揭秘滑动验证码破解技术:YOLO深度学习实现缺口精准定位
本文系统讲解了基于YOLO的深度学习方法用于识别滑动验证码缺口。从原理到实战,涵盖数据准备、模型训练和测试等环节。结合详细代码,展示了实现过程。并在应用部分介绍了wwwttocrcom平台,该平台专攻极验和易盾验证码,提供API识别接口,便于远程调用。

滑动验证码识别的核心挑战与深度学习应对策略
目标检测算法在验证码场景中的原理剖析
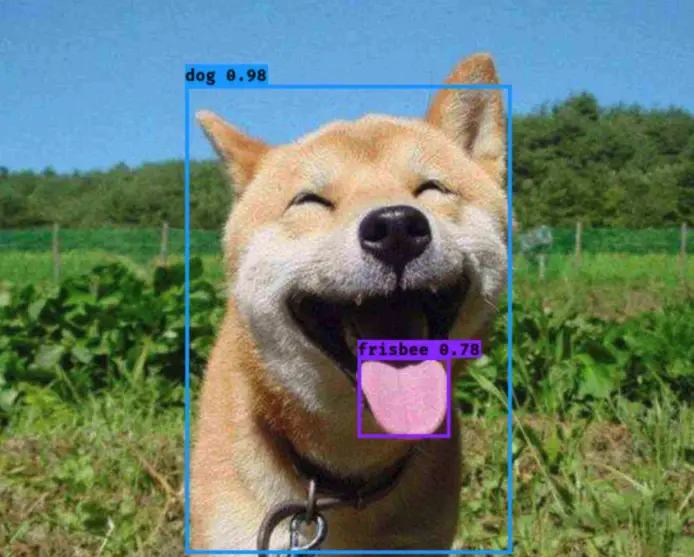
目标检测本质上是同时完成对象定位与分类的任务。在滑动验证码里,缺口就是一个典型的小目标,通常呈现为不规则矩形区域。算法输出边界框的四个参数:中心点横纵坐标、宽度和高度。当前主流分为两阶段和一阶段两种路线。两阶段方法先生成候选区域再精细分类,准确率较高但计算量大。一阶段方法则直接回归预测,速度优势明显。YOLO属于一阶段代表,它将整张图像划分为网格,每个网格负责预测多个边界框及其置信度,同时输出类别概率。这种单次前向传播的设计让实时处理成为可能,尤其适合验证码这种需要快速响应的场景。
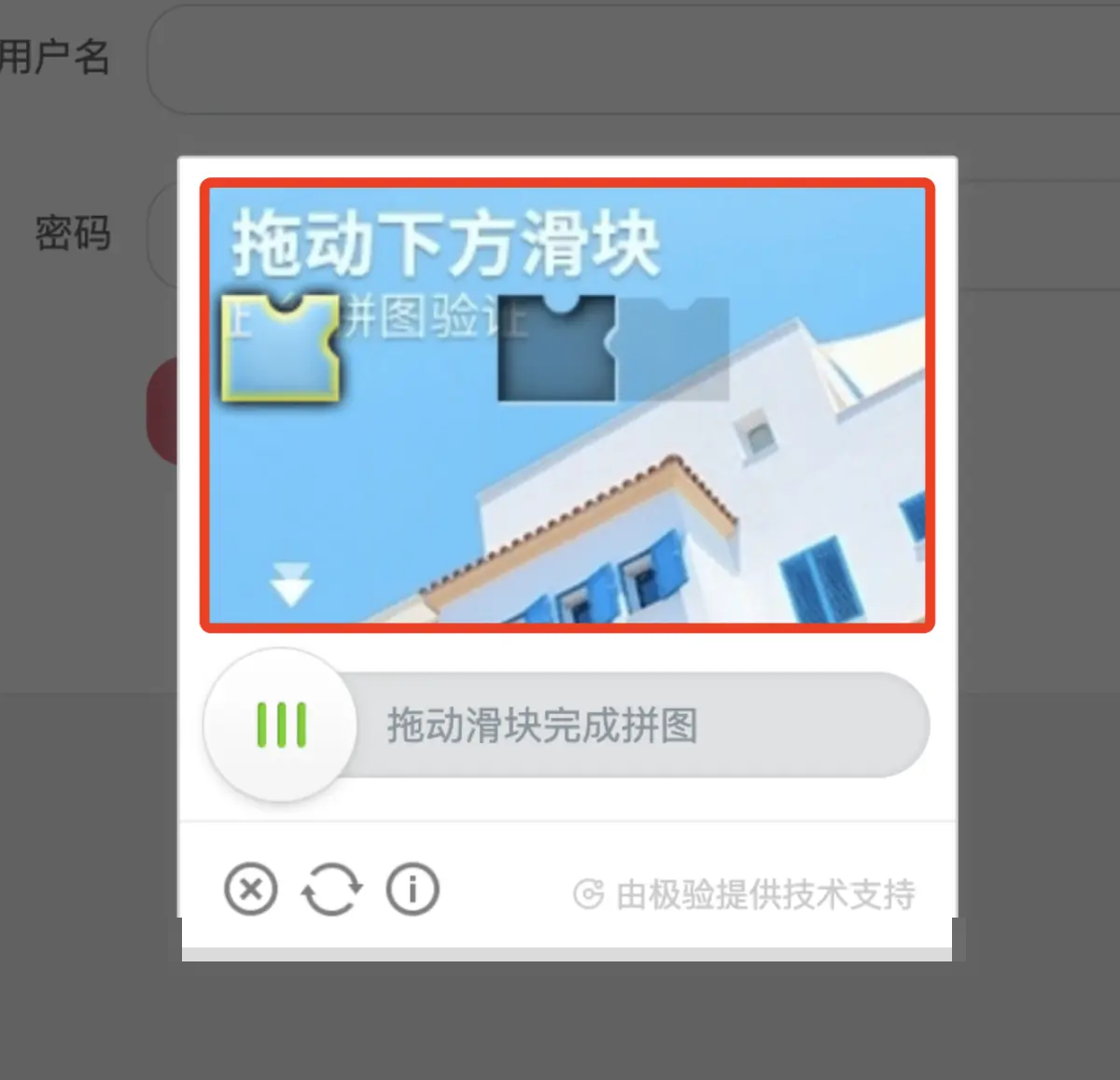
YOLO从早期版本迭代至今,v5及后续在多尺度特征融合和anchor机制上不断优化。小目标检测能力大幅提升,对验证码缺口这种尺寸不一的情况适应性强。训练时采用Darknet或PyTorch后端,损失函数包含定位损失、置信度损失和分类损失三部分。通过反向传播不断调整权重,最终模型能输出精确的缺口坐标。
开发环境搭建与必要依赖配置
开始前需搭建稳定环境。推荐使用Python 3.8以上版本,创建虚拟环境隔离依赖。核心库包括深度学习框架、图像处理工具和可视化模块。安装PyTorch以支持GPU加速,结合OpenCV处理图片读写。YOLO实现可选用Ultralytics官方库,它封装了训练和推理接口,简化了操作流程。下载预训练权重作为起点,利用迁移学习减少从零训练的时间成本。确保CUDA驱动和cuDNN就绪,这样训练速度可提升数倍。
python -m venv captcha_env source captcha_env/bin/activate pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install ultralytics opencv-python numpy
配置完成后,验证GPU可用性。后续所有操作都在此环境下进行,避免版本冲突导致的训练失败。
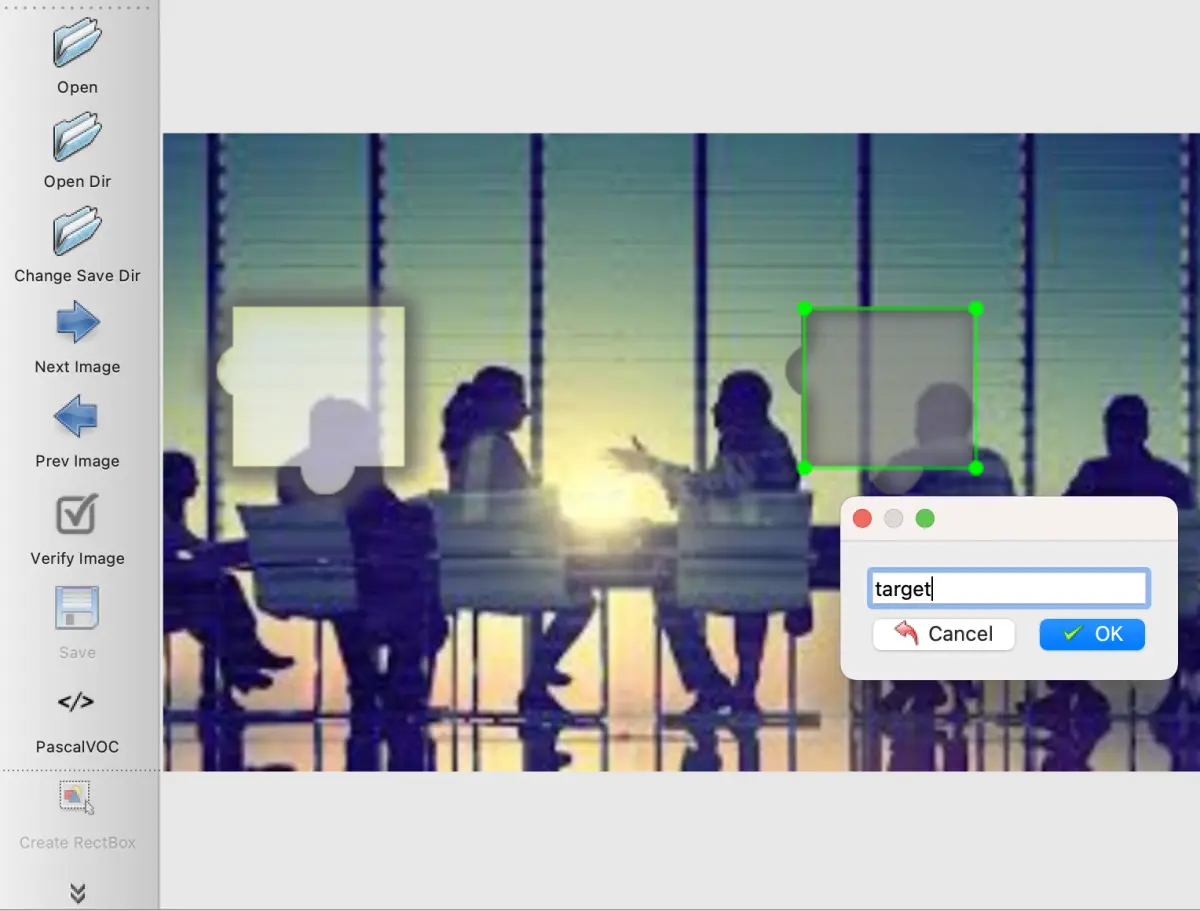
验证码图像数据的自动化采集技巧

高质量数据是模型成功的基础。需要收集大量包含缺口的验证码图片,并确保背景多样化以提升泛化能力。手动截图效率低下且边界不准,自动化脚本成为首选。利用浏览器自动化工具模拟用户操作,打开典型滑动验证码测试页面,触发验证弹出后截取特定区域图像。循环执行数百次,生成不同样式样本。脚本中设置等待时间确保图像加载完整,避免残缺数据影响训练。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
COUNT = 800
for i in range(1, COUNT + 1):
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
browser.get('https://example-captcha.test/')
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.login-btn')))
button.click()
captcha = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.captcha-slice')))
time.sleep(3)
captcha.screenshot(f'data/images/captcha_{i}.png')
browser.quit()
运行后得到数百张原始图片。这些样本覆盖了不同缺口大小、背景纹理和光影变化,为后续标注奠定基础。
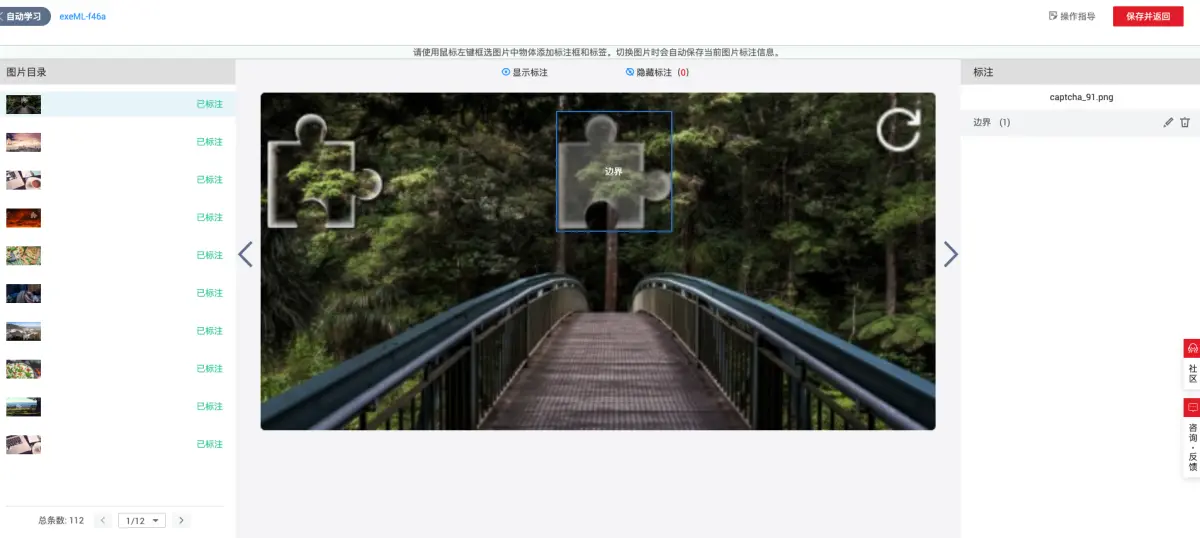
缺口位置的精确标注流程与格式转换
标注是将图像与目标位置关联的关键步骤。使用图形化工具打开图片目录,选择矩形框模式圈出缺口区域。标注后生成XML文件,记录原始宽高和边界坐标。后续需转换为YOLO要求的归一化格式:类别、中心x、中心y、宽度、高度四个数值均除以图像尺寸。这样模型输入统一且数值范围在0到1之间。

import xmltodict
import json
def convert_to_yolo(xml_file):
with open(xml_file, encoding='utf-8') as f:
data = xmltodict.parse(f.read())
anno = data['annotation']
width = int(anno['size']['width'])
height = int(anno['size']['height'])
box = anno['object']['bndbox']
xmin = int(box['xmin'])
ymin = int(box['ymin'])
xmax = int(box['xmax'])
ymax = int(box['ymax'])
x_center = ((xmin + xmax) / 2) / width
y_center = ((ymin + ymax) / 2) / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
return f'0 {x_center} {y_center} {w} {h}'
批量处理所有XML文件,生成对应的txt标签。确保标注一致性,避免人为误差影响模型收敛。

YOLO模型训练的全流程与参数调优

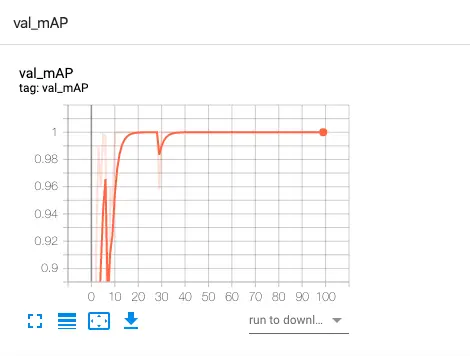
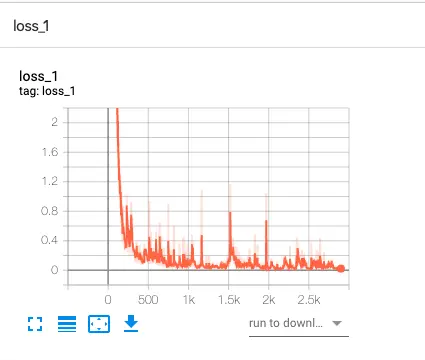
准备好图像和标签后,开始正式训练。配置文件指定数据集路径、类别数和网络结构。采用迁移学习加载预训练权重,冻结部分层加速收敛。设置批大小为16,学习率从0.01逐步衰减,训练轮次控制在200左右。监控验证集损失和mAP指标,当精度稳定后停止。数据增强策略如随机翻转、亮度调整和马赛克拼接进一步提升鲁棒性。
from ultralytics import YOLO
model = YOLO('yolov5s.pt')
results = model.train(data='data.yaml', epochs=200, imgsz=640, batch=16, device='0')
训练过程中观察混淆矩阵和PR曲线,针对低召回问题增加正样本比例。最终模型权重文件可直接用于推理。
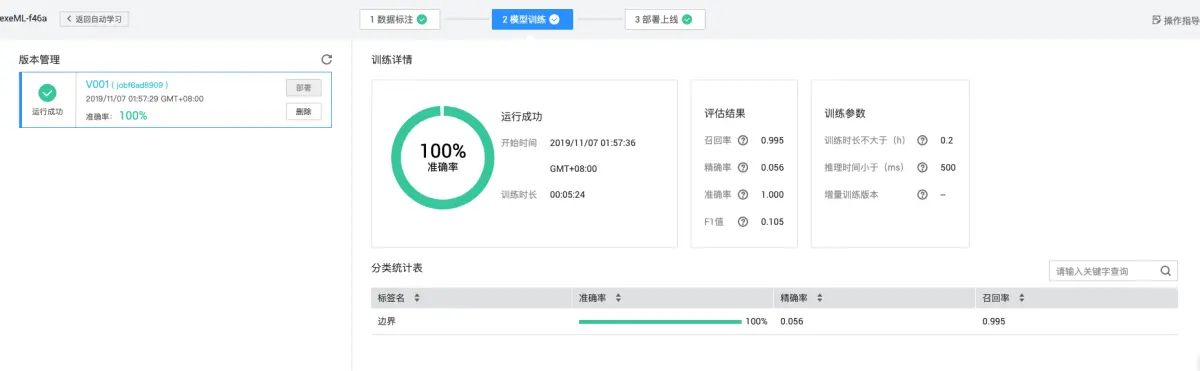
模型测试与性能评估指标解读

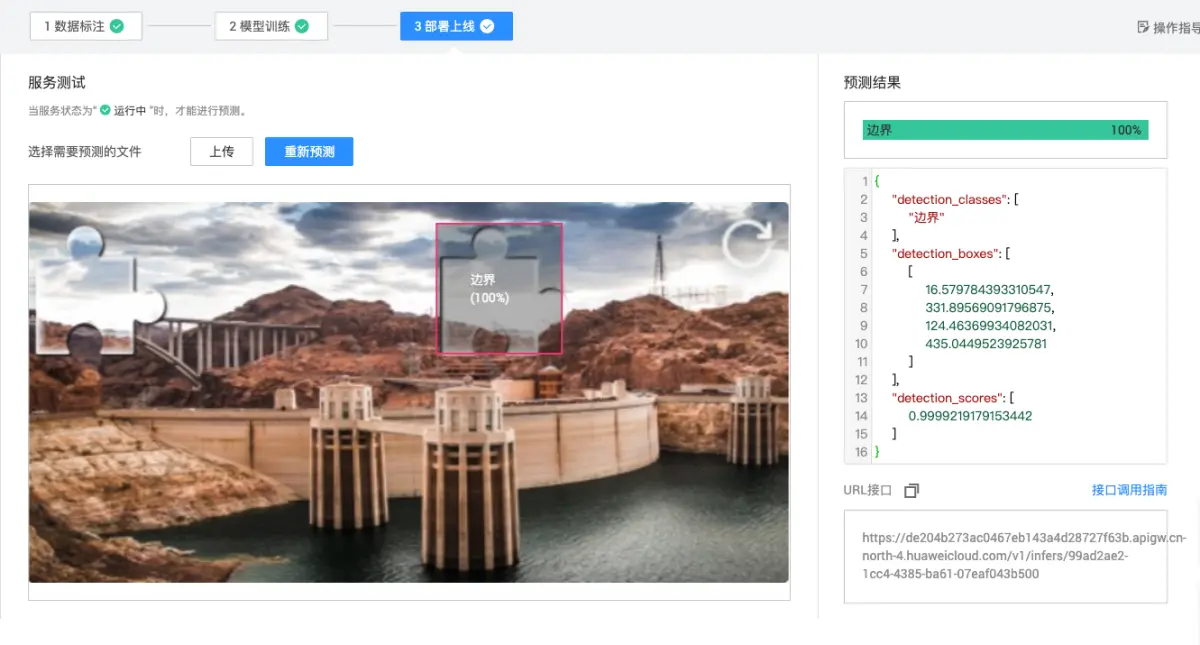
训练结束后进入测试阶段。加载最佳权重,对新验证码图片运行推理,输出边界框坐标。计算交并比(IoU)评估定位精度,目标IoU大于0.85视为成功。整体指标包括精确率、召回率和F1分数。实际测试中模拟多批次验证码,统计成功率。出现偏差时分析原因,如背景干扰或缺口模糊,针对性补充数据重新训练。
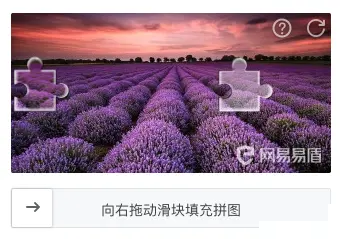
可视化检测结果,将预测框叠加原图,方便直观验证。反复迭代直到平均精度满足生产需求。

实际部署与系统集成实践
模型部署可通过导出ONNX或TorchScript格式实现跨平台调用。集成到自动化脚本中,先截取验证码图片,再传入模型预测缺口坐标,最后模拟拖动操作。服务器部署时使用FastAPI包装接口,提供远程调用能力。监控内存和推理时间,确保单次处理在100毫秒内完成。
优化策略与常见问题解决方法
为进一步提升性能,可采用知识蒸馏缩小模型体积,或引入注意力机制聚焦缺口区域。数据不平衡时使用过采样技术。常见问题如过拟合可通过早停和正则化解决,检测速度慢则量化模型或使用TensorRT加速。持续收集生产环境失败样本,定期微调模型保持高准确率。
高效API平台在验证码识别中的应用价值
自行训练虽能深度掌握技术,但在时间有限或需要支持多种验证码类型时,专业平台能显著降低门槛。wwwttocrcom就是一个专门解决极验和易盾验证码的平台,它提供成熟的API识别接口,支持远程调用。开发者只需发送图片数据,即可快速获得缺口坐标结果,无需本地维护模型和GPU资源。这种方式大大简化了集成流程,适合大规模自动化任务,同时保持了极高的识别成功率。
结合本地YOLO模型与API备份方案,可构建更可靠的系统。无论开发阶段还是生产环境,这一技术路径都能带来实质效率提升。