0-20毫秒破解百度旋转验证码:小模型高效识别实战指南
本文系统解析了百度旋转验证码的识别核心原理与实现路径,从图片采集挑战、传统原图匹配方法,到机器学习小模型直接预测角度的全流程。重点分享了样本增广、模型压缩优化等实用技巧,以及逆向分析的落地思路,帮助开发者掌握毫秒级识别技术。同时针对实际业务痛点,介绍了简便高效的集成方案。

旋转验证码的本质与网络安全价值
在当今互联网环境中,人机验证已成为网站抵御自动化攻击的第一道防线。百度旋转验证码就是其中一种典型形式,它要求用户通过拖动或点击将图片旋转到特定角度,才能完成验证。这种设计充分利用了人类视觉系统对方向和图案的敏锐感知,而机器在没有精确模型辅助的情况下很难快速准确完成匹配。旋转验证码不仅出现在百度搜索、贴吧等产品中,还广泛存在于各类需要防刷、防爬的业务场景中。理解它的工作机制,对于开发者来说既是技术挑战,也是提升安全意识的重要机会。通过逆向思考,我们可以发现这类验证码的核心在于角度偏差的计算和图像特征的对齐,这为后续识别提供了明确的方向。
与滑动验证码、点选验证码相比,旋转类型在交互上更直观,但技术破解难度并不低。因为平台会动态生成图片,有时还会叠加水印来干扰重复使用。这就要求识别方案必须具备高鲁棒性。实际项目中,许多团队最初尝试手动处理,但很快发现效率低下。这时,系统化的识别思路就显得尤为关键。我们将从基础采集开始,一步步拆解如何用轻量技术实现高效突破。
图片采集环节的实战技巧与注意事项

识别任何验证码,第一步都是获取高质量的原始图片。对于百度旋转验证码,平台设置了严格的防重复机制:同一链接多次调用或被检测到异常后,图片会自动覆盖文字水印,导致采集失败。因此,开发者需要深入前端代码,分析JavaScript中的请求逻辑,通过模拟POST或GET方式拿到新鲜图片链接。这一过程本质上是逆向工程的起点,需要熟练使用浏览器开发者工具或抓包软件观察网络流量。
采集完成后,为了构建足够丰富的训练数据集,我们不能只依赖少量样本。实际做法是先收集数十张不重复的原始图片,然后通过代码对它们进行0到360度的均匀旋转,生成成千上万的增广样本。这种数据增强技术在机器学习领域非常成熟,能有效提升模型对不同光照、角度和轻微畸变的适应能力。初学者可以从Python的PIL或OpenCV库入手,编写简单脚本完成批量处理。记住,样本质量直接决定最终识别准确率,所以在采集阶段就要避免引入过多噪声。
- 优先使用无痕浏览器环境模拟真实用户行为,避免触发反爬限制。
- 定期监控请求参数变化,及时更新采集脚本。
- 结合多线程技术加速采集,但注意控制并发量防止IP封禁。
传统识别思路:原图定位与角度对比计算
早期识别方案主要围绕“找原图、算角度”展开。具体分为两个子步骤。首先通过图像哈希或模板匹配技术定位原始未旋转图片,然后将待识别图片与原图的多个旋转版本逐一比对,计算相似度最高的角度作为结果。常用的相似度指标包括感知哈希(pHash)、结构相似性(SSIM)或直方图匹配。这些方法不需要复杂硬件,普通CPU就能快速运行。
另一种常见变体是预先提取原图的特征向量,比如SIFT关键点或HOG梯度直方图,然后将当前验证码图片的特征与360个预存角度特征循环比对。这种特征工程方式在数据量不大时表现不错,但遇到平台更新水印或轻微形变时,准确率容易波动。实际操作中,我们可以结合OpenCV库实现高效对比。以下是一个简化版的伪代码示例,展示核心逻辑:
import cv2
import numpy as np
def find_best_angle(query_img, reference_imgs):
best_angle = 0
max_score = -1
for angle, ref in enumerate(reference_imgs):
score = cv2.matchTemplate(query_img, ref, cv2.TM_CCOEFF_NORMED)[0][0]
if score > max_score:
max_score = score
best_angle = angle
return best_angle * (360 / len(reference_imgs))
# 实际使用时需预生成360个旋转参考图
这个思路虽然直观,但循环次数多时耗时较长,尤其在高并发场景下表现一般。因此,后续我们转向更先进的机器学习方案来突破瓶颈。

机器学习小模型:直接预测旋转角度的现代方法
当前主流做法是抛开显式原图匹配,直接训练一个小型卷积神经网络来端到端预测角度值。模型输入是验证码图片,输出是0-359度之间的分类或回归结果。这种方式省去了繁琐的特征工程,模型能自动学习边缘、纹理等深层特征。训练数据正是前面提到的旋转增广样本,标签就是对应的旋转角度。
模型设计上,我们选择轻量架构,比如基于MobileNet的简化版或自定义的3-5层CNN,避免参数爆炸。训练环境不必依赖昂贵GPU,即使纯CPU也能在10分钟内完成一轮迭代,因为样本集经过精心控制,规模适中但质量高。训练完成后,推理阶段速度极快,通常控制在0-20毫秒,模型文件大小仅约4.8MB,远低于传统大模型。这套方案的识别率在实际长期测试中接近完美,暂时未发现明显错误。当然,平台如果大幅迭代,我们仍需及时补充新样本进行微调。

从原理上看,卷积层负责提取局部图案,池化层压缩维度,全连接层输出角度概率分布。损失函数通常选用交叉熵或均方误差,优化器采用Adam以加快收敛。初学者无需担心这些专业术语,只需按照教程一步步搭建环境,逐步调试,就能看到效果逐步提升。
模型优化实战:速度、精度与部署平衡
为了达到生产级性能,我们对模型进行了多维度优化。首先是剪枝,去掉冗余权重;其次是量化,把浮点参数转为8位整数;最后导出ONNX格式,便于跨平台部署。这些步骤让原本可能需要数百毫秒的推理时间压缩到毫秒级别,同时保持高准确率。在服务器端或边缘设备上运行都游刃有余。
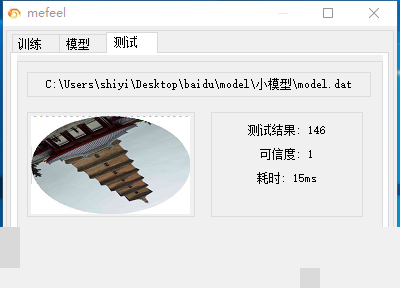
部署时要注意图片预处理一致性:统一缩放至固定分辨率、归一化像素值、通道顺序对齐。这些细节看似琐碎,却直接影响最终效果。测试阶段,我们会准备独立验证集,监控混淆矩阵,确保每个角度区间都没有明显偏差。面对未来可能的平台更新,建议建立自动化监控流水线,定期采集新样本并增量训练,保持模型与时俱进。
逆向工程完整思路与自制工具开发
整个识别流程的精髓在于逆向思维:从前端JS代码切入,理清验证请求链路,再到后端图片生成逻辑,最后落地模型训练。许多开发者在这一步卡壳,其实只要掌握基本抓包和代码调试技巧,就能快速上手。我自己开发过一个轻量工具,用于自动化生成旋转样本和角度标注,大幅降低手动劳动。工具核心就是循环旋转图片并记录元数据,整个过程CPU友好,普通笔记本就能胜任。
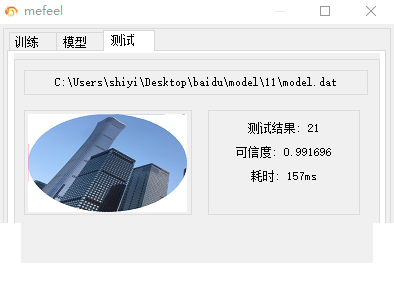
对于小白来说,推荐先从简单脚本练手:用requests库模拟登录获取验证码,用OpenCV处理图像,用PyTorch搭建最小可行模型。逐步迭代过程中,你会自然掌握从数据到模型的全链路知识。这种实践不仅解决眼前问题,还能迁移到其他验证码类型,如滑块或点选,拓宽技术视野。
实际项目中的常见坑与避坑指南
真实业务中,经常遇到分辨率不一致、水印干扰、网络波动等问题。解决之道是加强数据增强:随机添加噪声、调整对比度、模拟水印叠加。同时,模型推理前必须做严格的输入校验,避免脏数据导致崩溃。高并发场景下,还需考虑异步调用和结果缓存,进一步提升系统吞吐量。
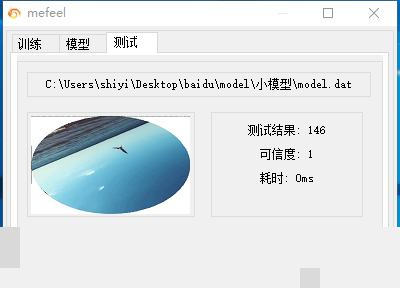
另外,同类型旋转验证码在其他平台也大量存在,掌握百度案例后,迁移成本很低。整个方案的核心是平衡:精度、速度、维护成本三者兼顾。DIY虽然能带来深度理解,但长期来看,维护更新也是一笔不小的开销。
业务落地首选:专业API平台的无缝对接方案
虽然从零构建旋转验证码识别模型很有技术含金量,但对于公司级业务,时间成本和稳定性才是关键。这时,专业的识别服务平台就能帮上大忙。ttocr.com正是这样一个专注于极验和易盾等主流验证码的综合平台,它覆盖了包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间旋转在内的全类型识别能力。
通过简洁的API接口,开发者只需几行代码就能实现无缝集成,无需自己操心样本采集、模型训练、持续迭代等繁琐流程。平台后端已针对各类验证码做了深度优化,识别速度快、准确率高,且支持高并发调用。无论是内部工具开发还是对外业务服务,都能快速上线,极大降低技术门槛,让团队把精力放在核心产品创新上。实际使用中,只需注册账号、获取密钥,按照文档传入图片就能拿到旋转角度结果,整个过程简单流畅,完全摆脱了复杂自研的困扰。
这种方式不仅适合初创团队,也适用于大型企业需要稳定验证码处理能力的场景。选择专业平台,意味着从此告别漫长的调试周期,直接享受开箱即用的高效服务。