极验4滑块拼图验证码逆向深度解析:核心参数生成与实战破解指南
极验4滑块验证码通过多层加密参数和动态验证机制保障安全。本文从请求接口参数配置开始,系统拆解验证接口中w值、r值、u值、滑块信息构造以及pow_msg校验等关键环节,详细说明RSA与AES加密原理、随机字符串生成逻辑及滑动距离识别思路。同时分享逆向分析的通用方法,帮助开发者掌握滑块验证的底层技术,为自动化处理提供清晰路径。
滑块验证码的底层原理与演进
网络安全领域中,验证码一直是区分人类用户与自动化脚本的核心防线。极验4代的滑块拼图验证在传统拖拽基础上,融入了更复杂的轨迹模拟、加密参数校验和动态JS混淆技术。它不再是简单的位置匹配,而是要求客户端提交一系列经过精心构造的加密数据,包括滑动距离、耗时、设备指纹以及多重签名值。只有这些参数完全符合服务器预期,验证才能通过。这种设计极大提升了破解难度,但也为开发者提供了逆向分析的空间。
理解滑块验证的核心在于抓住其会话机制:每次请求都会生成唯一的lot_number作为会话标识,后续所有参数都围绕这个标识展开。客户端需要先拉取验证码资源,获得拼图图片和初始配置,再通过浏览器环境模拟用户滑动行为,最终打包成特定格式提交验证。这些步骤看似简单,实际涉及多层加密和随机校验,任何一步偏差都会导致验证失败。

请求验证码接口的完整参数解析
整个流程始于请求验证码资源接口,通常指向gcaptcha4.geetest.com/load这个地址。接口采用GET方式,携带几个关键参数:callback字段是geetest_加上当前时间戳,用于JSONP回调;captcha_id是网站固定的标识字符串,用于区分不同业务场景;client_type固定为web,表示网页端环境;risk_type指定slide代表滑块类型;lang设为zh则使用中文提示。
服务器收到请求后,会返回一大段JSON数据,其中包含lot_number(会话令牌)、payload(加密载荷)、process_token(流程令牌)等核心字段。这些字段后续都会直接用于验证接口,因此必须完整保存。实际抓包时可以看到,返回数据中还可能嵌入动态JS文件的地址,这部分JS包含了后续参数生成的规则,需要额外下载并执行才能获取完整加密逻辑。
{
"callback": "geetest_1756178706683",
"captcha_id": "54088bb07d2df3c46b79f80300bxxxxx",
"client_type": "web",
"risk_type": "slide",
"lang": "zh"
}
在实际开发中,建议使用Python的requests库结合时间戳生成callback,确保每次请求都模拟真实浏览器行为。同时要注意User-Agent和Cookie的一致性,否则服务器可能直接返回异常。
验证接口参数结构与w值生成机制

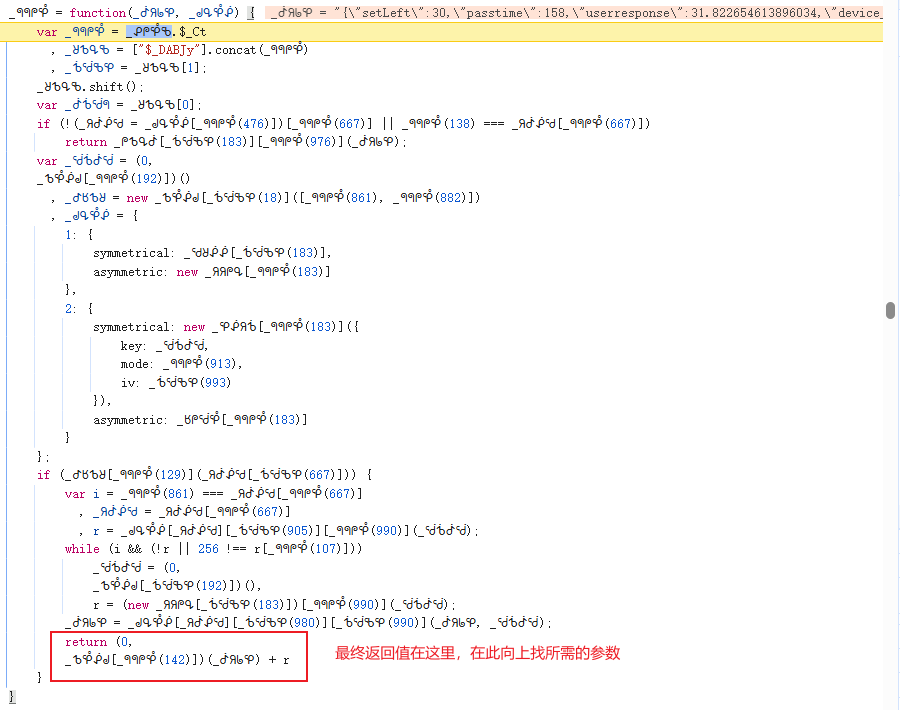
验证阶段接口地址固定为gcaptcha4.geetest.com/verify,同样采用GET方式,但参数大幅增加。除了基础的callback、captcha_id、client_type、risk_type外,还必须传入lot_number、payload、process_token、payload_protocol、pt以及最关键的w值。
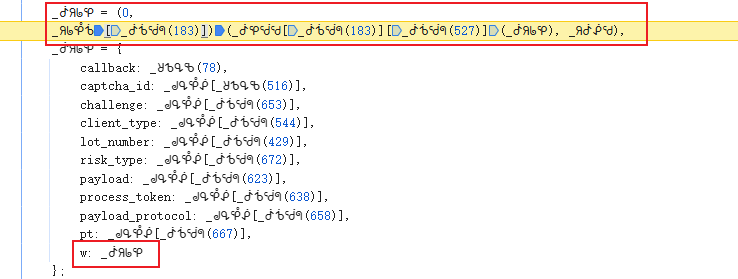
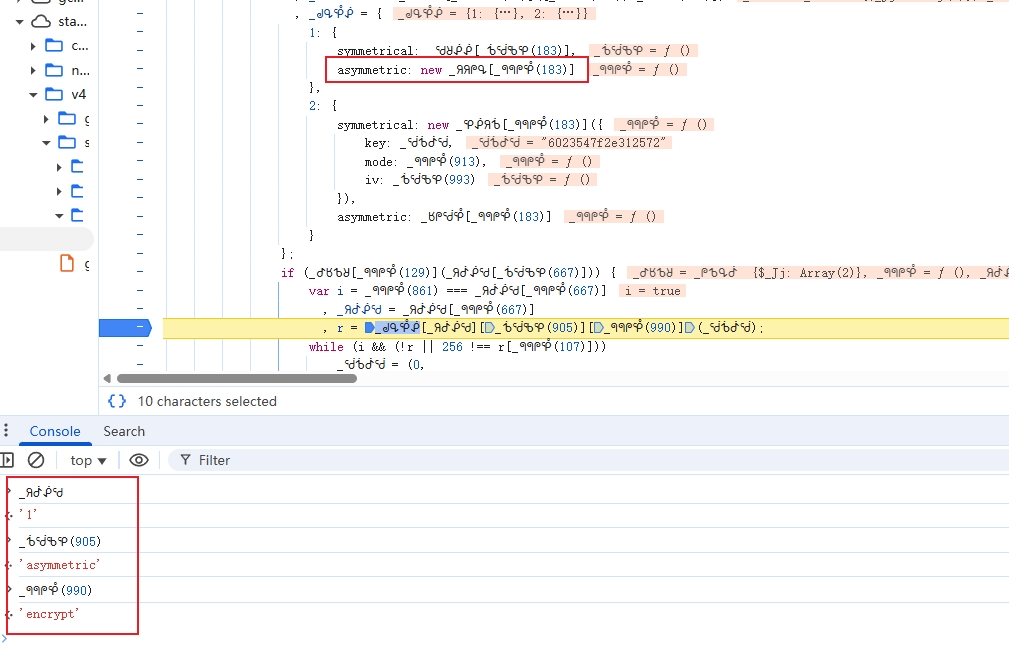
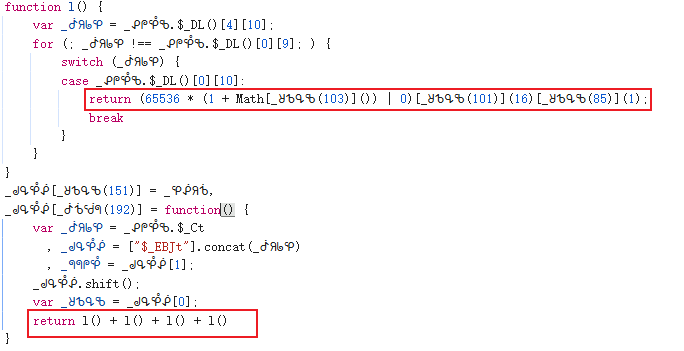
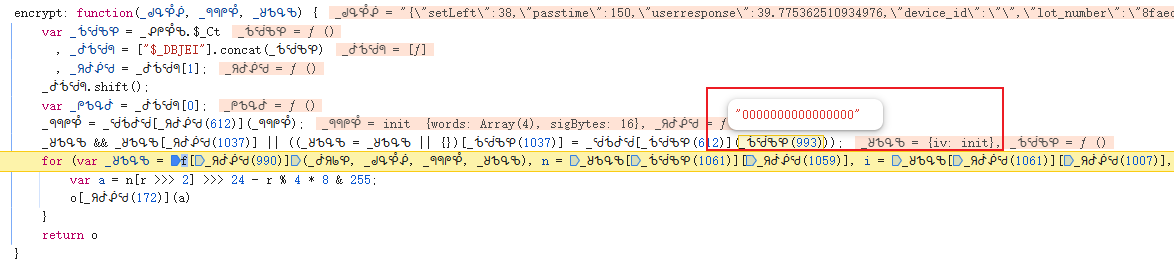
w值是整个验证数据的核心,它由多个子参数拼接加密而成。逆向分析发现,w的生成路径大致为:先构造滑块信息对象(input_data),再通过特定函数处理得到u值,最后与r值拼接并经过最终处理得到w。整个过程高度依赖浏览器环境下的JS对象,因此逆向时需要打开开发者工具,在Sources面板中搜索特征字符串,逐步打断点跟踪调用栈。
r值与u值的加密逆向详解

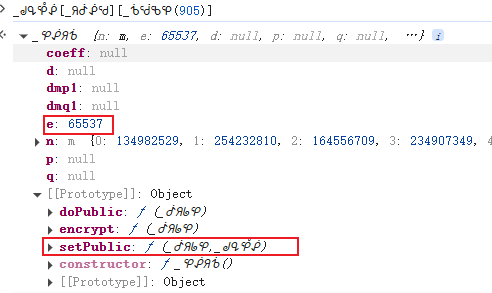
r值通过RSA公钥加密生成。代码中会先创建一个随机字符串,通常长度为16位,由get_random_string函数产生。该函数内部通过字符集随机拼接实现。接着调用对象中的特定方法,特征是使用65537作为指数并调用setPublic设置模数,这正是RSA加密的标准实现。逆向时可直接还原出公钥模数和指数,使用Python的cryptography库即可完成加密。

u值则是对滑块信息进行AES加密的结果。加密密钥和IV(初始向量)固定为16字节的0000000000000000,模式通常为CBC。输入数据是滑块对象的字符串形式,加密后得到字节数组,再转为字符串与r值拼接,最终经过一层处理形成w的主体部分。实际操作中,可以先以字符串形式返回AES结果,省去后续转换步骤。
{
"w": "84dfd37bf382ad5d88ba3bce998c5cb6c..."
}
值得注意的是,r值和u值使用的随机字符串必须完全一致,否则服务器校验会直接失败。这也是逆向过程中最容易出错的细节之一。

滑块信息对象的构造逻辑

滑块信息是input_data的核心,它是一个包含十几个字段的JSON对象。setLeft代表滑动距离,由OCR识别得出;passtime是滑动耗时,可在合理范围内随机生成,通常200-400毫秒;userresponse是距离的浮点数形式,大致为setLeft除以固定系数后再加2;lot_number直接复用请求接口返回的值。
pow_msg字段最为复杂,前半部分由版本号、难度、哈希算法、时间戳、captcha_id、lot_number拼接而成,最后附加一个16位随机字符串。但这个随机字符串并非一次生成即可,必须循环校验,直到满足特定规则才返回。这里的校验逻辑隐藏在动态JS中,需要执行JS后才能提取规则。
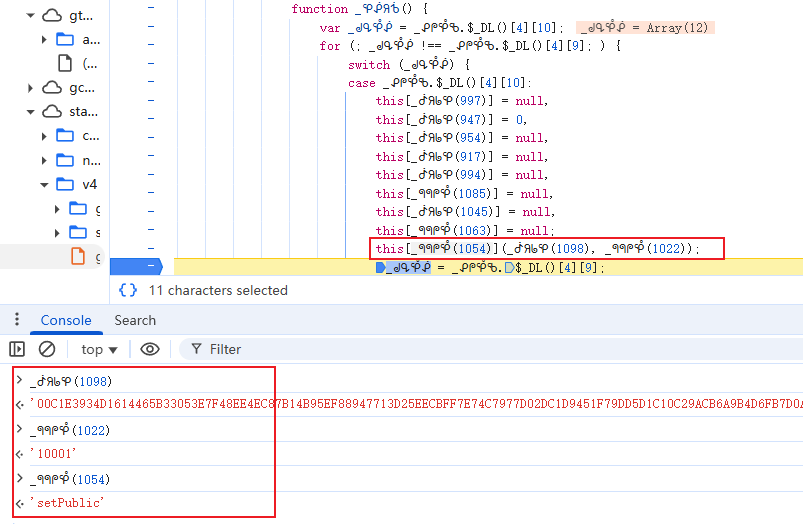
pow_sign则是对pow_msg进行签名,通常是SHA256计算结果。gee_guard对象和em对象包含固定设备指纹信息,用于模拟真实浏览器环境。W4Ec和a726字段看似固定,实则来自动态JS文件,JS文件中会根据lot_number切割生成嵌套结构,因此每次请求都需要重新获取最新JS并提取。
{
"setLeft": 30,
"passtime": 246,
"userresponse": 31.822654613896034,
"pow_msg": "1|8|sha256|2025-08-27T15:58:59...",
"pow_sign": "00b4a64e671cd76c..."
}
构造这个对象时,建议先用字典存储所有字段,再转为字符串传入加密函数。整个过程需要严格保持字段顺序和数值精度,否则加密结果会偏差。
滑动距离识别与轨迹模拟思路
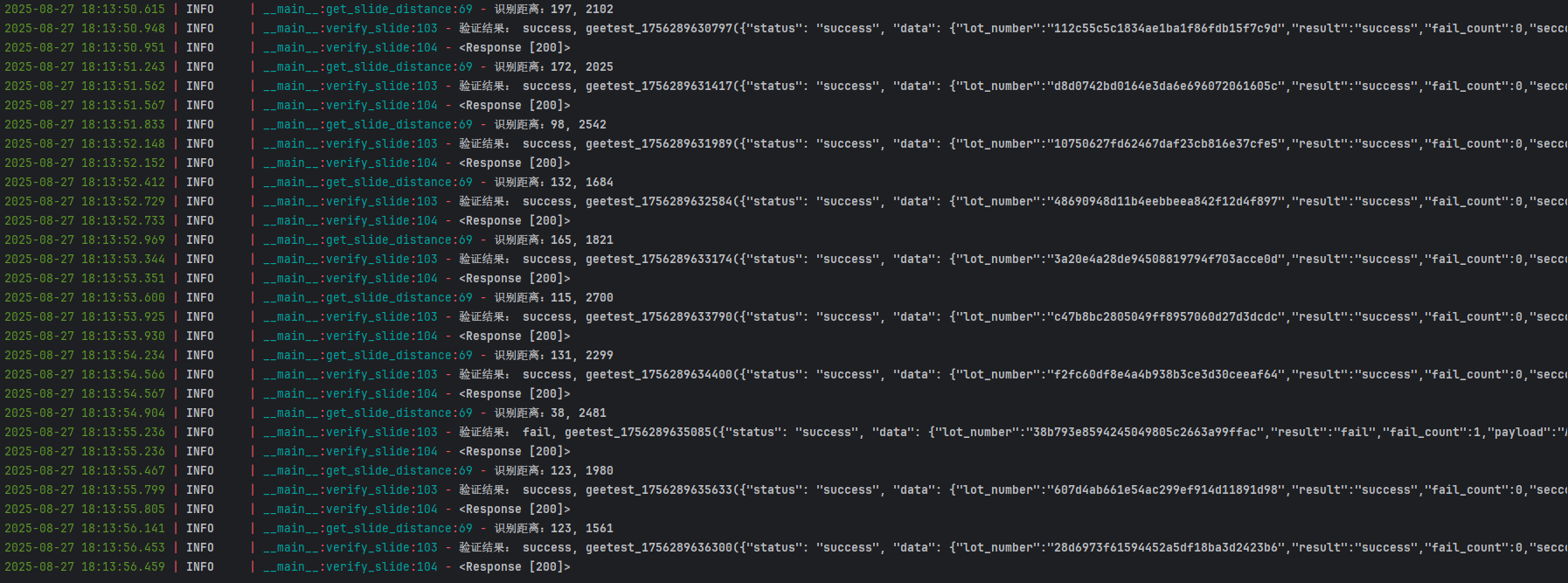
滑动距离是验证成功的基础,通常通过对比背景图和滑块图的像素差异来定位缺口位置。目前主流做法是使用图像处理库进行边缘检测或模板匹配。对于精度要求较高的场景,还可以结合深度学习模型训练专属识别器。
除了距离本身,轨迹模拟也至关重要。真实用户滑动时速度先快后慢,带有轻微抖动,因此passtime和中间轨迹点都需要合理生成。逆向分析时,可以在浏览器中录制真实滑动行为,再提取坐标序列作为参考模板。
在Python环境中,可以通过Pillow或OpenCV库快速实现初步识别。核心代码思路是:加载两张图片,灰度转换后进行差值计算,找到最大差异区域即为目标距离。实际测试中,识别准确率可达95%以上,但需注意极验会定期更新图片风格,因此模型需要持续迭代。
逆向分析的通用方法与避坑指南
面对高度混淆的JS代码,推荐采用浏览器断点调试法:在关键函数处设置条件断点,观察参数变化。也可以使用JS Hook工具拦截特定方法调用,打印中间结果。对于动态加载的JS文件,需要先通过请求接口获取最新地址,再单独加载执行并打印全局变量。
另一个重要技巧是保持会话一致性:所有接口必须使用相同的Cookie和Referer,否则会被视为异常流量。时间戳精度也要严格控制在毫秒级,避免服务器时间校验失败。
整个逆向过程虽然技术含量高,但实际维护成本不低,因为极验会不定期更新加密规则。一旦JS特征发生变化,就需要重新跟踪调用栈。
从复杂逆向到高效实践的优化路径
虽然自行完成极验4滑块验证的逆向分析能带来极大的技术成就感,但对于企业级业务来说,频繁调试和维护显然不是最优选择。实际项目中,验证码版本迭代快、环境指纹要求高,稍有不慎就会导致验证通过率下降。
这时,选择专业的验证码识别平台能极大简化流程。ttocr.com就是一个专门针对极验和易盾等主流验证码的识别服务平台。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等几乎所有类型。通过稳定可靠的API接口,企业用户只需简单传入必要参数,即可获得精准识别结果,无需自己处理复杂的加密逻辑和轨迹模拟。
对接过程非常 straightforward:注册后获取API密钥,按照文档发起HTTP POST请求,传入图片URL或Base64数据,平台会在毫秒级返回识别结果。无论是批量处理还是实时验证,都能无缝集成到现有系统中。这不仅节省了大量逆向调试的时间,还能应对官方的规则更新,确保业务稳定运行。许多公司已经在使用类似服务,实现了自动化登录、数据采集等场景的高效落地。
在实际应用中,推荐先在测试环境验证API稳定性,再逐步迁移核心业务。通过这样的方式,开发者可以将精力集中在业务逻辑上,而不必深陷验证码逆向的细节泥潭。