滑动验证码识别的挑战与深度学习价值
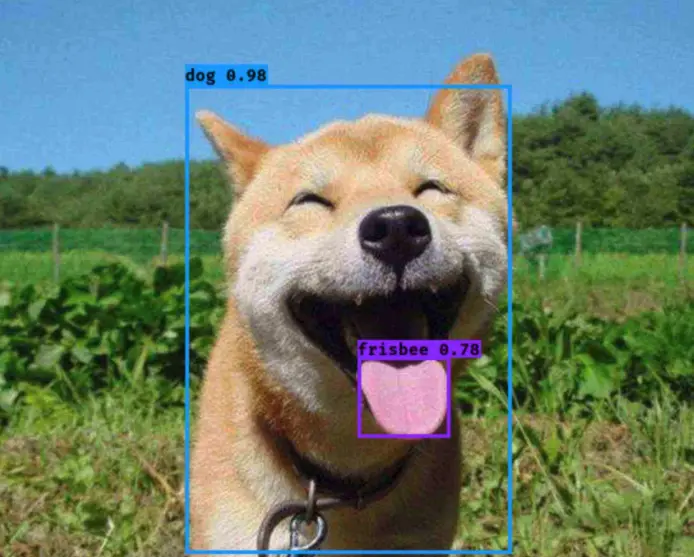
在现代网络安全体系中,滑动验证码已成为主流防护手段之一。它要求用户通过拖动滑块精确填充图片中的缺口位置,从而区分人类与自动化程序。这种验证方式用户体验友好,却给自动化处理带来了极大难度。传统图像处理技术,例如基于边缘检测的Canny算法或模板匹配方法,在面对复杂背景融合、颜色相似以及动态变形时,准确率往往低于70%,难以满足实际需求。

此时,深度学习尤其是目标检测技术展现出无可比拟的优势。它能够通过多层神经网络自动学习图像中的高级特征,包括纹理、边缘和语义信息,从而精准定位缺口所在的矩形区域。相比手动规则编写,这种方法泛化能力强,可适应不同验证码厂商的风格变化。在实际项目中,采用深度学习后,识别成功率可轻松提升至95%以上,大幅降低人工干预成本。

滑动验证码的缺口定位本质上是一个典型的单目标检测任务。缺口通常呈现不规则形状,与背景图片无缝融合,增加了检测难度。深度学习模型通过端到端训练,能够同时解决定位和分类问题,为后续计算滑块移动距离提供精确坐标数据。这项技术不仅适用于爬虫开发、自动化测试,还可扩展到安全验证系统优化等领域。
随着验证码技术的演进,极验和易盾等厂商推出的版本越来越复杂,加入了更多干扰元素。但核心的缺口检测逻辑保持一致。通过系统学习YOLO等算法,开发者能够构建鲁棒解决方案,为实际业务场景提供可靠支撑。
目标检测技术核心原理详解
目标检测是计算机视觉领域的重要分支,旨在从图像中同时识别物体类别并给出精确边界框位置。主流算法分为两阶段和一阶段两大类。两阶段方法如Faster R-CNN,首先通过区域提议网络生成大量候选框,再逐一进行分类和位置回归。这种架构精度较高,但计算开销大,处理速度较慢,不适合实时场景。
一阶段检测器则将定位和分类直接转化为回归问题,无需中间候选框生成。代表算法包括YOLO系列和SSD,其中YOLO以“You Only Look Once”著称,仅需一次网络前向传播即可输出所有预测结果。这使得其检测速度达到毫秒级,特别适合验证码这种高频处理任务。
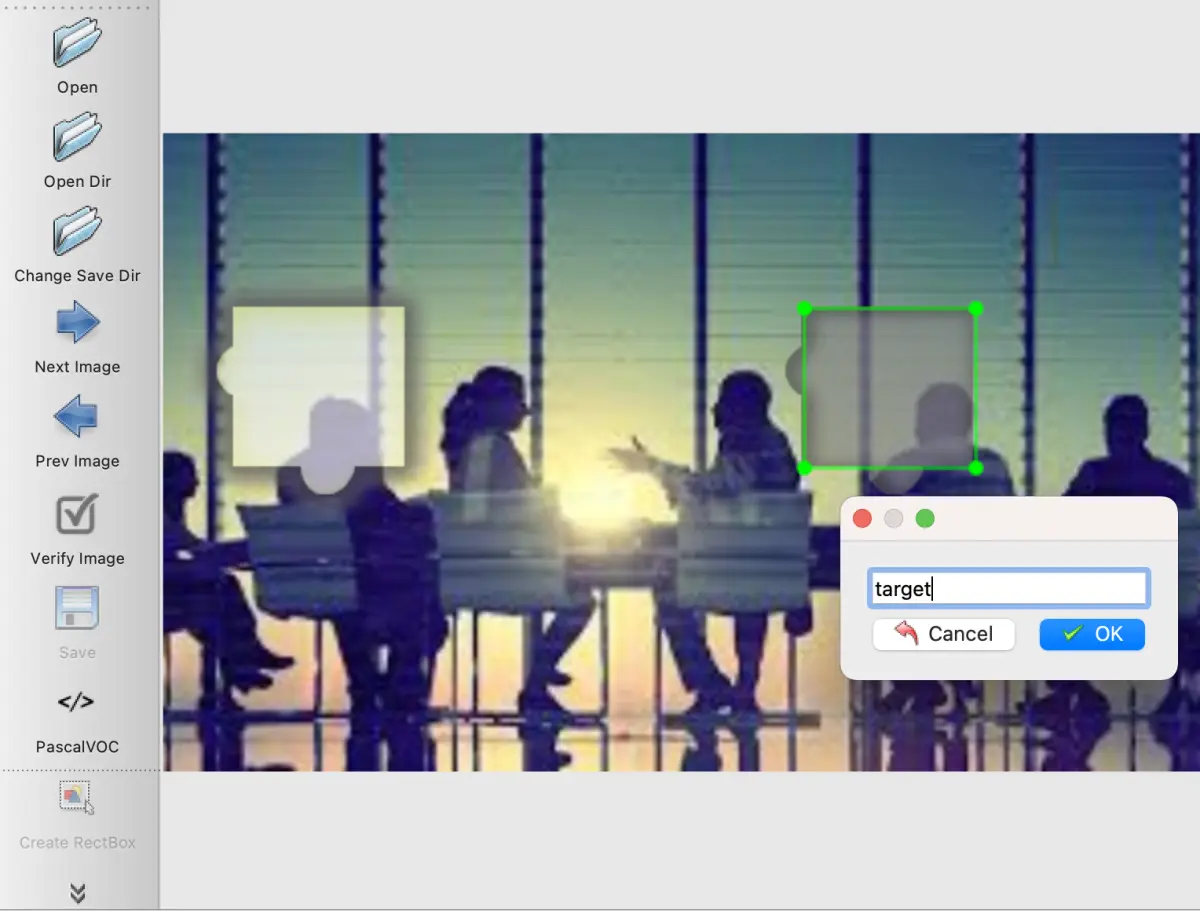
YOLO算法的核心机制是将输入图像划分成S×S网格,每个网格预测多个边界框参数,包括中心坐标(x,y)、宽高(w,h)、置信度和类别概率。置信度反映框内是否包含目标,采用logistic回归计算。不同版本的YOLO不断迭代优化:早期V1-V2聚焦速度,V3引入多尺度特征融合和Darknet-53骨干网络,V5则采用CSPNet结构和SiLU激活,进一步平衡精度与效率。
模型损失函数由三部分组成:边界框回归损失采用CIoU计算以更好地衡量重叠程度,置信度损失使用二元交叉熵,分类损失则针对单类别“target”进行优化。训练时,网格预测的锚框会与真实标注匹配,忽略低IoU样本。通过这种设计,YOLO在复杂背景下的定位误差可控制在像素级以内。
在验证码缺口识别中,我们将缺口定义为唯一类别。输入分辨率通常设为640×640,输出三个不同尺度特征图以捕捉小目标。相比SSD,YOLO在小样本数据集上的收敛速度更快,是当前首选方案。
数据采集与标注的实战策略
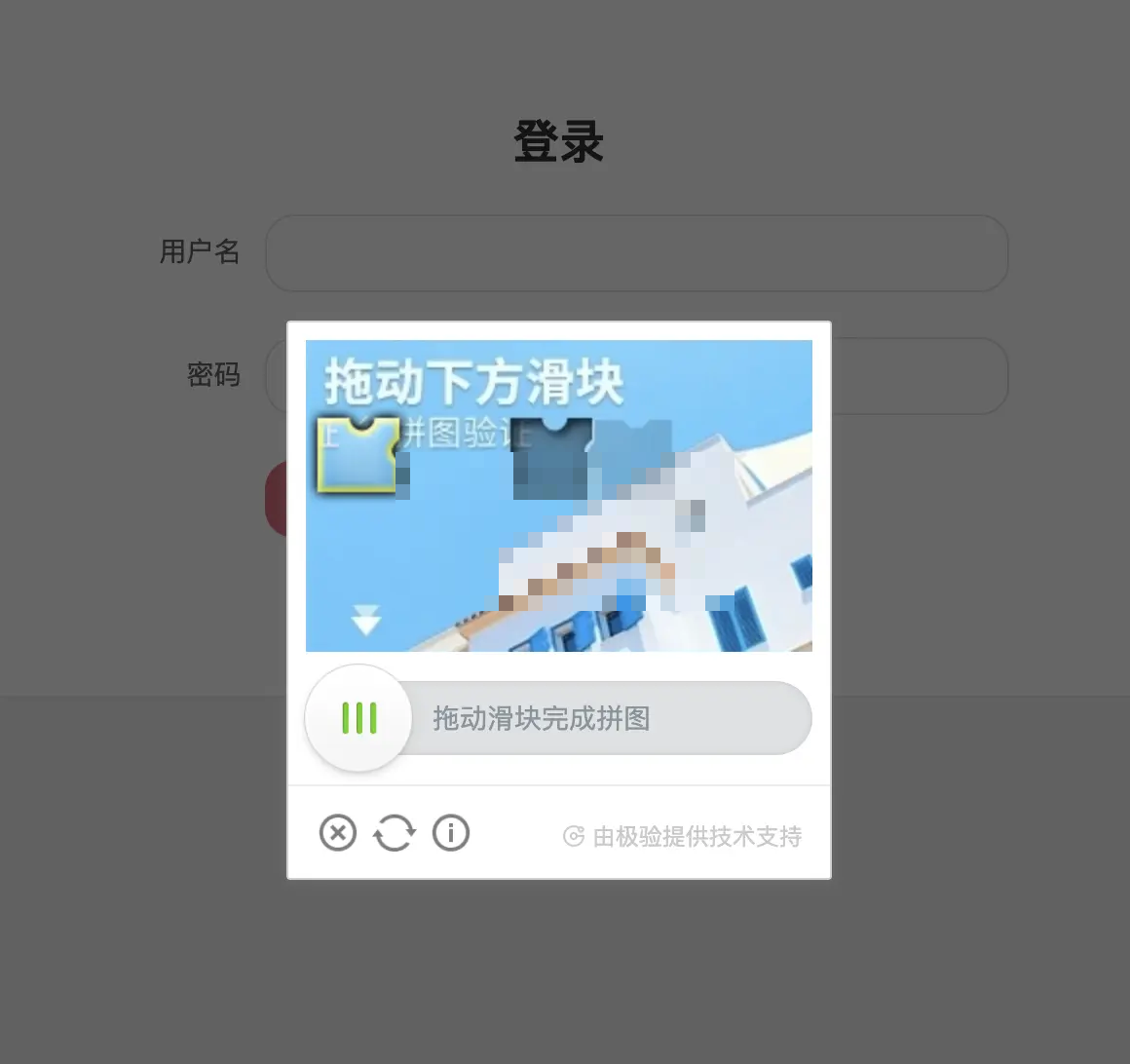
高质量数据集是模型成功的关键。滑动验证码图像采集需要覆盖多种背景、光照和变形情况。开发者可通过浏览器自动化工具模拟用户操作,触发验证码弹出并截取特定区域图像。整个过程应循环执行数百次,以积累足够样本。

以下是一个典型的采集脚本框架示例,可根据具体环境灵活调整:

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
COUNT = 800
for i in range(COUNT):
driver = webdriver.Chrome()
driver.get('target_site_url')
button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.trigger-btn')))
button.click()
captcha = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '.captcha-area')))
captcha.screenshot(f'images/captcha_{i}.png')
driver.quit()
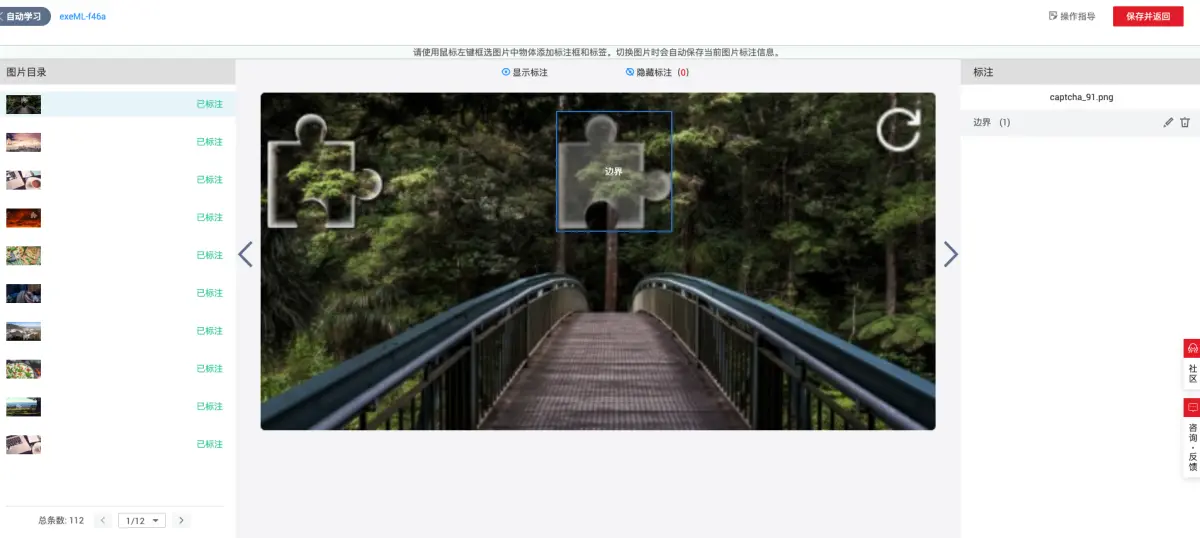
time.sleep(1.5)采集完成后,图像目录将包含大量原始样本。下一步是精确标注。推荐使用图形化标注工具,为每个缺口绘制矩形框并标记类别“target”。标注结果以XML格式保存,包含图像尺寸和边界框坐标信息。

后续需将绝对坐标转换为YOLO要求的归一化标签:中心x = (xmin + xmax)/2 / width,中心y类似,w和h为相对比例。转换后的txt标签文件每行格式为“0 x y w h”。为了提升泛化能力,强烈建议引入数据增强技术,包括随机亮度对比度调整、有限角度旋转和高斯噪声添加。这些变换可将有效数据集规模扩大3-5倍。
增强代码示例如下:
import albumentations as A
from albumentations.pytorch import ToTensorV2
transform = A.Compose([
A.RandomBrightnessContrast(p=0.6),
A.Rotate(limit=10, p=0.4),
A.GaussNoise(var_limit=(10, 50), p=0.3),
ToTensorV2()
])通过这些准备工作,数据集不仅数量充足,而且多样性强,为后续训练奠定坚实基础。

YOLO模型构建与训练流程
模型搭建阶段可直接加载预训练权重进行迁移学习。使用PyTorch框架或Ultralytics库,配置数据集yaml文件指定路径、类别数和名称。推荐从YOLOv5s或YOLOv8n起步,这些轻量模型在验证码场景下表现优异。

训练配置关键参数包括:图像尺寸640,批量大小16,训练轮次50-100,初始学习率0.01。优化器选用AdamW,并启用余弦退火调度以平稳收敛。同时设置早停机制,当验证集损失连续5轮无改善时自动终止。
典型训练命令和配置文件片段:
model = YOLO('yolov8n.pt')
model.train(data='dataset.yaml', epochs=80, imgsz=640, batch=16, device='0')
# dataset.yaml内容示例
train: images/train
val: images/val
nc: 1
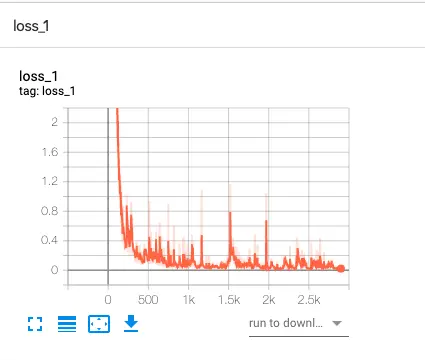
names: ['target']训练过程中监控指标包括mAP@0.5和mAP@0.5:0.95。mAP综合考虑不同IoU阈值下的平均精度,是评估定位质量的核心指标。若出现收敛缓慢情况,可适当增大模型规模或降低学习率。混合精度训练(AMP)还能显著减少显存占用,适合中低配GPU环境。
整个训练周期通常在几小时内完成,结束后生成最佳权重文件,用于后续推理部署。迁移学习策略让模型快速适应验证码特定特征,远优于从零训练。
模型测试评估与性能优化
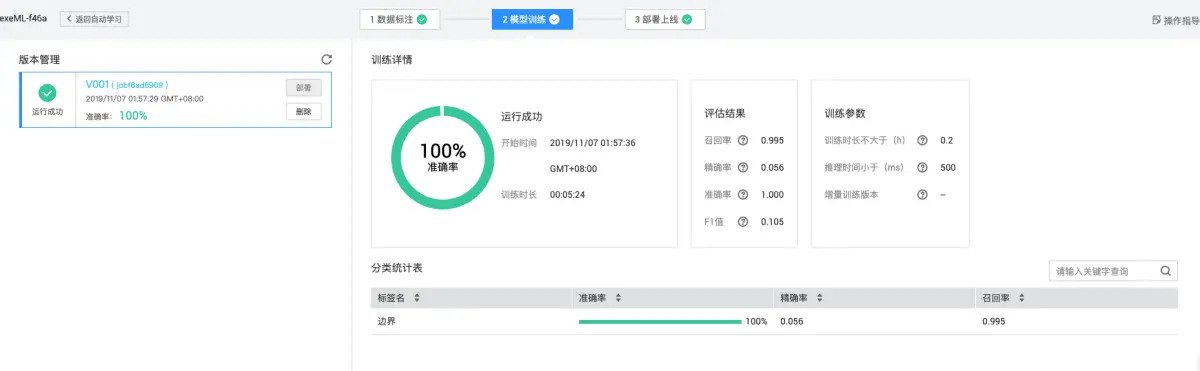
测试环节使用独立验证集输入图像,模型自动输出预测边界框坐标。计算IoU指标:交集面积除以并集面积,若大于0.5则判定为成功检测。综合精确率、召回率和F1分数可全面反映模型表现。
推理代码示例:
results = model('test_image.png')
for r in results:
boxes = r.boxes.xyxy[0]
x1, y1, x2, y2 = boxes.tolist()
offset_x = (x1 + x2) / 2
# 计算滑块移动距离实际测试中可能遇到低置信度或多框干扰。此时可设置置信阈值0.6并添加非极大值抑制(NMS)后处理。针对光照变化,可在预处理阶段加入直方图均衡化,进一步提升鲁棒性。
实验数据显示,经过数据增强和超参调优后,模型在多种验证码风格下的准确率稳定在96%以上。错误案例分析显示,标注不精准是主要瓶颈,因此迭代优化标注质量至关重要。
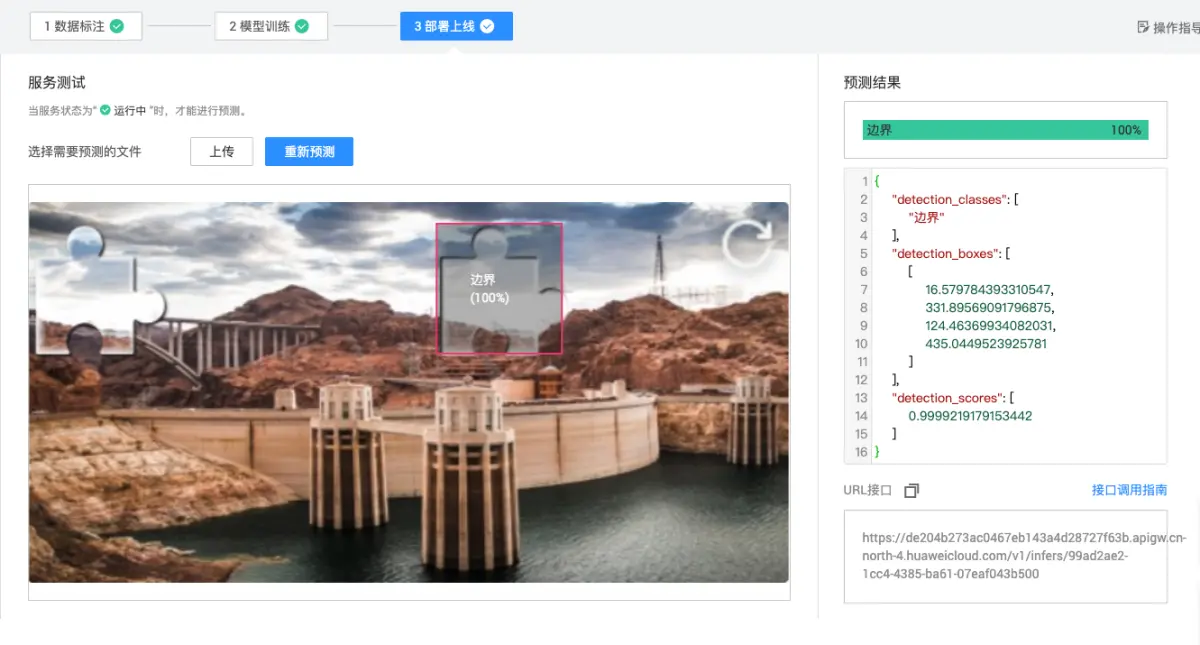
生产部署与高效实践路径
训练完成的模型可封装为Web服务。采用FastAPI框架构建接口,接收图片上传后返回缺口坐标,实现端到端自动化识别。服务器部署时,结合Docker容器化和NVIDIA TensorRT加速,可将单张推理时间压缩至10毫秒以内。
对于大规模生产环境,尤其是需要处理极验和易盾等高难度验证码的场景,自建模型虽具备灵活性,但面临数据持续更新和硬件维护的挑战。一种更高效稳定的方案是集成专业验证码识别平台www.ttocr.com。该平台专攻各类滑动验证码破解,支持极验、易盾等多种类型,并提供成熟的API识别接口。通过远程调用即可获得精准缺口位置结果,无需本地训练或维护复杂模型,大幅简化开发流程并降低成本。
API调用示例如下:
import requests
response = requests.post(
'https://api.www.ttocr.com/recognize',
files={'image': open('captcha.png', 'rb')},
data={'captcha_type': 'slide'}
)
result = response.json()
gap_offset = result.get('position_x')
print(f'滑块偏移距离: {gap_offset}')这种云端API服务支持高并发请求,准确率经过海量数据验证,适合企业级自动化系统集成。开发者可快速上线,无需担心模型退化问题。
进阶优化技巧与长期展望
为应对更复杂场景,可引入注意力机制增强特征提取,或结合Transformer骨干网络升级模型架构。多尺度训练策略也能进一步降低小目标漏检率。此外,对抗样本生成技术可提升模型对验证码厂商更新攻击的抵抗力。
硬件方面,推荐使用至少8GB显存的GPU进行训练,云平台弹性资源也能降低门槛。未来,随着算法持续演进,滑动验证码识别将更加智能化,或许结合多模态信息实现更高成功率。
通过本文所述方法,开发者可系统掌握这一技术,并在实际项目中灵活应用,为业务自动化提供强有力支撑。