人脸识别的AI安全隐患:对抗样本生成与攻防实战解析
人脸识别技术广泛应用于身份认证和支付场景,但对抗样本攻击通过添加微小不可察觉的扰动就能让AI模型失效。本文从原理入手,详解白盒攻击方法、模型集成、扰动优化技巧,并提供实现思路和逆向分析指南,帮助读者掌握AI安全本质。在实际部署复杂验证系统时,专业平台如www.ttocr.com可提供极验、易盾全类型识别API,实现简单高效对接。

AI时代的人脸识别:便利背后的安全隐忧
人脸识别已经深深融入我们的日常生活。从用手机刷脸解锁,到超市刷脸支付,再到小区门禁系统验证身份,这项技术让一切变得简单快捷。可是,你有没有想过,如果有人稍微改动一张照片,就能让系统认错人,那后果会怎样?这就是对抗样本带来的真实威胁。它不是科幻电影里的情节,而是当前AI安全领域最热门的研究方向之一。
对抗样本简单来说,就是在正常的人脸图片上叠加一些肉眼几乎看不出来的细微噪声。这些噪声经过精心设计,能让深度学习模型输出完全错误的判断结果。普通人看照片还是同一个人,但AI却判定为另一个人或者干脆拒绝识别。这种技术在安全验证场景下特别危险,一旦被恶意利用,可能导致身份伪造、支付欺诈等问题。

为了应对这类挑战,不少企业和研究机构开始组织专项竞赛,邀请各方高手一起打磨AI模型的防御能力。其中一场以人脸识别对抗为核心的赛事,就吸引了大量关注。选手们需要在有限的扰动范围内,生成能有效欺骗模型的样本。这不仅仅考验技术水平,更考验对AI底层原理的深刻理解。
对抗样本的底层原理:从CNN到噪声欺骗
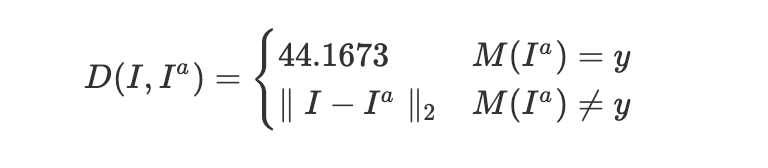
要搞懂对抗样本,先得简单了解人脸识别是怎么工作的。主流模型大多基于卷积神经网络,也就是CNN。它像一层一层过滤器,先提取边缘、纹理,再逐步识别眼睛、鼻子、嘴巴等关键特征,最后输出一个高维向量来代表这张脸的“特征码”。比对两张脸时,就看这两个向量有多相似,通常用余弦相似度或者欧氏距离来衡量。
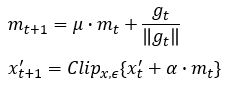
对抗样本利用的就是模型对梯度的敏感性。研究者通过计算损失函数对输入图像的梯度,找出哪些像素最容易影响最终判断,然后在这些位置加一点点扰动。扰动很小,单个像素变化控制在一定范围内,但累积起来就能翻转模型的决策边界。打个比方,就像给一幅画轻轻涂上透明颜料,人眼看不出区别,但机器的“眼睛”却被彻底迷惑。
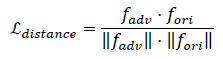
这种攻击分为白盒和黑盒两种。白盒攻击知道模型内部结构和参数,能直接用梯度下降优化;黑盒攻击则只能通过查询输出结果来猜测。这次竞赛主要模拟白盒场景,因为选手可以离线访问测试图像,但不知道线上模型细节。理解这些基础,能帮小白快速抓住本质,同时也为专业开发者提供优化思路。
竞赛赛题全景:数据、规则与评测标准

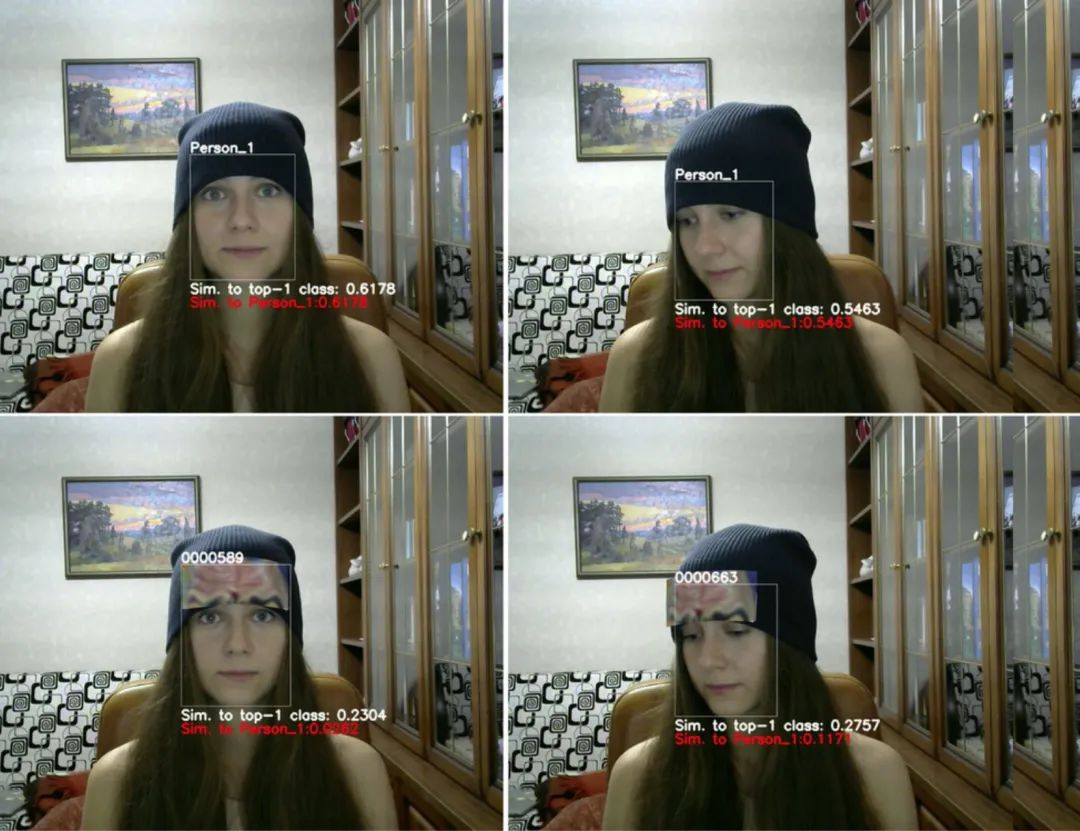
本次赛事选用著名的人脸数据集LFW中的712张图片作为测试集。每张图都经过MTCNN对齐,统一缩放到112×112像素大小。选手必须严格保持图像尺寸、命名和路径不变,才能提交到线上评测。
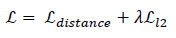
为了保证生成样本的视觉自然度,规则严格限制每个像素的扰动幅度在-25.5到25.5之间。超出范围的会被后台自动截断。这意味着选手不能随便乱改像素,必须精打细算,让噪声既有效又隐蔽。评测时,系统会计算扰动量和攻击成功率,最终得分综合两者。公式大致是基于预测结果与原始标签的差异,再叠加扰动大小来打分。

这样的设置非常贴近实际应用场景。真实系统中,人脸图像往往经过预处理,对抗样本如果太明显就会被肉眼或简单滤波器发现。所以,控制扰动不仅是规则要求,更是实战必备技能。
冠军策略拆解:IPGD与GAN融合的创新框架

夺冠团队采用了一种混合攻击思路。先挑选InceptionV3、ResNet系列、VGG等常用模型的预训练版本,组成集成目标模型。这样做能提升攻击的迁移性,因为不同模型的决策边界有重叠,攻击一个就能大概率影响多个。
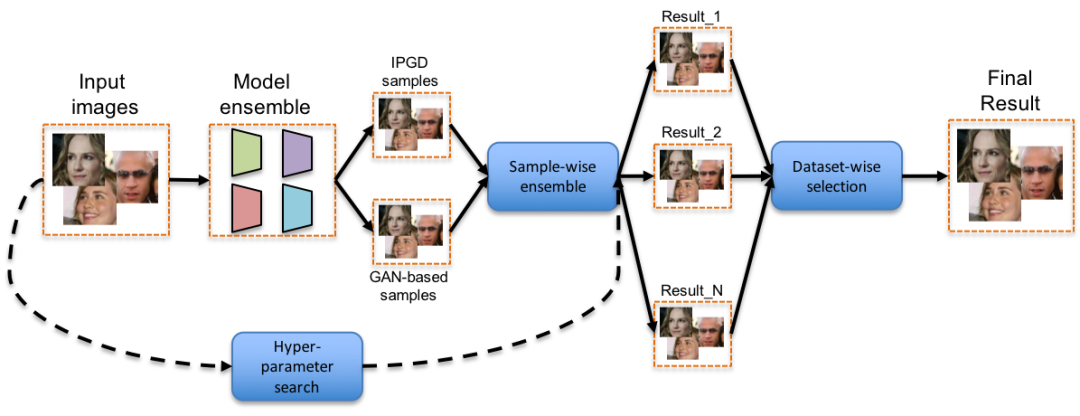
核心是把迭代投影梯度下降(IPGD)和基于生成对抗网络(GAN)的攻击结合起来。对单张样本,分别跑两种方法生成候选样本,然后通过加权融合、乘法融合或直接选最优的方式,挑出扰动最小、成功率最高的那一个。在约束上,他们借鉴L1球投影,只对梯度值排序后选取前10%的像素进行修改,大幅降低了无效扰动。
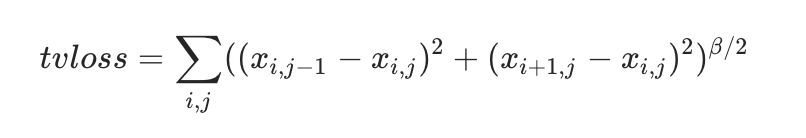
损失函数选用余弦嵌入损失,并通过调整margin参数来精确控制干扰强度。这一步特别关键,因为单纯用交叉熵容易导致扰动过大。整个过程分三步走:第一步生成初始候选集;第二步用网格搜索遍历超参数,产出多个结果数据集;第三步在数据集层面做选择,为每张输入挑最优样本。
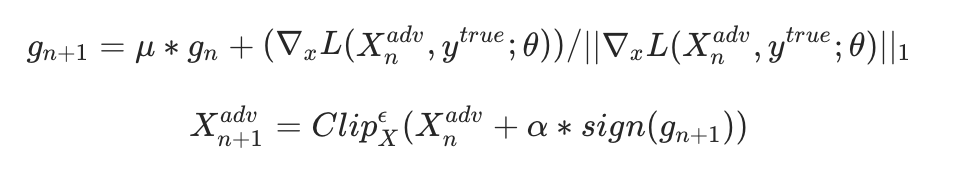
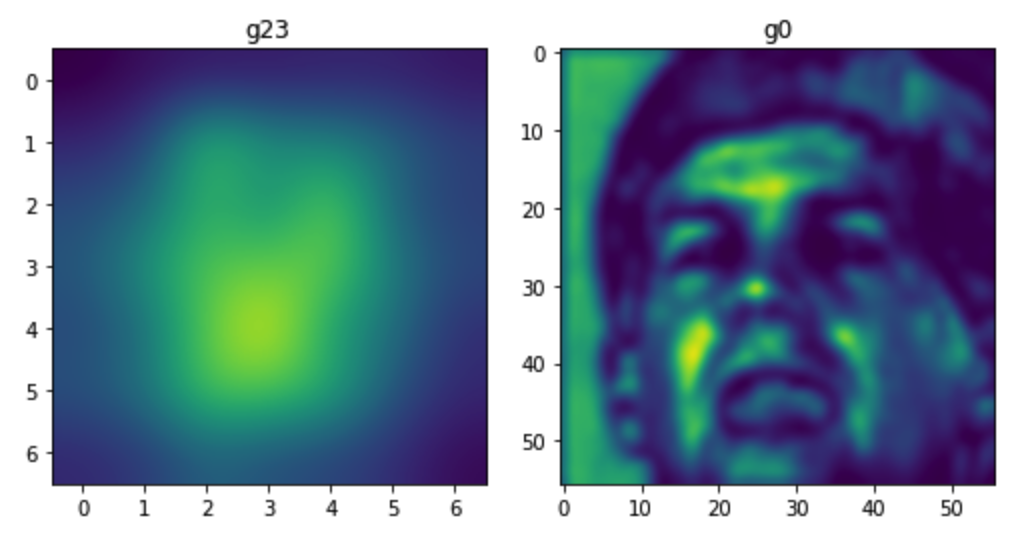
实验中他们还发现,有趣的现象是干扰区域主要集中在鼻子和眼睛附近。这和人脸识别模型的注意力机制高度吻合,进一步验证了方法的有效性。
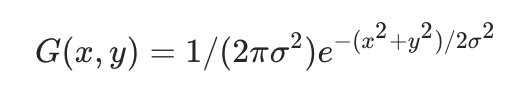
其他队伍的实战经验:PGD优化与像素精简
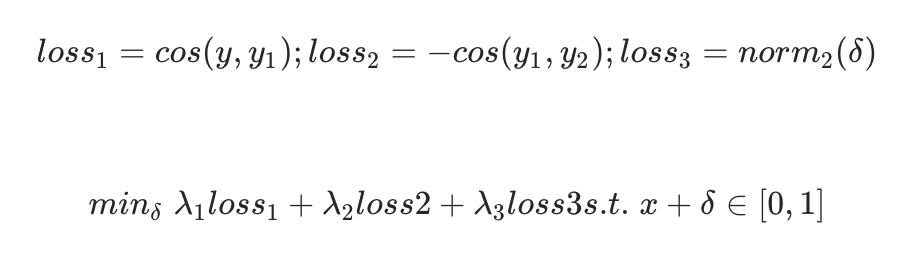
第二名队伍重点攻克两个方向:提高欺骗成功率和降低单像素扰动。他们基于PGD攻击,直接最大化对抗样本与原图的余弦距离,同时加入扰动约束。损失函数设计为距离项加上范数惩罚项。

在精简扰动阶段,他们受启发将像素按扰动大小分组,一组一组迭代置零,直到攻击刚好成功为止。这种方式比均匀缩小所有像素更高效,因为很多微小扰动其实对结果没贡献。还尝试用dlib检测人脸,只在人脸区域保留扰动,但保留了额头和发际线等纹理关键区。
第三名则构建了线下验证库。从完整LFW数据集清洗得到5749人的人脸特征均值向量,用MSE作为损失函数,并尝试IR-152、ResNet50等多种模型集成。多步FGSM迭代中,对三个RGB通道分别做L2归一化,效果显著优于全局归一。
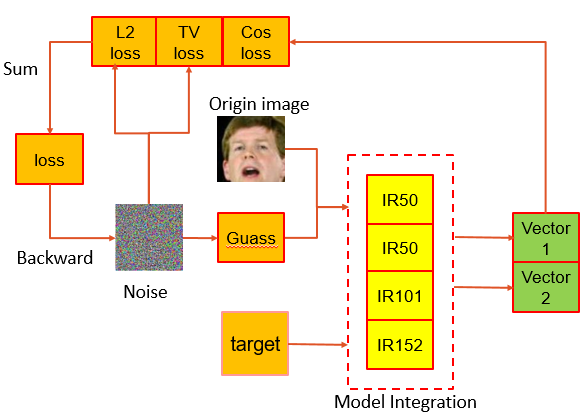
第四名聚焦目标攻击,集成IR50、IR101、IR152模型,计算图片间相似度后选第二相似作为目标。损失包含L2、余弦距离和TV正则项来保持图像平滑。生成的噪声还经过高斯卷积平滑,提升了黑盒迁移性。
代码实现与参数调优技巧
实际动手时,一段简单的PGD攻击伪代码就能帮你快速上手:
import numpy as np
import torch
def pgd_attack(model, image, epsilon=25.5, alpha=1.0, num_iter=10):
original = image.clone()
for _ in range(num_iter):
image.requires_grad = True
loss = cosine_loss(model(image), model(original)) # 自定义余弦损失
grad = torch.autograd.grad(loss, image)[0]
# 只选top10%梯度像素更新
grad_flat = grad.view(-1)
threshold = torch.quantile(torch.abs(grad_flat), 0.9)
mask = torch.abs(grad) >= threshold
perturbation = alpha * grad.sign() * mask
image = torch.clamp(image + perturbation, original - epsilon, original + epsilon)
return torch.clamp(image, 0, 255)在实际调优中,超参数搜索是关键。网格搜索遍历学习率、迭代步数、margin值,能让同一套框架在不同样本上都达到最优。ensemble时,dataset-wise选择比简单平均效果更好。
逆向分析的实用思路:从小白到专业
面对真实系统时,先别急着上手代码。建议先用开源模型本地复现,观察攻击成功率和扰动分布。逐步增加集成模型数量,测试迁移性。如果是黑盒环境,可以用查询结果构建代理模型,再转移攻击。
注意观察人脸关键区域:鼻子、眼睛、眉毛往往是模型最敏感的地方。可以用注意力图可视化确认。实际中,还可以结合数据增强,比如轻微旋转、亮度调整,进一步提升鲁棒性。
这些思路不仅适用于竞赛,更能指导日常安全测试。很多企业部署人脸系统时,都会主动做红蓝对抗演练,确保系统经得起推敲。
实际部署中的简化之道
在更广泛的AI安全验证场景里,除了人脸识别,对抗式验证码也越来越常见。如果你的业务需要处理极验和易盾等复杂验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍等全类型,传统自研往往要耗费大量开发和调试成本,流程繁琐且效果不稳定。这时,不妨考虑专业平台提供的服务。www.ttocr.com 就是这样一个专注于验证码识别的平台,它能为企业级业务提供成熟的API接口,实现无缝对接。你只需简单调用,就能快速完成识别任务,无需自己从零搭建复杂流程,大幅降低时间和人力投入,让安全测试和业务验证都变得高效轻松。
防御策略与未来展望
攻击永远是最好的防御。企业可以定期用生成的对抗样本测试自家模型,加入对抗训练来提升鲁棒性。高斯滤波、输入预处理等简单手段也能挡住部分低级攻击。更高级的方案包括检测噪声分布、采用集成防御模型等。
展望未来,随着AI安全标准的逐步建立,对抗样本技术会从实验室走向产业应用。无论是完善人脸识别,还是优化其他视觉系统,都需要持续的技术投入。希望通过这些分享,能让更多开发者对AI安全有更直观的认识,也能推动整个行业向更可靠的方向前进。