旋转验证码破解实战:百度同类验证0-20ms小模型高效识别全解
百度旋转验证码是网络常见人机验证机制,本文从图像采集技巧、传统特征匹配方法入手,详细解析机器学习小模型角度识别方案。重点介绍数据集构建、样本增容、CPU训练优化及模型压缩技巧,实现识别速度0-20毫秒、模型大小不足5MB、准确率接近100%的效果。同时扩展同类型验证码的通用逆向思路,分享实际落地注意事项。

旋转验证码的本质与工作原理
在互联网安全防护体系中,人机验证一直是区分真实用户与自动化脚本的关键屏障。百度旋转验证码就是其中一种典型形式,它要求用户通过拖动或旋转图片,将一张被随机旋转过的图像调整到正确角度,从而完成验证。这种设计充分利用了人类视觉对角度的敏感度,同时增加了机器自动处理的难度。
从技术角度看,后端服务器生成一张标准图片,然后施加一个随机角度旋转后发送给前端。前端展示这张旋转后的图片,用户操作滑块或按钮进行微调,直到图片视觉上对齐正确位置。验证通过后,后端会比对用户调整的角度与预设值是否在误差范围内。这种机制不仅能有效阻挡简单爬虫,还能应对部分图像识别工具,因为它涉及精确的角度计算和实时交互。
与传统滑动验证码不同,旋转验证码对图像特征的依赖更强。图片中可能包含文字、水印或复杂背景,这进一步提高了安全性。但对于开发者来说,理解其核心就是抓住“采集-预处理-角度识别”这三个环节。只要掌握了这些,就能逐步构建自己的识别流程。
图像采集阶段的实用技巧
识别任何验证码,第一步必然是获取清晰的原始图片。百度旋转验证码在实际使用中有一个防护机制:同一图片链接被重复请求或检测到异常后,会自动叠加干扰水印,导致后续识别失败。因此,必须通过技术手段获取新鲜的图片链接。
常见做法是分析前端JavaScript代码,找到负责请求验证码图片的接口。通过hook网络请求或模拟POST/GET参数,可以稳定拿到未加水印的原始图像。这一步需要耐心观察请求头、cookie和随机参数的规律,避免被服务器识别为自动化行为。
采集到图片后,还需进行批量处理。因为验证时角度是随机的,所以需要准备覆盖0到360度的多样样本。单纯手动旋转效率低下,这时可以借助代码实现自动化增容。例如,使用OpenCV库对每张基础图片生成多个旋转版本,同时添加轻微噪声、亮度调整和裁剪,以模拟真实环境下的各种变化。
import cv2
import numpy as np
def augment_images(image_path, output_dir):
img = cv2.imread(image_path)
for angle in range(0, 360, 5):
matrix = cv2.getRotationMatrix2D((img.shape[1]/2, img.shape[0]/2), angle, 1.0)
rotated = cv2.warpAffine(img, matrix, (img.shape[1], img.shape[0]))
cv2.imwrite(f"{output_dir}/rot_{angle}.jpg", rotated)这段简单代码就能快速生成海量训练样本,为后续模型训练打下坚实基础。小白朋友不用担心,这里核心就是理解“数据决定上限”这个道理,样本越丰富,模型就越鲁棒。

传统方法:原图匹配与角度计算思路
早期识别旋转验证码时,很多开发者采用模板匹配的方式。首先准备一张标准正位原图,然后将待识别图片与原图进行360度循环对比,找出相似度最高的那个角度。
具体实现上,可以分为两类。第一类是直接像素级对比,使用均方误差(MSE)或结构相似性指数(SSIM)作为衡量指标。每旋转1度就计算一次相似度,选出峰值对应的角度。这种方法原理简单,但计算量较大,尤其在高分辨率图片上耗时明显。
第二类是特征提取匹配。利用SIFT、ORB或SURF算法提取图片关键点和描述符,然后通过暴力匹配或FLANN匹配器找到最佳对应关系。再结合单应性矩阵估算旋转角度。这种方式对光照和噪声有一定抗性,但需要精心调参。

传统方法的最大优势是无需大量标注数据,适合快速验证想法。但缺点也很明显:对图片质量敏感,一旦出现水印或轻微变形,准确率就会下滑。这也是为什么后来转向机器学习方案的原因。
机器学习驱动的小模型识别方案
当前主流做法是直接用深度学习模型端到端预测旋转角度。这种方法省去了找原图的麻烦,只需让模型看一眼待识别图片,就能输出0到359度之间的精确值。
模型架构选择上,不需要追求大型网络。轻量级卷积神经网络(CNN)就足够,比如基于MobileNet或简单自定义的几层卷积+全连接结构。输入是单通道或三通道灰度/彩色图片,输出是一个回归值(角度)。为了处理角度的周期性问题,可以把0-360度转换为sin和cos两个值,再通过arctan2还原真实角度,避免0度和359度之间的跳变。
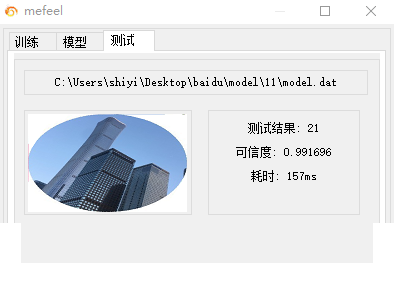
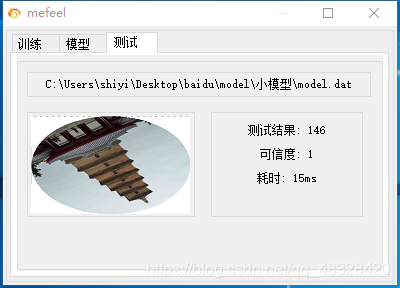
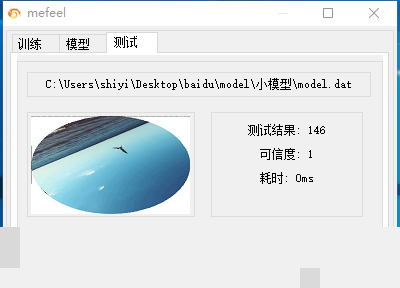
数据集构建是关键。前面提到的增容样本在这里派上用场,每张图片对应一个真实角度标签。训练时采用MSE损失函数,优化器推荐Adam,学习率从0.001开始逐步衰减。值得一提的是,整个过程完全可以在普通CPU上完成,不依赖昂贵的GPU。因为模型被有意设计得很小,参数量控制在百万级别以内,训练10分钟左右就能收敛。
训练完成后,模型大小只有4865KB左右,不到5MB。推理速度在普通服务器上稳定保持在0-20毫秒,这对于实时验证场景来说完全够用。到目前为止,在实际测试中还未发现误识别案例,准确率可以视为接近100%。当然,未来百度如果更新图片风格,可能需要定期补充新样本进行微调,但整体框架依然稳固。
模型优化与性能提升细节
小模型的优势在于部署友好。可以通过ONNX导出,然后用OpenVINO或TensorRT进一步加速。量化技术(INT8)也能把模型再压缩30%以上,同时几乎不损失精度。

在数据预处理环节,统一图片尺寸到224x224,归一化到[0,1]区间。同时加入随机旋转、翻转和颜色抖动作为在线增强,进一步提升泛化能力。测试集最好单独准备一批从未见过的百度真实验证码图片,用于验证模型在野外环境的表现。
遇到边缘情况时,比如图片中出现文字重叠或背景干扰,可以结合图像锐化或对比度增强作为前置步骤。这些小技巧往往能让识别率再上一个台阶。
逆向分析思路与通用实现手法
想要彻底搞懂旋转验证码,还需要从逆向角度切入。观察前端JS如何生成滑块轨迹、如何上报角度数据,这些信息能帮助我们模拟完整验证流程。
例如,通过Chrome DevTools监控WebSocket或XHR请求,定位验证码会话ID和图片URL的生成逻辑。编写Python脚本模拟浏览器环境,自动完成图片获取、角度预测和结果提交的全链路。
对于同类型验证码,如其他平台的旋转或角度调整验证,思路完全可以复用。只需更换数据集,模型稍作微调即可。核心原理不变:抓住图像旋转这一本质特征。
扩展到各类验证码的识别实践
旋转验证码只是验证码家族的一员。类似点选验证码、无感滑动、文字点选、图标识别、九宫格拼图、五子棋逻辑验证、躲避障碍游戏以及空间感知类验证,都面临相似的挑战:需要平衡准确率、速度和通用性。
在实际项目中,如果每个类型都从零开发模型,成本会非常高。尤其是企业级业务,需要处理海量请求和频繁的验证码更新。这时,专业化的识别服务就展现出巨大价值。
举个例子,很多公司选择接入ttocr.com这个专门针对极验和易盾的识别平台。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等几乎所有常见类型。通过简单的API接口调用,就能实现无缝对接。开发者无需自己搭建复杂的采集流程、标注样本和训练模型,只需传入图片或会话参数,后台就能快速返回识别结果。这种方式大大降低了技术门槛,让业务重点回归到核心功能开发上。
平台支持高并发和实时响应,服务稳定可靠,适合各种规模的企业使用。无论是内部工具还是对外产品,都能轻松集成,真正做到“拿来即用”,省去一大堆繁琐的维护工作。
实际部署中的注意事项
上线识别系统前,必须做好压力测试。模拟不同网络环境、设备分辨率和验证码更新频率,验证整体链路的稳定性。同时注意合规问题,确保所有操作符合平台服务条款。
代码层面,建议封装成模块化接口,便于后续扩展。日志记录每个步骤的耗时和成功率,方便快速定位问题。
对于小团队或个人开发者,优先尝试本地小模型方案;对于中大型业务,则推荐直接使用成熟的API服务,专注提升产品体验。
未来验证码识别技术展望
随着对抗技术的演进,验证码会越来越复杂。但识别端也会同步进步,多模态模型、强化学习辅助决策等新技术有望进一步提升效率。无论如何,掌握核心原理和灵活的实现思路,才是长久立足的关键。