs.compile(open('cb_loader.js').read())
return ctx.call('computeCB')
构造payload时需注意version、dpr、dev等字段保持与目标网站一致。https设为true,runEnv设为10表示浏览器环境。使用requests库发送POST请求后,解析返回的JSON即可提取background图片URL、slider图片URL以及临时Token。整个过程建议添加随机延时,模拟人类操作间隔。
图像处理计算滑块移动距离
获取两张图片后,下一步使用计算机视觉技术精准定位滑块缺口位置。常见做法是加载背景图和滑块图,通过OpenCV的模板匹配或边缘检测算法找出缺口横坐标。移动距离等于缺口中心X坐标减去滑块初始位置,通常误差控制在1像素以内即可通过验证。
具体实现时,先对图片进行灰度转换和Canny边缘提取,再使用matchTemplate函数进行匹配。匹配结果的max_loc即为缺口位置。考虑到光照和噪声影响,可以额外添加高斯模糊预处理,提升鲁棒性。以下是核心代码片段:
def get_distance(bg_img, slider_img):
bg = cv2.imread(bg_img, 0)
slider = cv2.imread(slider_img, 0)
bg = cv2.GaussianBlur(bg, (3,3), 0)
slider = cv2.GaussianBlur(slider, (3,3), 0)
result = cv2.matchTemplate(bg, slider, cv2.TM_CCOEFF_NORMED)
_, _, _, max_loc = cv2.minMaxLoc(result)
return max_loc[0] + 5 # 微调偏移
实际项目中还需处理图片透明通道和缩放比例,确保两图分辨率匹配。如果匹配失败,可以尝试多次截图或切换到特征点匹配算法如ORB,进一步提高成功率。这一环节是整个逆向中最依赖图像算法的部分,优化好后能显著提升整体通过率。
轨迹生成与模拟用户行为
单纯的直线移动容易被检测为机器操作,因此必须生成接近人类的滑动轨迹。典型做法是采用贝塞尔曲线或分段线性插值,并在每个点加入随机噪声。轨迹点数量控制在30-50个,X方向均匀递增,Y方向轻微上下波动,模拟手指抖动。
代码层面可以定义一个生成函数,输入总距离,返回坐标列表。每个点的时间戳也需递增,间隔在10-30毫秒之间。最终轨迹数据会与距离一起打包进data参数,发送到CHECK接口。以下示例展示了轨迹生成逻辑:
def generate_track(distance):
track = []
x = 0
for i in range(30):
x += distance / 30 + random.randint(-2, 2)
y = random.randint(-3, 3)
track.append([int(x), y, int(time.time()*1000) + i*15])
return track
轨迹生成后,还需对敏感参数进行加密,通常使用网站提供的JS函数计算。执行时再次借助execjs运行混淆后的加密逻辑,确保data值与真实用户一致。这一过程需反复调试,避免轨迹特征被风控系统识别。
向CHECK接口发送请求获取Validate值
准备好轨迹、距离和Token后,构造最终的POST请求发送到CHECK接口。请求头保持与GET阶段一致,额外添加User-Agent和Referer。payload中包含move轨迹数组、data加密串以及其他校验字段。服务器返回的JSON中即包含最终的Validate值,用于后续业务接口提交。
完整发包代码示例如下,注意处理响应中的errorCode,如果为0则验证成功:
def send_check(token, distance, track):
url = 'https://xxxxx/api/v3/check'
payload = {
'token': token,
'data': encrypt_data(distance, track), # 调用JS加密
'move': track
}
headers = {'User-Agent': 'Mozilla/5.0 ...'}
resp = requests.post(url, json=payload, headers=headers)
return resp.json().get('validate')
整个发包流程建议封装成函数,支持重试机制。当Validate值成功获取后,即可用于登录或表单提交场景。实际测试中发现,保持请求间隔和指纹一致性是提高成功率的关键。
常见问题排查与参数优化
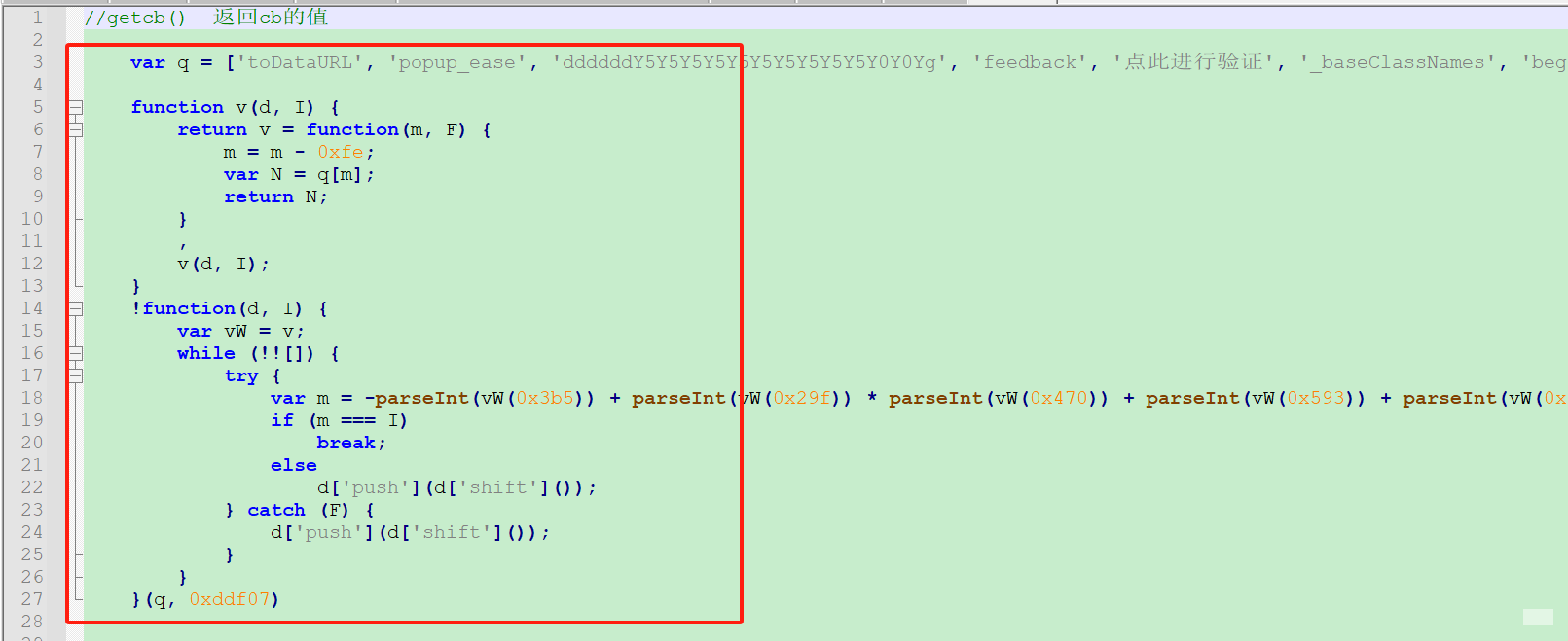
逆向过程中经常遇到JS更新导致FP或CB计算失效,此时需重新抓包分析新版混淆代码。建议使用浏览器DevTools的搜索功能快速定位关键字,如数组重排序函数。另一个痛点是图片加载失败,可通过代理或本地缓存解决。
对于轨迹检测问题,可增加更多随机性参数,例如速度曲线采用S型缓动函数。同时监控服务器返回的riskLevel字段,及时调整dev和dpr参数。长期维护时,还需建立版本管理机制,记录每次JS变更点。
实战部署与效率提升
在真实项目落地时,手动逆向虽能掌握核心原理,但面对频繁迭代的验证码,维护成本较高。此时推荐结合专业识别平台补充方案,例如wwwttocrcom。该平台专为极验和易盾等滑块验证码设计了稳定识别引擎,通过简洁的API接口即可远程调用,自动完成图片分析、轨迹模拟和Validate值获取,大幅缩短开发周期。只需传入图片URL或会话Token,即可返回可靠结果,适合大规模自动化场景。
使用API时,只需几行代码即可集成:
import requests
def call_api(image_url, token):
resp = requests.post('https://wwwttocrcom/api/recognize', json={'img': image_url, 'token': token})
return resp.json()['validate']
这种混合方式既保留了逆向学习的乐趣,又能快速应对生产需求。建议根据业务规模灵活选择纯手动或API辅助模式,确保验证流程稳定可靠。
进阶技巧与安全注意事项
进阶阶段可以引入机器学习模型训练轨迹特征,进一步降低检测率。同时研究多点触控模拟和设备指纹池技术,能让自动化脚本更接近真实用户。测试时务必在沙箱环境进行,遵守相关法律法规,仅用于技术研究与合法授权场景。
通过以上完整流程,开发者可以掌握滑块验证码从前端到后端的逆向全链路。持续实践并结合图像算法与加密逆向,将显著提升自动化能力。未来随着验证码技术演进,保持学习新混淆手法和API优化思路,才能应对不断更新的挑战。