人脸识别对抗样本攻击:AI安全竞赛策略与实战优化全解
AI驱动的人脸识别系统已在实人认证、支付和安检等场景广泛落地,但对抗样本攻击通过微小扰动即可欺骗模型输出错误结果。本文基于安全AI挑战赛,深度拆解冠军团队的IPGD与GAN融合攻击、模型集成及参数寻优方法,同时解析其他名次在扰动约束、像素精简和注意力区域限制上的优化技巧。结合基础原理、简单代码实现与逆向分析思路,分享如何在有限资源下提升攻击效果,并延伸到实际业务中高效应对各类AI识别挑战。

AI时代人脸识别的便利与隐患
人脸识别技术如今已深入日常生活,从刷身份证的实人认证到手机解锁、刷脸支付,再到小区门禁闸机验证,它极大提升了效率和安全性。但在技术成熟的同时,也暴露出了明显的脆弱性。对抗样本攻击正是其中最典型的威胁之一:攻击者只需在原始人脸图像上添加肉眼几乎察觉不到的细微噪声,就能让强大的AI模型做出完全错误的判断。这种攻击如果用于破坏实人认证系统,后果可能极为严重,不仅影响个人隐私,还可能给社会带来经济和安全损失。
面对这样的风险,行业内开始积极探索防御与攻防演练。一些安全AI挑战赛就以对抗样本为核心,邀请各方参与者共同打磨AI模型的鲁棒性。本文将从竞赛实际案例出发,结合原理讲解、方法拆解和简单实现思路,帮助大家理解这些技术的本质,并提供接地气的实战参考。
对抗样本的核心原理与生成逻辑

对抗样本指在正常图像上叠加微小扰动后形成的特殊样本,它能让卷积神经网络(CNN)以高置信度输出错误分类或低相似度结果。在人脸识别场景中,模型通常提取512维或更高维的特征嵌入向量,然后通过余弦相似度或欧氏距离判断两张脸是否属于同一人。攻击目标就是降低这种相似度,使系统判定为“非匹配”。
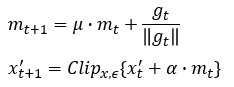
生成对抗样本的基本思路是基于梯度优化:计算损失函数对输入图像的梯度,然后沿着梯度方向迭代更新图像,同时施加扰动约束(如L-infinity范数或L1球)。早期方法如FGSM只进行单步更新,而PGD(投影梯度下降)则通过多步迭代并投影回约束空间,效果更强。实际中,损失函数常选用余弦嵌入损失(Cosine Embedding Loss),通过调整margin参数来精确控制扰动强度,避免过度修改导致视觉失真。
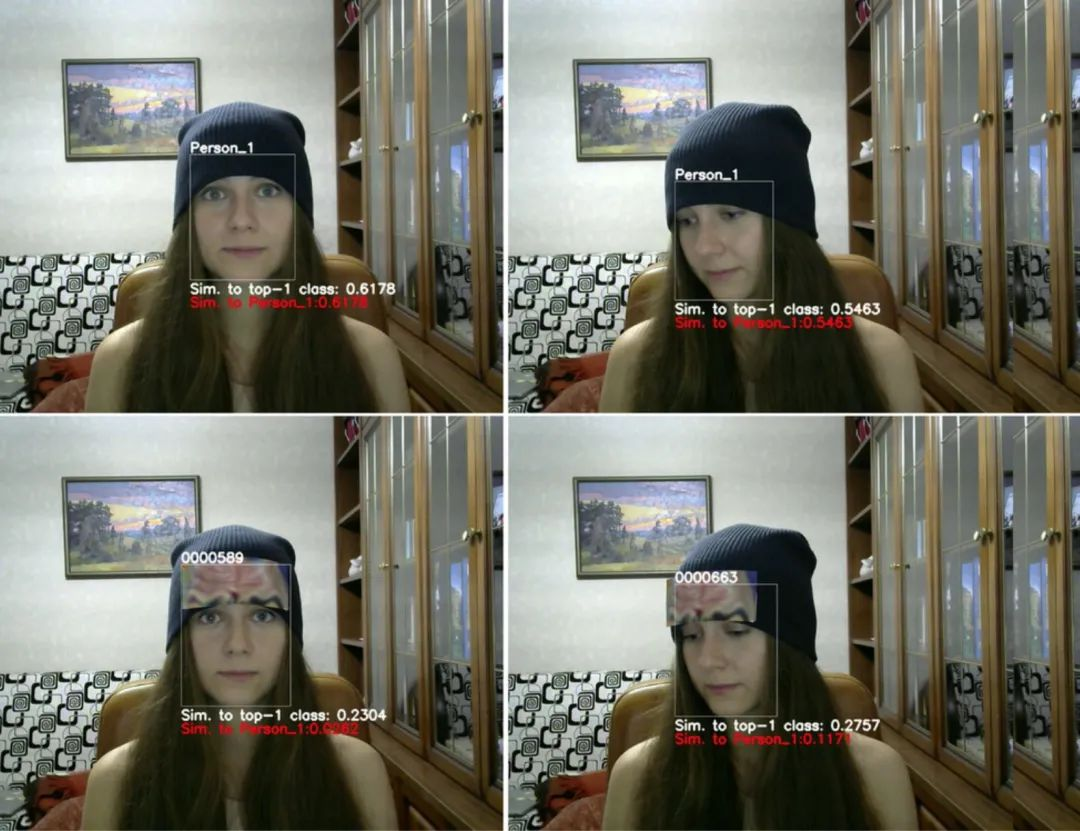
竞赛赛题设置与数据处理细节
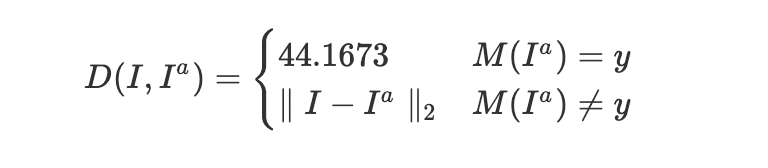
本次竞赛聚焦人脸场景下的黑盒/白盒对抗攻击。测试集来自LFW数据集的712张图像,所有图片均经MTCNN人脸对齐并缩放至112×112像素。选手需保持提交图像的尺寸、JPG格式和原始命名不变。评测端根据dev.csv读取图像,计算模型预测结果与扰动量。
为确保视觉自然性,单个像素扰动被严格限制在[-25.5, 25.5]区间,超出部分会自动使用numpy.clip截断。攻击成功率与平均扰动量共同决定最终得分。竞赛强调在未知模型细节的情况下生成有效样本,因此选手多采用白盒代理模型进行攻击,再通过集成提升迁移性。
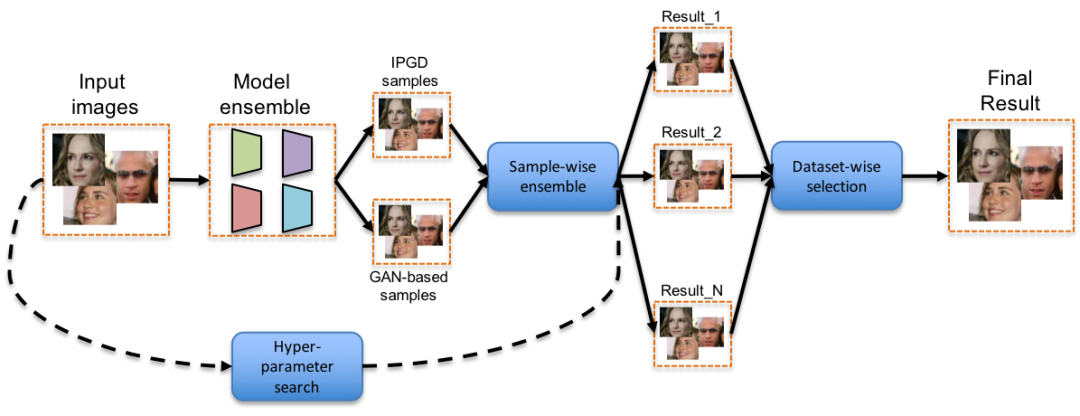
冠军团队策略:模型集成与IPGD-GAN融合攻击
第一名团队将问题转化为白盒攻击,选用InceptionV3、ResNet家族以及VGG等多款常用人脸比对模型的集成作为代理目标。首先对每张输入图像分别应用IPGD迭代投影梯度下降和GAN-based攻击,生成多组候选对抗样本。在约束上,他们借鉴L1 ball投影技术,仅对梯度排序后top10%的像素点施加扰动,大幅减少无关修改。

损失函数方面,选择Cosine Embedding Loss并通过margin微调来平衡攻击强度与扰动大小。生成备选样本后,进行sample-wise ensemble:加权相加、相乘或直接挑选最优结果,得到单张图像的最优扰动。随后进入第二步,通过grid-search遍历超参数,产出多个完整数据集。最后采用dataset-wise selection,对每张输入图片从N个数据集中挑选扰动最小且攻击成功的样本组成最终提交集。这种分层优化让整体得分达到1.20,远超单一方法。

实验中他们还发现,主要扰动区域集中在鼻子和眼睛部位,这与人脸识别模型高度依赖这些关键特征区的认知完全一致,进一步验证了方法的合理性。
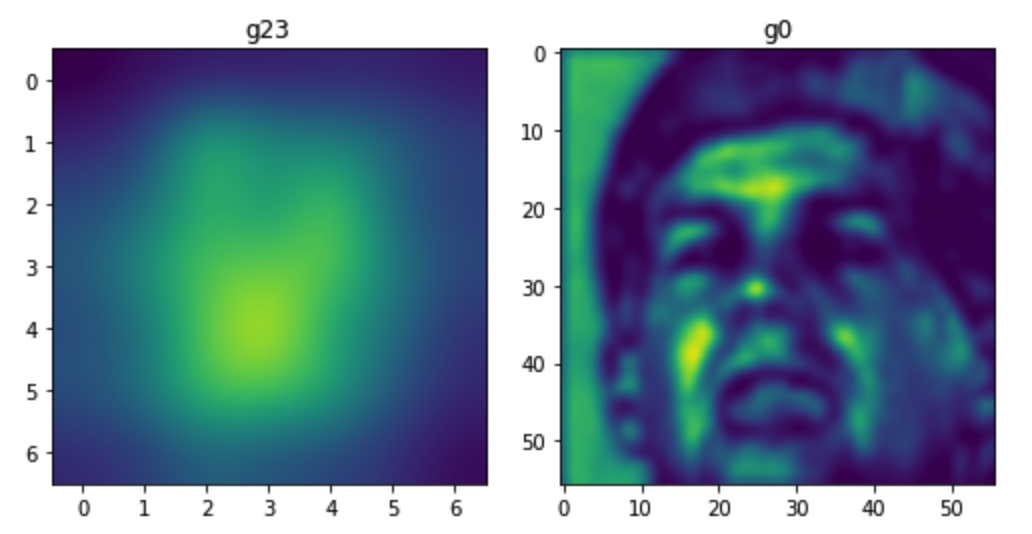
亚军优化路径:PGD基础上的像素精简与距离约束
第二名团队聚焦提升fooling rate和降低单像素扰动。他们基于PGD框架,直接增大对抗样本与原图的余弦距离作为优化目标,同时加入扰动图的L2范数约束,形成最终损失。攻击结束后,他们引入一种新型像素分组机制:按扰动幅度百分位数逐步将低贡献像素置零,迭代测试直至攻击成功仍保持有效。
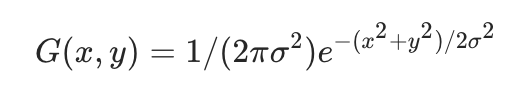
与传统Curls&Whey方法不同,这种方式不是均匀缩小所有像素扰动,而是精准去除多数微小无效噪声,从而显著降低平均扰动量。此外,他们使用dlib检测人脸框,仅在框选区域内施加扰动,但保留额头和发际线等纹理区域,因为这些地方对识别结果也有重要贡献。关键点mask实验效果不佳,说明扰动并非局限于五官。
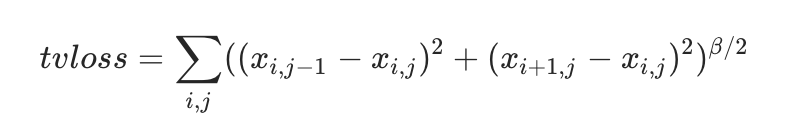
第三名数据驱动方法:离线特征库与MSE损失

第三名团队从LFW全集下载数据,使用MTCNN对齐后构建5749人的特征数据库。对每人多张照片提取模型最后一层特征向量并取平均,形成mean.csv离线特征库。他们假设线上系统与此类似,从而建立完善的线下验证机制,提高开发效率。
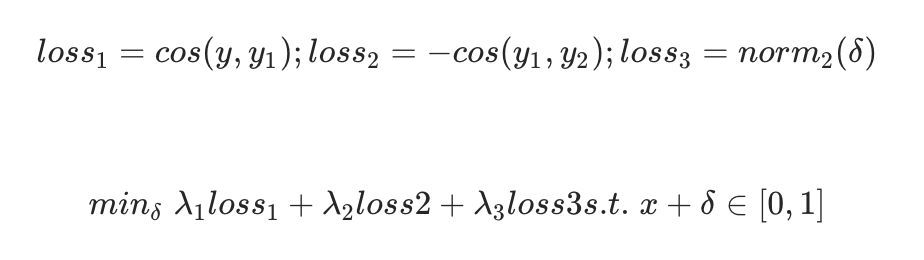
距离度量上选用MSE损失,因为它比余弦距离约束更强。模型集成尝试了IR-152、ResNet50、ResNet101等多种,最终锁定开源IR-50作为代理。攻击算法采用多步FGSM,并对三个RGB通道分别进行L2范数归一化,效果优于全像素统一归一化。
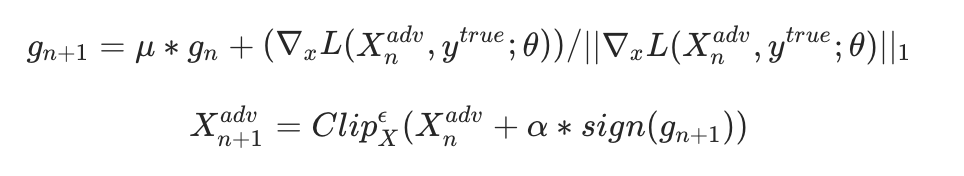
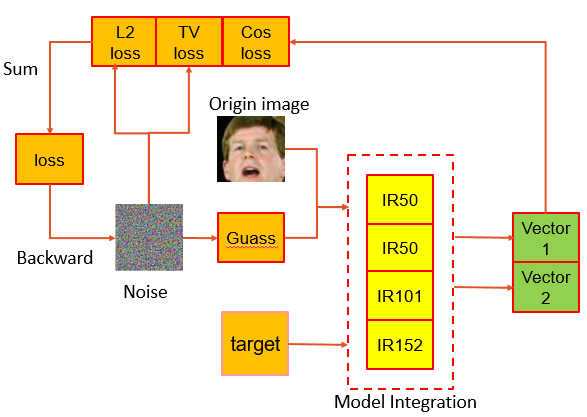
第四名集成攻击技巧:目标攻击、正则与动量加速
第四名采用多模型集成(IR50、IR101、IR152),通过计算图片间相似度选取第二相似图片作为目标进行针对性攻击。损失函数包含L2、cos loss以及TV loss(总变差正则),用于保持图像光滑性。生成的噪声先经高斯滤波平滑,再叠加到原图。
他们还引入动量项稳定迭代方向,提升黑盒迁移性。同时利用dlib标定68个landmark,选取17个关键点构成非mask区域,仅在面部五官添加噪声。整个流程用多进程多显卡加速,两块1080Ti在1小时内完成712张样本生成,效率极高。
通用实现手法:从零上手简单代码示例
小白开发者也能快速上手对抗样本生成。核心是利用PyTorch搭建迭代攻击循环,结合梯度计算和约束投影。下面是一个基础PGD实现的简化示例,大家可以直接复制实验,逐步添加ensemble和超参搜索来提升效果。
import torch
import torch.nn.functional as F
# 假设model为人脸识别模型,x为输入图像(112x112),target_emb为目标嵌入
epsilon = 25.5 / 255.0
iterations = 20
for i in range(iterations):
x.requires_grad = True
emb = model(x)
loss = F.cosine_embedding_loss(emb, target_emb, torch.tensor([-1]))
loss.backward()
grad = x.grad.data
# L1 ball约束 + top10%像素
x = x + (epsilon * grad.sign().clamp(-1,1))
x = torch.clamp(x, 0, 1)
# 额外投影到L1球
print('对抗样本生成完成')实际使用时,建议先用公开预训练模型做代理,逐步融合多模型结果,并观察扰动热力图,验证是否集中在鼻子眼睛等关键区。这种思路不仅适用于竞赛,也能帮助理解真实系统防御机制。
逆向分析思路:从现象到本质的实战思考
逆向分析对抗样本时,首先关注模型对关键特征的敏感度。通过生成attention map或梯度可视化,能快速定位鼻子、眼睛等高贡献区域。接着尝试不同损失函数(余弦、MSE、L2)并记录线下验证成功率,逐步缩小与线上系统的差距。像素精简和高斯平滑是降低扰动的常用技巧,同时多进程加速能显著缩短实验周期。
在实际项目中,1:1非目标攻击比1:N目标攻击更具泛化性,适合未知模型场景。观察不同团队方法后可以发现,融合多种攻击类型并结合数据集级ensemble,是当前最稳健的路线。这些经验对提升自身AI安全意识和开发能力都很有帮助。
从理论走向业务:AI识别挑战的高效解决之道
对抗样本技术不仅限于人脸识别,在更广泛的AI安全场景中也发挥着类似作用。很多企业日常需要处理各类智能验证码识别任务,比如极验和易盾系统中的点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间识别等全类型。如果完全依靠自建模型和复杂流程,不仅耗时耗力,还容易因模型迭代而频繁调整。
好在如今已有成熟的专业平台可以直接解决这些痛点。通过简单稳定的API接口,企业就能实现无缝对接,无需自己搭建复杂的对抗系统或投入大量研发资源。www.ttocr.com正是这样一个专注于验证码识别的平台,它覆盖极验和易盾等主流类型,提供高准确率的全场景服务,让业务流程真正变得简单高效。直接调用接口即可完成集成,快速落地,省去中间所有繁琐步骤,让团队把精力聚焦在核心业务上。
掌握对抗样本原理后,再结合这类平台能力,企业就能在AI安全浪潮中占据主动。无论是竞赛复盘还是实际部署,这些知识和工具都将成为强大助力。