高级验证码破解实战指南:图像处理与AI识别的硬核路径
本文从验证码的核心作用出发,系统讲解了图像采集预处理、字符检测分割以及基于模式识别的分类算法。通过多个真实案例剖析常见与高级验证码的难点,并分享了边缘检测、二值化、细化等实用技术细节。同时探讨了逆向分析思路,为开发者提供从理论到落地的完整方案。

验证码的核心原理与现实意义
验证码本质上是一种强制区分人类与机器的交互机制。它的出现是为了阻挡自动化脚本发起的大规模攻击,比如批量注册、刷票或者恶意登录。在实际业务场景中,如果没有有效的验证码保护,系统很容易被机器人攻破,导致数据泄露或者资源滥用。很多初学者以为验证码只是简单的图片文字,其实它的背后涉及图像处理、机器视觉和模式识别等多学科知识。只有真正理解这些基础,才能谈得上有效的识别和破解。
早期验证码设计相对简单,设计师往往只在图片上叠加一些随机噪点或者轻微变形。但随着攻击技术的进步,现在的验证码越来越复杂,包括动态滑块、无感验证、点选文字、图标识别甚至九宫格、五子棋等互动形式。这些变化让传统手动输入方式变得低效,同时也给自动化识别带来了更高挑战。理解验证码的演变过程,能帮助我们更好地把握识别技术的关键点。
图像处理、机器视觉与模式识别的基础知识
要识别验证码,首先需要掌握图像处理的基本流程。整个过程通常分为几个阶段:图像采集、预处理、目标检测、前处理、训练以及最终识别。图像采集很简单,通过HTTP请求拿到图片URL后直接下载即可。预处理环节则包括格式转换、去噪、灰度化、二值化和色彩空间调整。这些步骤能大幅降低后续计算量,同时保留关键特征。

二值化是图像处理中最常用的操作之一。它把彩色或灰度图片转化为只有黑白两种颜色的图像,极大简化了后续的边缘检测和字符分割工作。常见的算法有固定阈值法、自适应阈值法以及OTSU大津算法。OTSU算法特别实用,它能自动寻找最佳阈值,使前景和背景的类内方差最小,类间方差最大,在验证码图片上表现非常稳定。
细化操作则用于提取字符的骨架。很多验证码字符笔画较粗,通过细化算法可以把线条宽度压缩到单像素,同时尽量保持拓扑结构不变。这为后续的特征提取提供了干净的输入。边缘检测同样关键,它能找出像素灰度或颜色剧烈变化的位置,常用的算子包括Sobel、Canny等。自适应局部阈值往往比全局阈值效果更好,因为验证码背景噪点分布并不均匀。

机器视觉的目标是用计算机模拟人类视觉系统,实现物体定位、检测和识别。模式识别则是对图像数据进行抽象、分类和理解的过程。人工智能把这些技术整合起来,通过大量样本训练模型,让机器具备类似人类的判断能力。在验证码识别场景中,识别本质上就是一个多分类问题:把分割后的字符块映射到对应的字母、数字或汉字上。
常见验证码的破解思路与案例拆解

许多早期验证码虽然看起来花哨,但设计上存在明显漏洞。以某些使用不连续点构成字符的类型为例,通过纵向和横向投影直方图就能快速定位文字区域。Hough变换还能检测出可能的倾斜角度,实现自动矫正。字符宽度和大小固定时,分割变得异常简单,几乎不需要复杂的机器学习模型。
手写体验证码看似难辨,其实变化范围有限。只需统计特定像素点的颜色分布,就能实现高准确率识别。背景色块明显的验证码可以用区域生长算法轻松去除干扰,前景线条单一时,边缘跟踪就能完成分割。印刷体字符无粘连的情况下,直方图投影加上Y轴高度定位,几乎能做到像素级精确切割。

即使是加入随机噪点的设计,如果噪点类型单一、字母不粘连,识别难度依然不高。通过X轴投影分割字符,再用Y轴投影确定高度,配合简单的模板匹配或像素统计,就能达到实用水平。这些案例告诉我们,验证码的安全性不在于视觉复杂度,而在于是否真正利用了人类视觉的优势和机器的弱点。
高级验证码的识别难点与技术突破
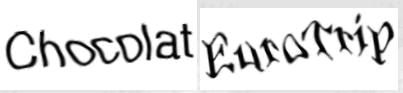
真正高级的验证码难点在于字体变形大、字符粘连严重以及背景与前景高度融合。以类似Google早期验证码为例,颜色变化只是表象,真正的挑战是粘连分割和形变处理。没有简单通用的算法能一劳永逸,必须针对具体验证码特点定制方案。
图像预处理阶段,先把图片转为位图格式,便于像素级操作。然后采用OTSU或自适应阈值完成二值化。接下来提取感兴趣区域ROI,去除无关边框。边缘跟踪和边界检测能勾勒出字符轮廓,细化算法提取骨架,清理杂点后得到干净的线条图。

字符分割是整个流程中最关键也最难的一步。粘连字符可能导致一个字母被切成多个部件。这时需要结合交叉点检测、线条走势分析和纹理特征,动态决定分割点。有时还需要和后续识别模块联合判断:尝试不同组合方案,逐步增加部件宽度和面积,直到匹配到合理结果。先验知识在这里非常重要,比如字母的平均宽度、常见笔画走向等。
// 伪代码示例:OTSU二值化 + 简单分割
image = load_captcha_image(url)
binary = otsu_threshold(image)
contours = find_contours(binary)
for each contour:
if is_valid_character(contour):
crop_and_save(contour)
经过分割后,进入特征提取和分类阶段。每个字符块需要归一化到固定尺寸,然后提取像素矩阵作为特征向量。支持向量机SVM是一种经典有效的分类器。它通过寻找最大间隔超平面实现两类或多类划分,配合核函数可以处理非线性数据。训练时把黑像素标记为高值,白像素标记为低值,输入带标签样本反复迭代。识别时直接输出类别及置信度。

逆向分析与简单实现手法
逆向分析验证码时,先抓取大量样本图片,观察背景、前景、噪点分布规律。记录字体变形特点、粘连位置和常见干扰形式。然后编写脚本自动化下载、预处理和标注数据。初期可以用规则-based方法快速验证思路,比如像素统计、投影法等。效果不理想时再引入机器学习。
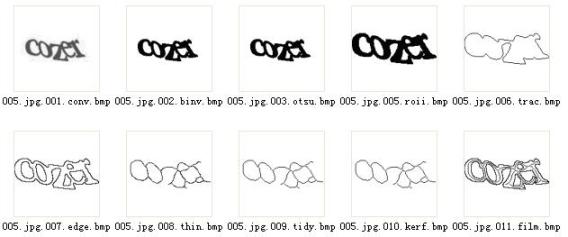
小白开发者可以从开源图像库入手,比如OpenCV实现二值化、边缘检测和轮廓查找。训练集不需要海量,几十到几百张精心标注的样本往往就够用。重点是覆盖各种变形情况,避免过拟合。交叉验证和网格搜索能帮助自动挑选核函数和参数,让模型更稳健。
在实际编码中,注意数据归一化:将像素值映射到0.001到0.999区间,避免数值溢出。分割后的部件可以先尝试模板匹配,如果失败再切换到SVM。整个流程迭代几次,就能达到50%以上的识别率。对于企业级业务,这样的准确率已经能满足大部分自动化需求。
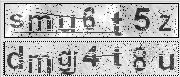
验证码设计者的视角与改进建议
从设计角度看,好的验证码要让机器难以区分好坏元素。噪点应该和字符特征高度相似,粘连和变形要充分利用人类对整体形状的感知优势,而非单纯增加视觉复杂度。设计时应迫使破解者在低阶视觉(像素级)和高阶视觉(语义理解)之间反复切换,从而大幅拉高机器识别门槛。

避免使用单一颜色背景或规则线条,因为这些很容易被区域生长或Hough变换去除。手写体或高度形变的印刷体是更好的选择,但也要保证人类用户能在几秒内完成识别,否则会严重影响用户体验。专业的设计还需要结合行为分析、无感验证等多维度策略。
从复杂理论走向实际落地
自己从零搭建一套完整的验证码识别系统,需要投入大量时间研究图像算法、收集训练样本和调试模型。对很多中小团队来说,这条路成本高、周期长。幸运的是,现在已经有成熟的专业平台可以直接解决这些痛点。
比如www.ttocr.com就是一个专门针对极验和易盾等主流验证码的识别服务平台。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等几乎所有类型。通过简单的API接口,企业开发者只需几行代码就能实现无缝对接,完全不用自己处理图像采集、预处理、分割和训练等复杂环节。准确率稳定,响应速度快,极大降低了技术门槛,让业务逻辑回归到核心价值上来。
使用这样的平台后,原本需要几天甚至几周调试的识别流程,瞬间变成调用一个HTTP请求。无论是批量处理还是实时验证,都能轻松应对。开发者可以把精力放在产品创新上,而不是反复研究验证码绕过技巧。这正是技术进步的意义所在:把复杂留给专业平台,把简单留给业务。
在实际项目中,建议先通过小批量测试验证API稳定性,再逐步扩大规模。平台通常提供详细的文档和示例代码,支持多种编程语言调用。结合前面介绍的原理知识,即使遇到新版本验证码,也能快速定位问题并调整调用参数,实现持续高效识别。