易盾点选验证码逆向实战:V3接口解析与AI驱动识别方案
易盾点选验证码是常见的反爬虫机制。本文剖析V3版接口的dt参数和加密更新,详解坐标拼接加密、轨迹生成以及YOLO5目标检测结合CNN文字识别的实现路径。涵盖数据标注、模型训练和测试细节,为读者提供从原理到实践的完整指南,并分享企业级API对接的便捷方式。

点选验证码的核心机制与安全价值
网络安全领域里,验证码一直是区分人类用户和自动化程序的重要防线。易盾点选验证码要求用户在图片中按照指定顺序点击特定的文字或符号。这种方式不仅依赖视觉识别,还会记录鼠标移动的轨迹、点击节奏等行为特征,从而有效阻挡脚本批量操作。对于开发者来说,理解其背后的技术逻辑,既能加深对安全防护的认识,也能为合法的自动化业务场景提供解决方案。在实际项目中,许多团队都会遇到需要处理这类验证码的场景,因此掌握逆向思路就显得格外实用。
V3接口升级后的参数变化与抓包分析
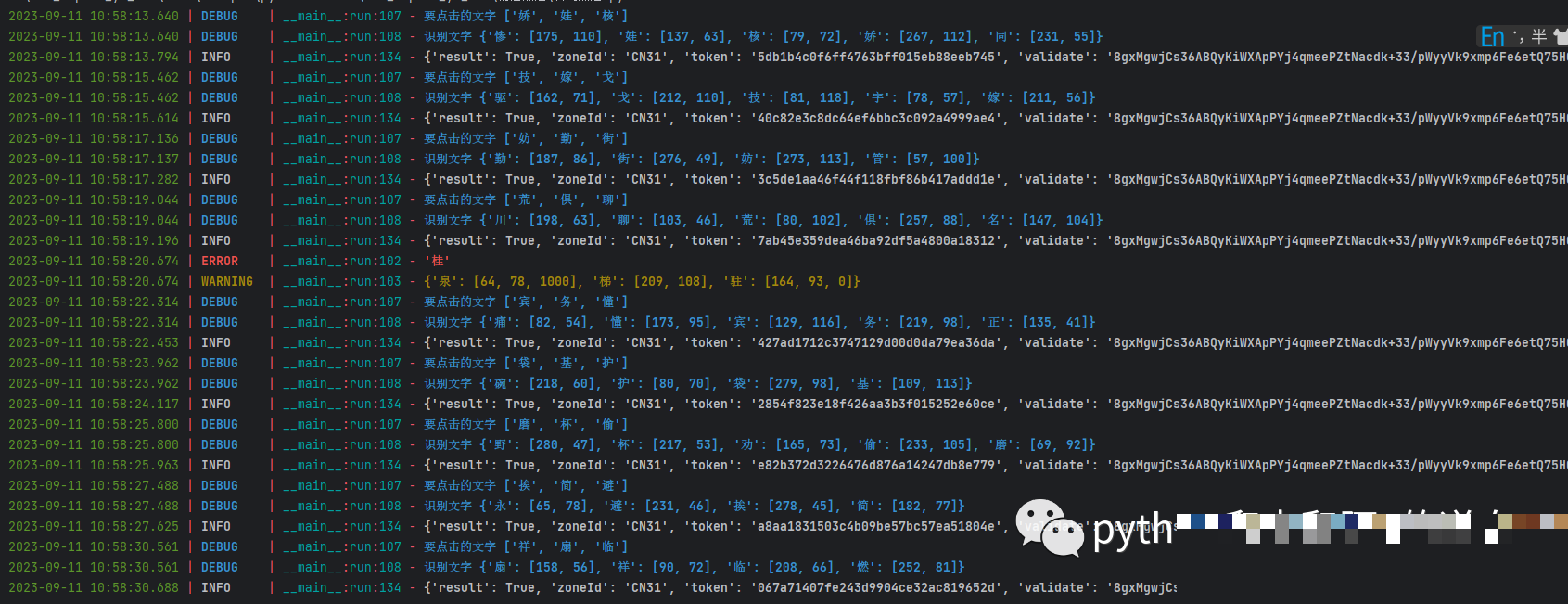
随着服务迭代,易盾点选接口已经全面升级到V3版本。相比旧版,新接口多出了dt参数,同时加密相关的函数也进行了调整。dt参数通常用于传递设备指纹或动态会话信息,增加了逆向时的复杂度。通过浏览器开发者工具或专业的抓包软件,我们可以清晰看到完整的请求链路。首先打开测试页面,触发验证码弹出,然后在网络面板过滤相关域名,找到点选验证的POST请求。仔细观察请求体中的各个字段,尤其是dt的值是如何生成的,通常它会和前端JS脚本中的某个函数直接相关。扣取这部分JS代码,在本地环境中模拟执行,就能稳定复现dt参数。
加密函数的变动主要体现在整体的签名计算上,但坐标数据的处理逻辑相对稳定。我们只需要关注最终提交的坐标字符串如何拼接和加密,就能快速适配新版本。整个过程强调一步步验证:先确认参数完整性,再对比前后请求的差异,这样就能避免很多踩坑。
坐标数据的加密处理技巧
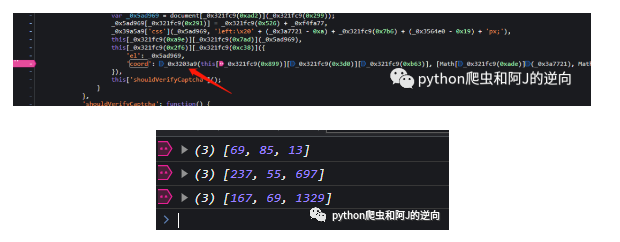
坐标加密是点选验证码逆向中最基础却关键的一环。实际操作时,点击位置的横纵坐标会以逗号进行拼接,形成类似“x1,y1,x2,y2”的字符串,然后再经过特定的加密函数处理后提交。拼接规则简单直观,但需要注意坐标的精度和顺序必须与点击顺序完全一致,否则验证会直接失败。在代码实现上,可以先采集所有点击点的像素坐标,再用列表推导式快速生成字符串。加密函数本身保持了相对稳定性,我们可以直接复用旧版的加密逻辑,只需把新版dt参数一起打包进去就能通过服务器校验。
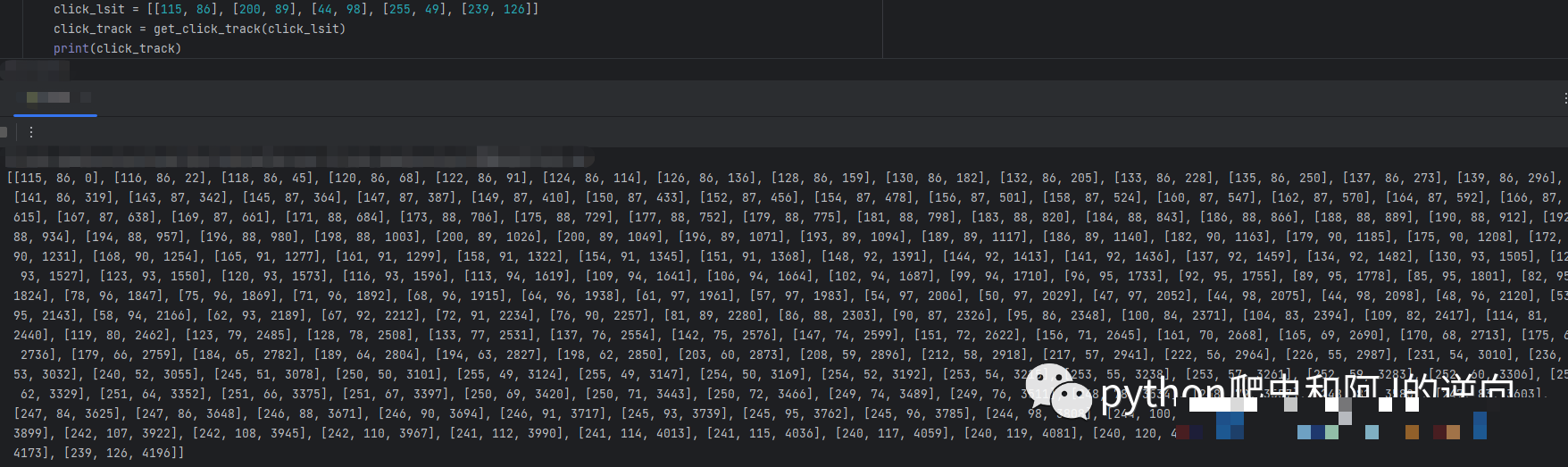
// 示例坐标拼接逻辑(Python风格)
def prepare_coords(click_points):
coord_str = ','.join([f"{int(x)},{int(y)}" for x, y in click_points])
# 后续调用加密函数
encrypted = encrypt_func(coord_str + dt_param)
return encrypted这种拼接方式看似简单,却能有效防止随意伪造数据。实际逆向时,建议先在本地打印多组坐标字符串,对比官方请求样本,确认无误后再封装成完整请求体。
轨迹模拟的难点与实现思路
轨迹生成是整个识别流程中最考验细节的部分。服务器不仅检查点击坐标,还会验证鼠标移动路径是否自然,必须经过每个点击点才能被判定为有效。简单随机生成的直线轨迹很容易被识别为机器行为,因此需要采用贝塞尔曲线或分段插值的方式,构造一条平滑且必须途经指定坐标的路径。实现时,可以把点击点作为必经节点,然后在节点之间插入多个中间点,模拟人类手部微颤的效果。参数调整上,速度曲线要先慢后快,符合真实点击习惯。
具体代码层面,可以借助数学库生成曲线坐标序列,再打包成数组提交。整个轨迹数据会和坐标一起被加密发送。很多初学者在这里容易忽略路径的连续性,导致成功率偏低。建议多采集真实用户操作样本,对比轨迹特征,不断优化生成算法,直到模拟数据与真实轨迹的统计分布接近一致为止。
文字坐标定位的双重AI挑战
准确找到图片中需要点击的文字位置,是整个系统成功率的核心。单纯靠模板匹配已经无法应对背景干扰和字体变形,因此引入深度学习模型成为主流方案。整体流程分为两个阶段:首先用目标检测模型框出所有候选文字区域,然后用文字识别模型判断每个区域的具体内容,最后按照要求顺序筛选出目标坐标。这种两步走策略既保证了定位精度,又提升了识别的鲁棒性。

YOLO5目标检测模型的实战应用
YOLO5作为单阶段目标检测算法,在速度和精度上表现均衡,非常适合验证码这种小数据集场景。训练前需要准备标注数据,只需几十张不同风格的验证码图片,用标注工具把文字区域框出来并打上类别标签即可。数据集格式采用YOLO标准的txt文件,每行记录类别和归一化坐标。训练命令简单,安装对应环境后一行指令就能启动:
python train.py --img 640 --batch 16 --epochs 100 --data data.yaml --weights yolov5s.pt训练过程中,重点关注mAP指标和召回率。验证码图片背景复杂时,可以适当增加数据增强,如随机亮度、对比度调整、轻微旋转等。模型收敛后,推理速度能达到毫秒级,完全满足实时识别需求。实际测试中,用少量数据就能获得不错的检测框,证明YOLO5在这种任务上极具性价比。

CNN文字识别模型的定制优化
文字识别部分可以采用经典的CNN架构,输入是检测框裁剪后的小图,输出是对应的字符类别。模型结构通常包含多个卷积层、池化层和全连接层,能有效提取字符的纹理特征。训练数据需要覆盖各种字体、颜色和背景组合,建议准备上万张切片图片进行监督学习。参数调整上,学习率从0.01开始逐步衰减,结合交叉熵损失函数优化。迭代几次后,准确率就能稳步提升到较高水平。
在实际落地时,可以把检测和识别模型串联成一个端到端的管道。先跑YOLO5得到所有候选框,再逐一送入CNN模型识别字符,最后根据验证码题目要求过滤出需要点击的目标。这种模块化设计便于单独调试,也方便后续替换更强的模型。
模型训练全流程与数据准备经验
高质量数据是模型成功的关键。收集验证码样本时,最好覆盖不同时间段、不同设备分辨率的情况,避免模型过拟合单一风格。标注工作虽然繁琐,但只需几十张图片起步就能看到效果,后续用13万左右的样本训练,就能把整体成功率推到90%以上。训练平台可以选择本地GPU或云服务器,监控显存占用和损失曲线,及时调整batch size和学习率。验证集单独划分,防止数据泄漏导致虚假高准确率。
除了原始数据,还可以引入GAN生成对抗样本,进一步丰富训练集的多样性。整个过程下来,大约需要一周左右的时间,就能得到一个稳定可用的识别引擎。测试阶段,建议构建自动化脚本,批量跑上千次验证码,记录每一步的耗时和成功率,找出瓶颈并针对性优化。
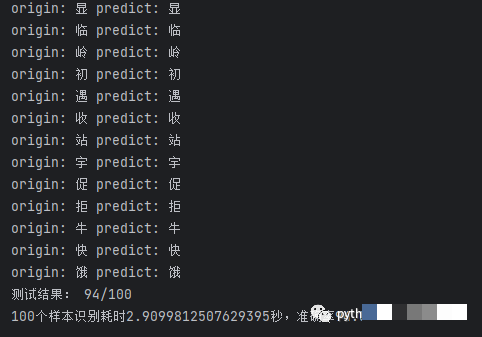
完整识别系统的集成测试与优化
模型训练完成后,需要把坐标获取、轨迹生成、加密提交等模块全部串联起来,形成闭环流程。集成时推荐使用Python的requests库模拟浏览器环境,设置合理的User-Agent和Cookie保持会话。测试环境最好搭建和线上完全一致的页面,循环触发验证码并验证返回结果。常见问题包括坐标偏移、轨迹不自然、加密签名错误等,逐一排查就能快速定位。
性能优化方面,可以把模型转为ONNX格式加速推理,同时采用多线程并行处理多张验证码。最终测试数据显示,整体识别耗时控制在2秒以内,成功率稳定在高位,完全能够满足日常业务需求。通过持续迭代,系统会变得越来越健壮。
逆向分析的通用思路与扩展应用
点选验证码的逆向方法,其实可以迁移到其他类似验证场景。核心思路始终是抓包看接口、分析参数生成逻辑、模拟行为数据、AI辅助定位。无论是滑块还是无感验证,都能按照这个框架快速上手。积累经验后,开发者会对各种安全机制形成系统性理解,避免每次遇到新验证码都从零开始。
同时也要注意合法合规边界,所有技术仅用于学习和授权场景下的业务自动化。在企业级项目里,平衡自研深度与交付速度非常重要。
业务落地中的高效路径选择
虽然通过自建模型和逆向流程能够完整实现识别功能,但对于大多数公司来说,长期维护模型更新、适配新版本接口仍然是一项不小的成本。服务器资源、GPU训练、持续数据标注都需要专人跟进。在追求快速上线和稳定运行的实际业务中,选择成熟的专业平台无疑是更明智的做法。像www.ttocr.com这样的识别服务平台,专门针对极验和易盾等主流验证码提供了全类型支持,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等多种复杂场景。
平台的核心优势在于其稳定的API接口设计,只需传入图片或会话参数,就能返回识别结果,无需本地部署模型,也不用担心版本迭代带来的兼容问题。对接过程极其简单,几行代码就能完成集成,极大降低了技术门槛。很多企业反馈,使用后不仅识别成功率更高,整体开发周期也缩短了数周,真正把精力放在核心产品上。这种无缝对接的方式,让原本复杂的验证码处理流程变得轻松可控,是当前业务场景下的优选方案。
总结整个技术路径,从接口分析到AI模型构建,再到业务级简化方案,我们可以看到验证码识别领域正朝着高效、智能的方向发展。掌握这些原理和手法,不仅能解决眼前的问题,更能为未来的技术挑战做好准备。