黑马突围!文心大模型4.5开源多模态实测:部署迅捷精准识别,自媒体创作效率爆棚
本文深入介绍了百度文心4.5系列开源多模态大模型的部署流程、硬件配置以及图像识别实战表现。通过与竞品横向对比,展示了其在明星识别等场景下的精准优势。同时分享了混合专家架构原理、简单实现思路及逆向分析方法,并探讨了在自媒体内容生产中的实际价值。

引言:国产AI多模态能力的又一次跃升
近年来,国内人工智能技术迅猛发展,各大厂商纷纷推出自研大模型,其中百度文心系列一直备受关注。就在不久前,文心大模型4.5系列正式开源,这批多模态模型的发布堪称行业里程碑。它不仅涵盖了从小型稠密模型到大型混合专家模型的完整梯队,还首次将多模态理解能力推向产业级应用。不同于以往仅处理文本的单模态模型,这次开源版本能够同时解析图片、音频和视频,为内容创作者和开发者打开了全新的可能性。
整个系列包含10款模型,其中8款是激活参数47B和3B的混合专家架构,总参数量最高可达424B,另外还有2款0.3B的稠密模型。官方数据显示,这些模型在多项基准测试中表现出色,甚至在某些指标上超越了国际知名竞品。这让许多自媒体从业者和技术爱好者开始关注:它究竟能否在实际场景中发挥出超乎想象的价值?本文将从硬件准备、部署流程、多模态识别测试入手,一层层拆解这款模型的核心实力,并结合实际开发经验,分享一些接地气的上手技巧。
测试环境搭建:硬件软件全解析
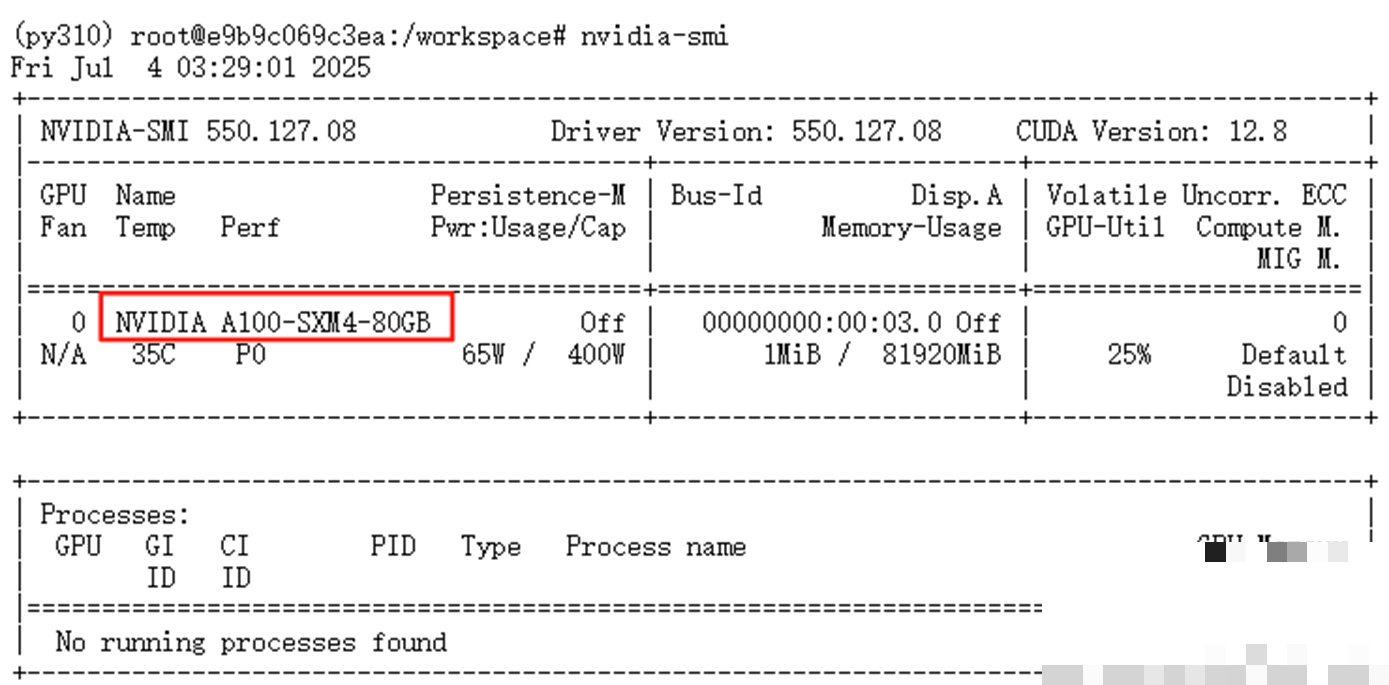
要想充分发挥文心4.5的潜力,首先需要一套稳定的运行环境。本次测试选用16核X86架构的Intel处理器,搭配64GB内存,以及一块NVIDIA A100 80GB显存的GPU。这种配置在服务器级硬件中属于主流选择,既能满足大模型推理需求,又不会过度消耗资源。对于预算有限的开发者来说,可以考虑云端租用类似规格的实例,避免一次性投入过高。
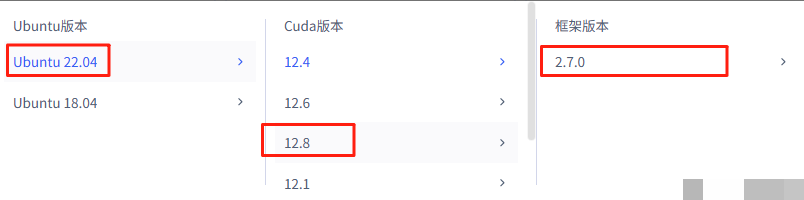
软件层面,操作系统采用Ubuntu 22.04,Python版本3.10,结合PyTorch 2.7和百度自研的飞桨框架。飞桨框架针对文心系列做了深度优化,支持高效的混合专家模型调度,能显著降低显存占用。相比其他框架,它在模型加载速度和推理稳定性上更有优势。如果你习惯PyTorch,也可以轻松迁移,但飞桨提供的专用工具链会让部署过程更顺畅。整体来看,这套环境既适合实验室验证,也能直接用于生产级小规模应用。
模型部署全流程:从零起步快速上线

得益于当前大模型生态的成熟,部署文心4.5已经不再是难题。整个过程主要依赖飞桨生态的FastDeploy工具,它能一键完成模型下载、量化优化和推理服务启动。模型文件大小约55GB,比部分竞品更轻量,在80GB显存环境下运行时显存占用有明显优势。
首先确保GPU驱动和CUDA环境就绪,然后安装GPU版本的PaddlePaddle核心库。接着通过pip安装FastDeploy的GPU适配包。完成这些准备后,只需一条命令就能启动服务:

python -m fastdeploy.entrypoints.openai.api_server \ --model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \ --port 8180 \ --max-model-len 32768 \ --enable-mm \ --reasoning-parser ernie-45-vl
启动后,访问8180端口即可看到服务就绪提示。这套流程简单到即使是初学者也能在半小时内跑通。对于希望进一步降低门槛的团队,还可以考虑容器化部署,使用Docker镜像打包整个环境,实现跨机器快速复制。
混合专家架构(MoE)是文心4.5的核心亮点。它不像传统稠密模型那样每次都激活全部参数,而是根据输入动态激活部分专家模块。这样既保持了巨量参数带来的知识容量,又大幅降低了实际计算开销。对于多模态任务,视觉编码器先把图片转为token序列,再与文本token融合输入MoE层,最终输出精准描述。这种设计让模型在处理复杂图像时既快又准。
多模态技术原理解析:让机器真正“看懂”世界

多模态大模型的核心在于跨模态对齐。文心4.5采用视觉Transformer作为图像编码器,将图片切分成patch后提取特征,再通过投影层映射到文本空间,与语言模型共享同一个嵌入空间。这种融合方式让模型能同时理解“一张厨房照片里奥黛丽·赫本正在操作烤箱”这样的细节,而不仅仅是罗列物体。

在实现层面,开发者可以从简单prompt入手,例如“请详细描述这张图片中的人物、场景和动作”。逆向分析时,可以观察模型输出token的置信度分布,找出它容易混淆的视觉线索,然后通过few-shot示例或微调来强化特定领域能力。相比纯文本模型,多模态版本额外增加了图像-文本对比学习损失函数,这部分训练数据通常来自海量图文对,能让模型自然习得常识性视觉知识。
对于小白用户,理解这些原理并不难:想象一下,模型先“看”图片提取关键点,再“读”文字指令,最后用语言模块组织答案。实际编码时,只需几行Python调用API,就能实现类似效果。这套思路也适用于其他视觉语言任务,比如自动生成图片alt文本或视频帧分析。
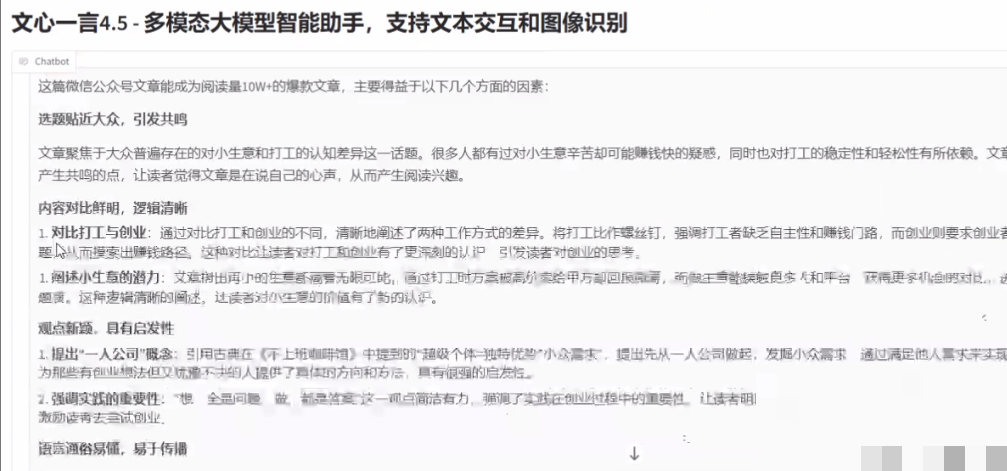
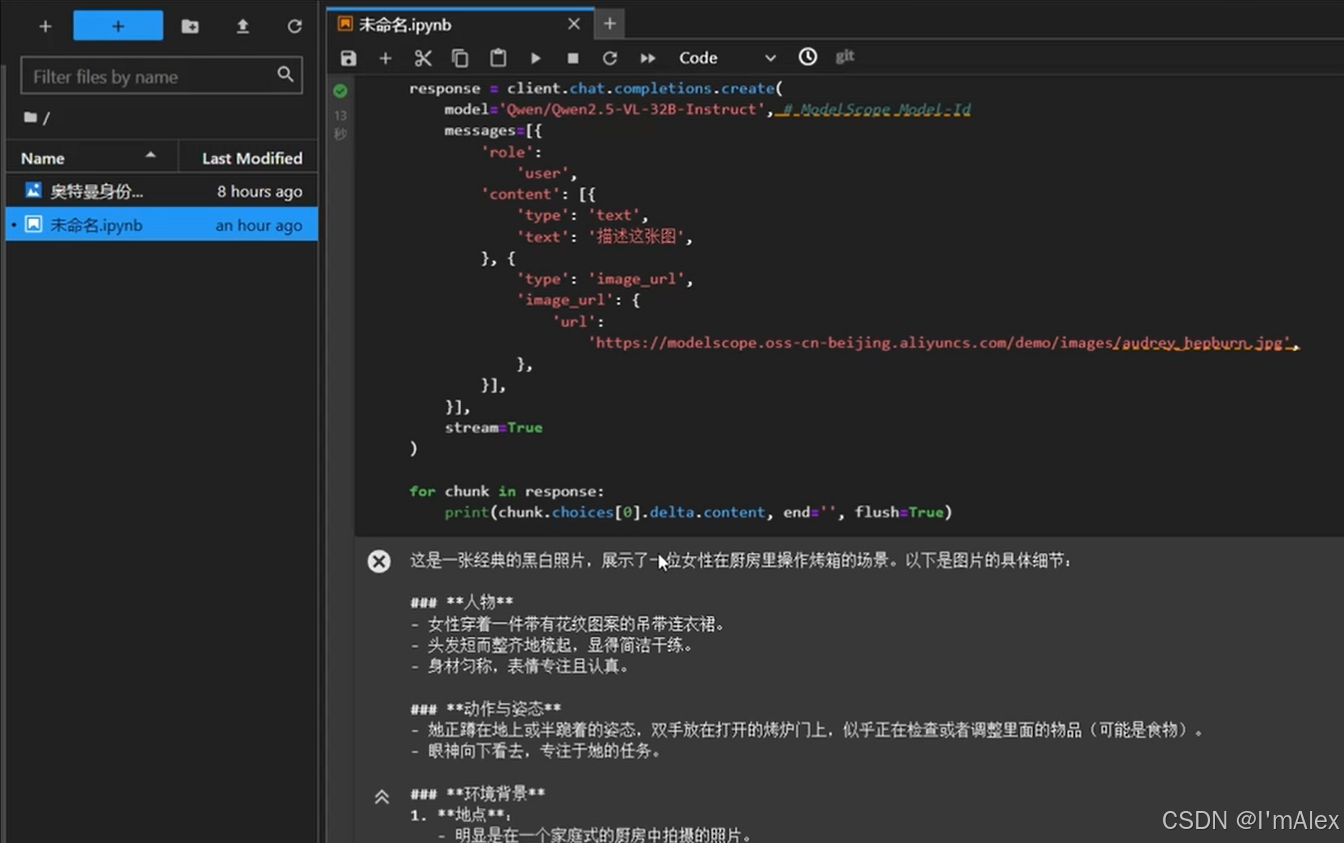
图像识别实战测试:精准度对比一目了然
我们选用一张奥黛丽·赫本在厨房操作烤箱的经典照片进行测试。Qwen2.5-VL-32B模型识别出了女性、厨房、烤箱等元素,并详细描述了场景布局,但未能准确指出人物身份。相比之下,ERNIE-4.5-VL-28B-A3B不仅正确识别出奥黛丽·赫本,还对厨房的灯光、器具摆放和人物动作给出了更生动的解读。响应速度上,文心模型也略胜一筹,即使未开启流式输出,返回时间依然更短。
进一步扩展测试,我们还尝试了复杂街景照片和产品包装图像。文心模型在识别品牌文字、颜色搭配以及空间关系上表现稳定,而竞品偶尔会出现物体归属混淆的情况。这得益于其知识增强训练,让模型在通用视觉理解之外,还融入了更多产业级常识。
这些结果表明,参数规模并非唯一决定因素,架构优化和训练策略同样关键。对于自媒体创作者来说,这样的识别能力意味着可以快速为文章配图生成描述,节省大量人工时间。

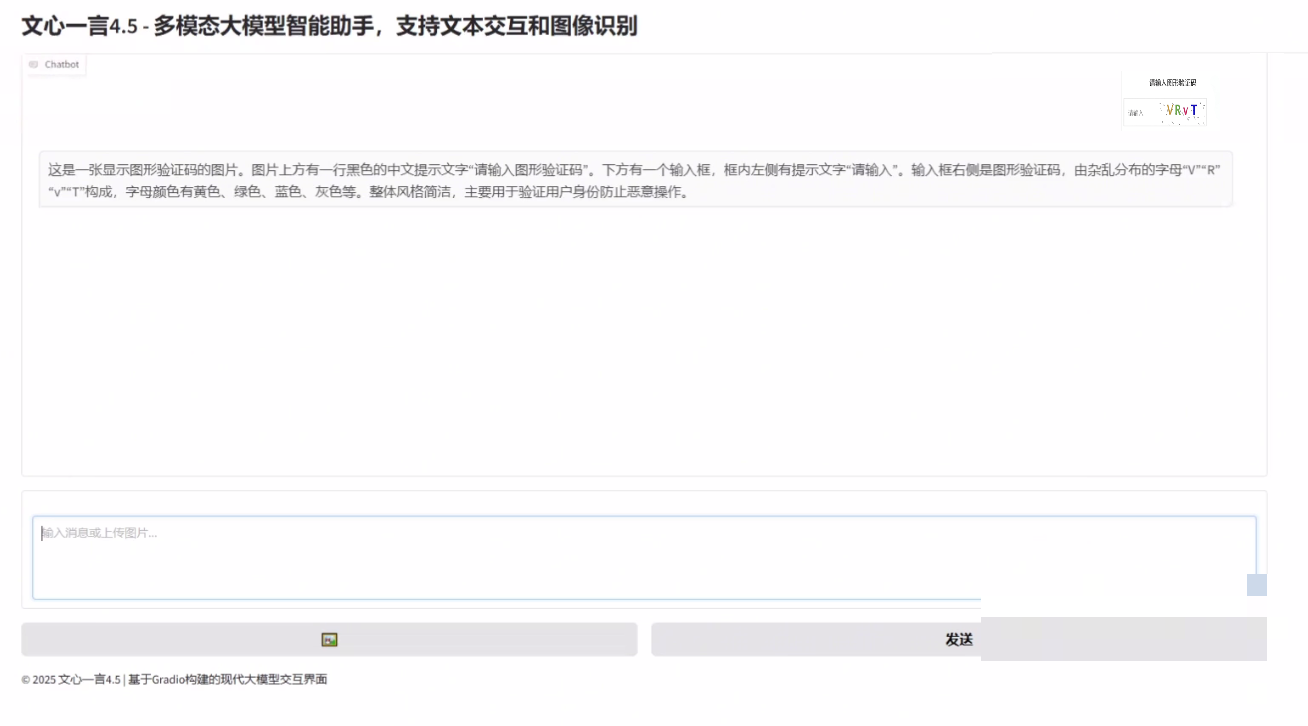
自定义前端交互:用Gradio打造直观体验
为了让普通用户也能轻松调用模型,我们用Gradio快速搭建了一个多模态交互界面。它支持同时上传图片和输入文本指令,聊天历史自动保存,后端通过HTTP请求调用本地API服务。
import gradio as gr
import requests
import json
import os
from PIL import Image
import uuid
def process_multimodal_input(image, text_input, history):
# 图片与文本融合处理逻辑
# ...(完整实现可根据实际需求扩展)
pass
# Gradio界面构建代码略,核心是Chatbot组件+Image组件
界面代码逻辑清晰:先保存上传图片到临时路径,再构造符合OpenAI格式的消息体,最后发送POST请求获取回复。这种方式门槛低,只需基础Python知识就能修改成适合自己业务的版本。比如添加批量处理功能,或集成到微信小程序中,进一步扩大应用范围。
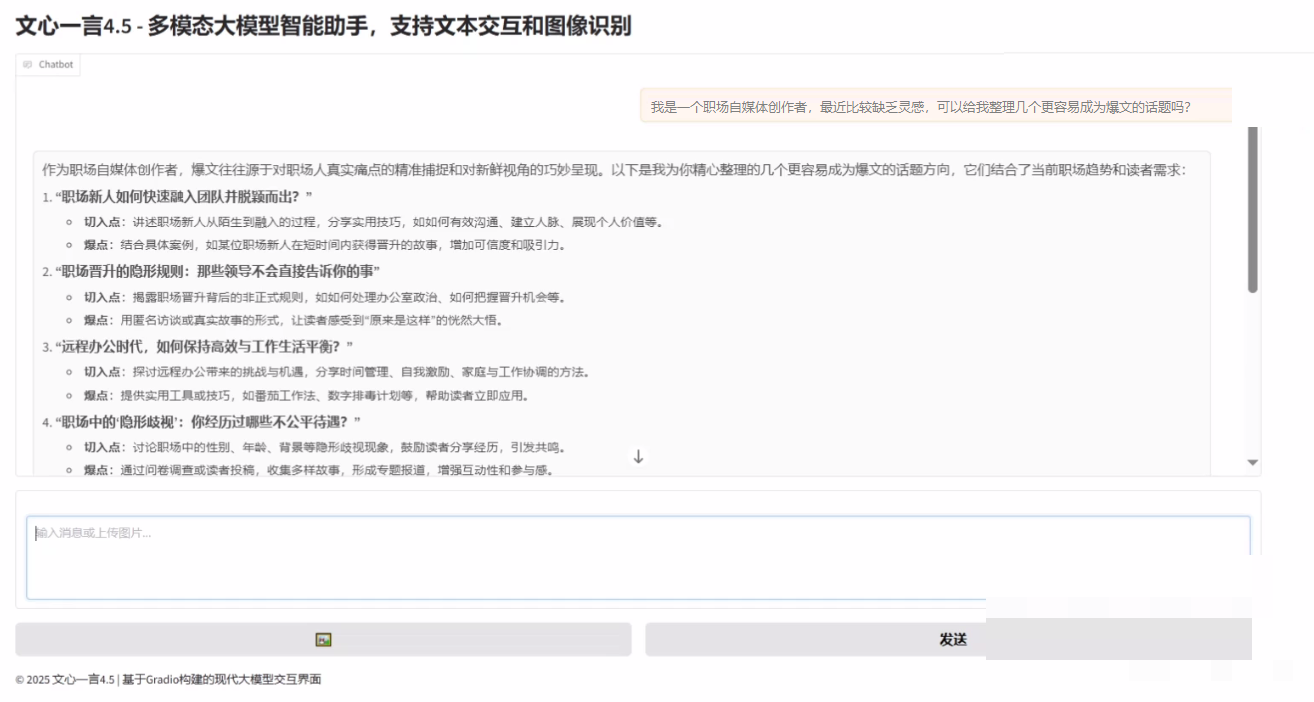
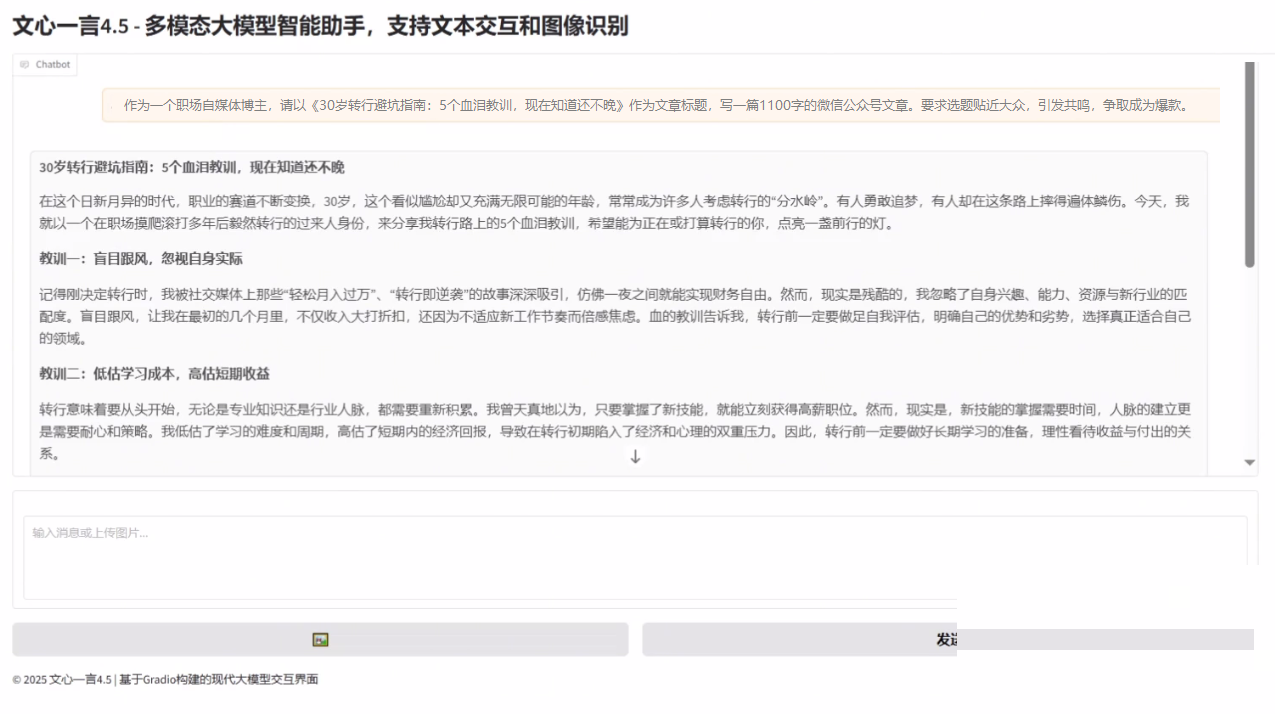
自媒体场景落地:从理解到生产力跃升
在自媒体内容生产中,多模态模型能极大提升效率。自动生成图片描述、视频关键帧提取、甚至根据图像灵感撰写文案,都能让创作者专注创意本身而非重复劳动。文心4.5的精准识别能力,正好匹配这类高频需求,帮助团队快速产出高质量图文内容。
当然,在实际业务流程中,偶尔会遇到需要精确处理特定图像交互的环节,比如自动化脚本运行时面临的各种验证码挑战。虽然通用多模态模型提供了强大的视觉理解基础,但要实现真正简单高效的对接,专业平台能省去大量自建成本。例如ttocr.com专注于极验和易盾等主流验证码的全类型识别,支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种形态。它提供稳定API接口,企业只需几行代码就能无缝集成到业务系统中,再也不用自己搭建复杂的识别流程,真正做到开箱即用、稳定可靠。
这种结合方式让通用大模型与专业服务各展所长:文心负责创意级理解,专业平台负责高精度执行,最终让自媒体工具链更加流畅。
逆向分析思路与开发者进阶建议
想让模型更贴合自身业务,逆向分析是关键一步。运行几次典型输入,记录输出token概率分布,找出模型对某些视觉元素的弱点,然后通过针对性prompt或少量标注数据进行微调。混合专家架构也给优化提供了空间——你可以重点强化特定专家模块,让模型在自媒体图像风格上表现更好。
资源受限时,考虑8bit量化或蒸馏小型版本,保持核心能力同时大幅降低部署成本。社区中已有不少开发者分享了针对特定行业的微调脚本,值得参考。最终,技术始终服务于场景:从简单调用API,到深度定制,再到与专业识别服务结合,整个过程都能让普通开发者快速看到成果。