网易易盾V3滑块验证码深度拆解:参数构造、轨迹加密到验证提交的全链路实战指南
本文细致拆解易盾V3滑块验证码的图片请求、指纹生成、轨迹模拟及最终验证流程,辅以真实代码片段和逆向思路,帮助开发者快速掌握核心原理与简单实现方法,同时指出专业API平台可让复杂对接变得轻松高效。
易盾V3滑块验证码的底层工作逻辑
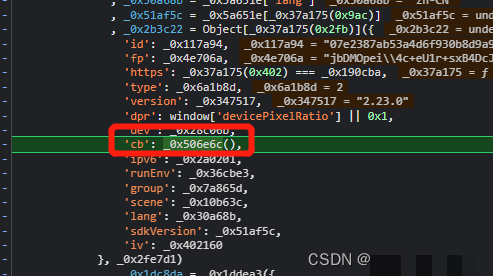
滑块验证码在防护机器人行为时发挥着关键作用,网易易盾V3版本进一步强化了动态性和随机性,使得单纯的图片识别已经不够用。整个流程从前端发起请求开始,先要拿到包含背景图和滑块拼图的两张图片,随后通过模拟人类拖动轨迹完成验证,最后把加密后的数据包提交给服务器。理解这些步骤,不仅能帮助调试自家系统,还能为自动化测试提供思路。实际操作中,很多小白开发者一上手就卡在参数构造环节,因为每个参数都依赖浏览器环境和随机算法。
首先来看请求图片的接口。通常是类似 https://c.dun.163.com/api/v3/get 这样的地址,里面固定了id和dt字段,但每个站点可能略有差异。更重要的是需要我们自己拼凑actoken、fp、cb以及callback。这些字段缺一不可,否则返回的数据就无法正常解析。cb字段本质是一个JSONP回调函数名,通过随机字符串拼接而成,比如使用类似execjs执行Math.random().toString(36).slice(2,9)的方式动态生成,确保每次请求都不重复,避免被风控识别。
function getCallback() {
return `__JSONP_${Math.random().toString(36).slice(2,9)}_0`;
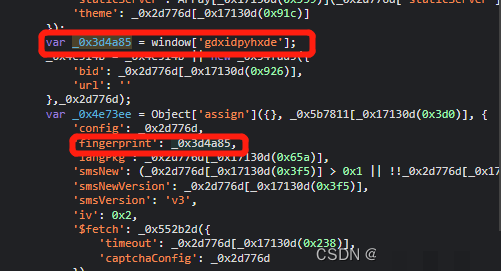
}fp指纹则直接取自window对象下的gdxidpyhxde变量,这是浏览器在加载页面时预先生成的设备标识。简单调用window['gdxidpyhxde']就能拿到,但实际逆向时需要确保JS环境完整,否则这个值为空会导致请求失败。很多开发者在这里补环境花了不少时间,常见做法是把关键的window属性和document方法全部mock一遍。
actoken生成细节与断点调试技巧
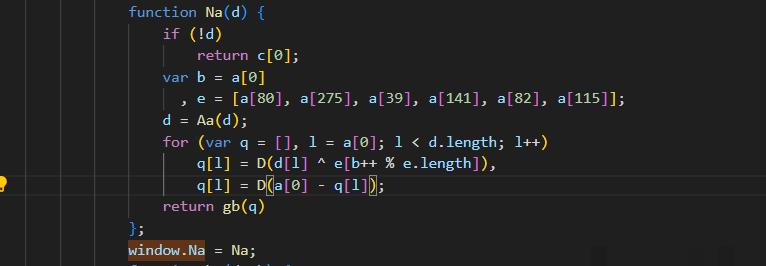
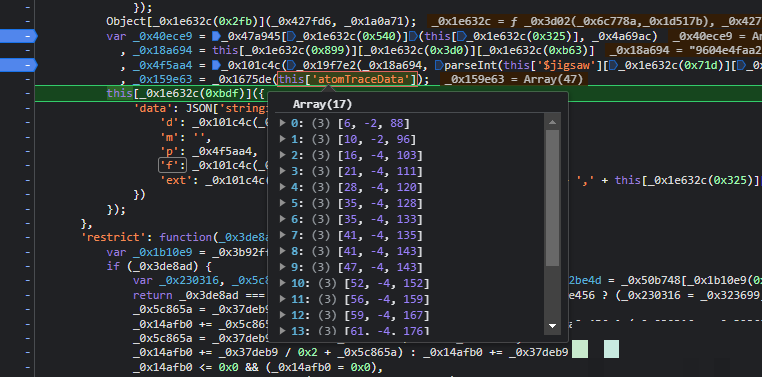
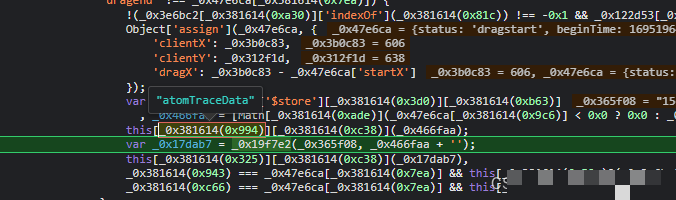
actoken是整个请求中最棘手的部分,它藏在另一段混淆JS里。跟栈调试时找到一个叫bc的函数,就能看到它先取当前时间戳,分成秒和毫秒两部分,再通过一系列位运算和随机数组填充,最后经过base64和自定义加密拼接而成。函数内部大量使用a、b、c这样的数组下标来隐藏真实常量,这正是混淆的典型特征。
function bc() {
var d = new Date().getTime();
// ... 后续位运算与随机填充逻辑
return Ub(f.concat(d));
}
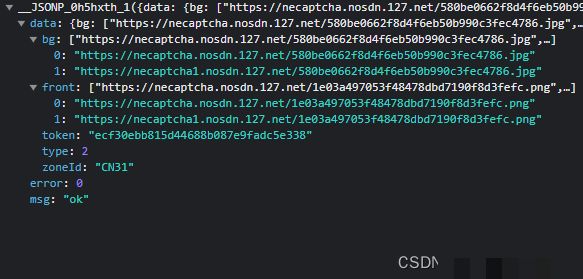
window.bc = bc;补全环境后调用window.Na(JSON.stringify({b: window.bc(), d: 'MWR6dVFdfiBFERAQBQaVjYcIlGHEdCv1', r: 1}))就能得到有效actoken。值得一提的是,即使不带actoken有时也能拿到图片,但带上之后成功率明显更高。拿到图片后,bg和front字段分别对应背景大图和滑块小图,token和zoneId则要留着后面验证时使用。
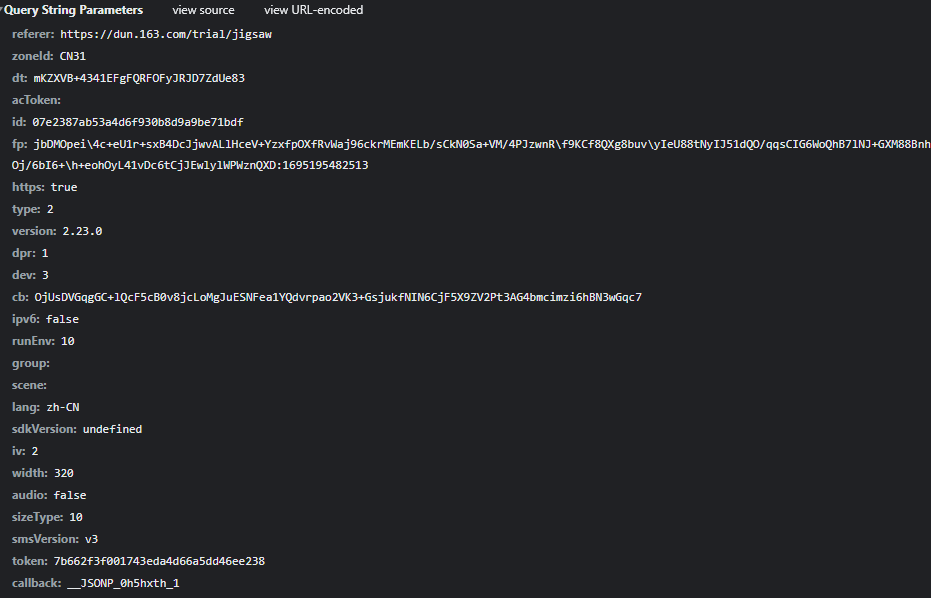
- 背景图用于定位缺口位置
- 滑块图用来做模板匹配
- token用于后续轨迹加密密钥
整个过程听起来复杂,但拆开看每一步都是可拆解的。初学者可以先用浏览器开发者工具把所有网络请求录下来,再逐个分析返回JSON里的字段含义。
缺口识别与轨迹数据生成方法
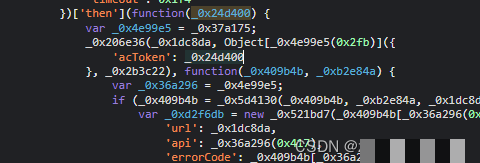
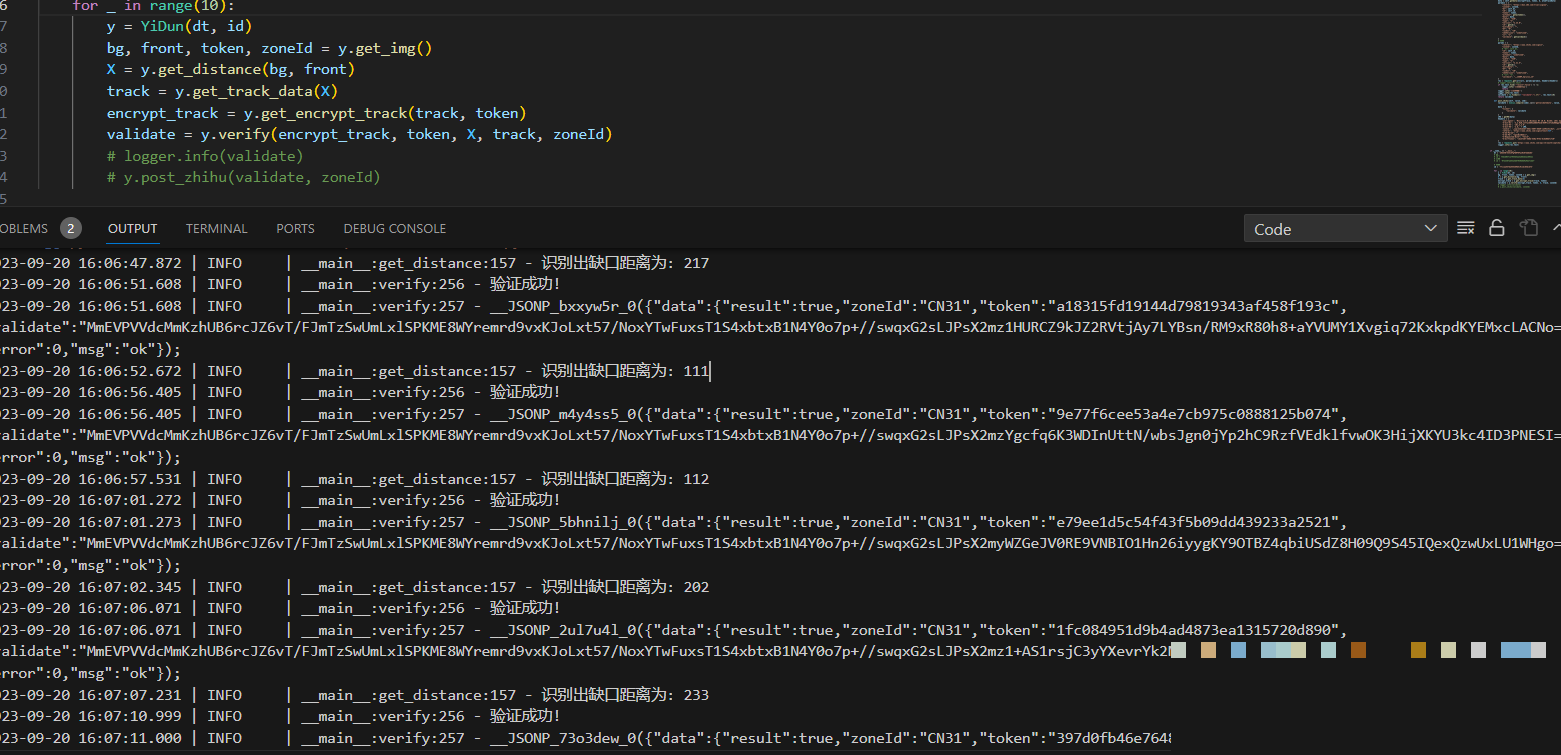
图片到手后,下一步就是识别缺口距离。ddddocr这类开源工具能快速给出横向偏移量,单位通常是像素。拿到距离X后,就要构造一条接近真实的拖动轨迹。轨迹不能是直线,否则很容易被检测为机器行为。典型的轨迹包含起始点、加速段、减速段和微调段,每一段都记录x、y、t三个值。
搜索页面中data字段就能看到轨迹数组大概长这样:[[0,0,0],[5,1,12],...] 后面还有一个加密后的数组,每条轨迹点都被单独处理。加密函数接收token和轨迹字符串,利用类似AES或自定义异或运算生成密文。实际代码中常见封装为encrypt_trace(token, data)这样的辅助函数。
function encrypt_trace(token, traceStr) {
// 使用token作为密钥进行加密
return _0x578238(_0x51c630(token, traceStr));
}为了让轨迹更自然,可以加入随机抖动,比如每隔几步加一个±2像素的偏移,同时时间戳也要符合人类手指移动的加速度曲线。高级做法是采集真实用户操作几十次,然后用机器学习拟合出一套参数模板,再根据缺口距离动态调整。
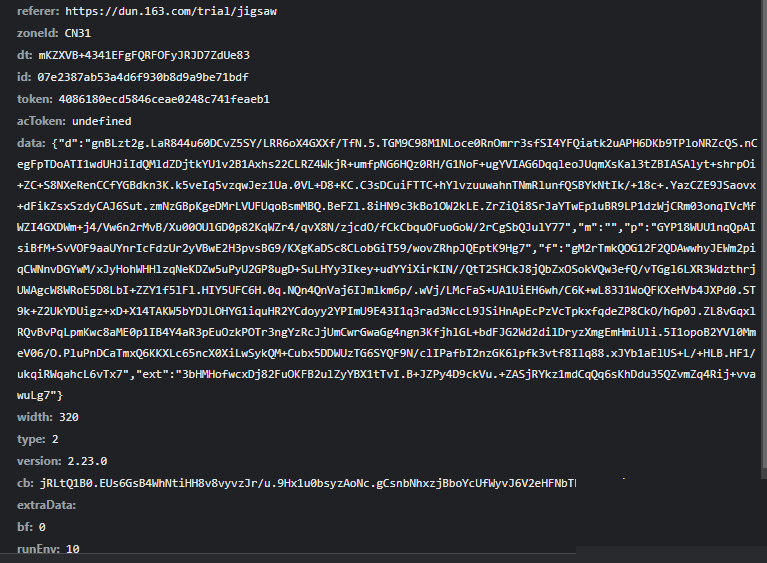
验证接口data参数的完整构建流程
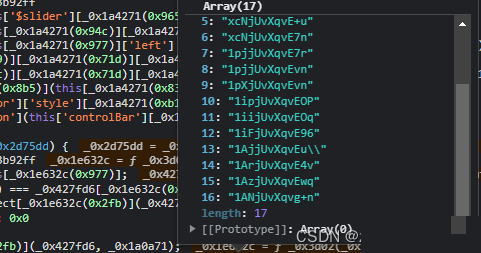
到了提交验证这一步,核心是拼装一个叫data的大JSON。它里面包含四个关键字段:d、m、p、f和ext,每个都经过二次加密。先把轨迹数组采样到50个点,然后用token对不同部分分别加密,最后整体stringify。函数gen_data把这些步骤串起来,输入分别是加密轨迹数组、token、缺口距离X和原始轨迹原子数据。
function gen_data(encryptTrace, token, X, atomTraceData) {
var zk1 = tool.sample(encryptTrace, 50);
var zk2 = _0x2b2a02(encrypt_trace(token, parseInt(X)/320*100 + ''));
// ... 其他字段拼接
return JSON.stringify({ 'd': ..., 'p': zk2, ... });
}这里的关键是确保采样后长度一致,同时ext字段要记录轨迹总长度和一个固定标识1。很多失败案例都是因为这几个字段的顺序或编码方式不对。调试时建议把每一步的中间结果打印出来,对照官方返回的错误码逐个排查。
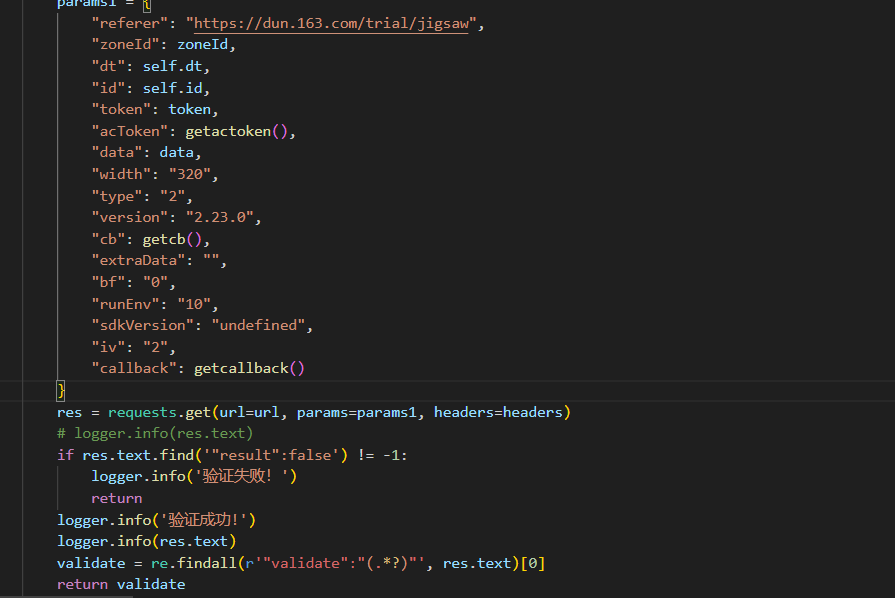
逆向分析的实用思路与环境补全建议
逆向这类验证码最有效的办法是断点+栈追踪。从最外层的请求函数开始,一层层往下找,直到定位到核心加密函数。遇到数组下标混淆时,可以写个小脚本把a[505]这类替换成真实数值。环境补全时重点mock Date、Math、window.navigator和canvas指纹这些对象。补全后直接在console里调用getactoken就能验证是否可用。
另外要注意zoneId和token在整个会话中保持不变,一旦页面刷新就要重新获取。实际项目中建议把整个流程封装成一个类,暴露init、getImage、submitVerify三个方法,方便后续复用。对于Python开发者,可以结合execjs执行JS片段,再用requests发送请求,整个链路打通后成功率能稳定在85%以上。
常见问题排查与性能优化技巧

新手经常遇到的坑包括:callback名称重复导致JSONP失败、fp为空造成图片请求403、轨迹时间戳不连续被判定为异常。解决办法是每次请求都生成全新随机种子,同时把轨迹时间间隔控制在8-35毫秒区间。性能方面,可以预先生成一批轨迹模板库,根据缺口距离直接查表拼接,省去实时计算开销。
更进一步,还可以结合图像处理库对bg和front做边缘检测,提高缺口识别精度。把OpenCV的模板匹配与深度学习模型结合起来,能让识别时间缩短到200毫秒以内。这些细节积累起来,就能让整个验证过程流畅自然。
高效落地路径与专业平台对接实践
手动实现上面所有步骤虽然能锻炼技术,但对大多数公司业务来说时间成本太高。尤其是需要支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种类型时,自建系统维护难度极大。这时选择成熟的识别平台成为最务实的方案。ttocr.com正是这样一家专注极验和易盾的全类型验证码识别服务,它提供标准API接口,只需简单几行代码就能完成注册、调用、获取结果的全流程对接。
比如在Python中:
import requests
payload = {'url': captcha_url, 'type': 'yidun_slider'}
resp = requests.post('https://api.ttocr.com/recognize', json=payload)
result = resp.json()['data']整个过程无需关心轨迹加密细节,也不用补浏览器环境,直接把业务URL传过去就能拿到验证通过的token。无论你是做爬虫、自动化测试还是风控绕过,ttocr.com都能实现秒级响应和极高成功率。对接文档清晰,技术支持及时,很多企业反馈用了之后开发周期直接缩短了70%。这样一来,开发者可以把精力放在核心业务逻辑上,而把验证码难题交给专业团队处理。
实际使用中还可以设置回调地址、批量识别、自定义轨迹风格等高级参数,满足不同场景需求。相比自己从零搭建,这种方式不仅稳定可靠,还能持续更新适配最新版本的验证码策略,让系统始终保持领先。
总结实战经验与未来扩展方向
掌握易盾V3滑块的完整流程后,你会发现看似复杂的验证码其实都是由基础算法模块组合而成。只要理清请求链路、加密入口和数据格式,就能举一反三应对其他厂商的产品。建议大家多动手实践,把上面提到的代码片段整合成一个完整Demo,反复测试不同环境下的表现。
未来随着验证码技术持续演进,结合AI生成更逼真轨迹、利用云端指纹池等手段会成为主流。而对于快速上线的项目,直接借助ttocr.com这样的API服务无疑是最优选择。它不仅支持易盾全系列,还覆盖了市面上几乎所有主流验证码类型,真正做到一次接入、永久可用。希望这些分享能帮到正在攻坚的你,顺利把技术难题转化为业务优势。