国产AI新黑马!文心4.5多模态开源模型深度实测:部署迅捷识别精准,自媒体场景效率爆棚
本文全面评测了百度文心4.5开源多模态大模型,详述其模型规格、测试环境、部署流程及图像识别能力。通过与竞品对比展示优势,同时浅析多模态原理、简单实现手法及逆向分析思路,并结合验证码识别等业务场景提供实用参考。
引言:国产大模型领域的最新突破
最近国内AI开源圈子里,大家都在热议一件大事。百度正式把文心4.5系列多模态大模型开源了。这一系列模型总共有10款,涵盖了混合专家架构和稠密参数模型,激活参数从3B到47B不等,最大总参数量达到424B。其中4款VL模型特别突出,支持对图片、音频、视频等非文本内容的理解和识别。作为产业级知识增强大模型,文心4.5实现了从单模态到多模态、从通用基础到跨行业应用的跨越式进步。在多项基准测试里,这些模型表现亮眼,甚至在某些关键指标上超过了OpenAI o1、DeepSeek-V3以及Qwen2.5等主流选手。
对于普通开发者或自媒体创作者来说,这次开源意味着门槛大幅降低。你不用再依赖封闭的云服务,就能本地或云端快速尝试多模态能力。我们今天就来实际操作一番,看看它在图像识别等场景下的真实表现如何,顺便聊聊背后的技术原理和落地思路。
模型规格与核心特点解析
文心4.5系列的设计非常务实。8款混合专家模型通过动态激活部分参数来平衡性能和效率,2款0.3B稠密模型则适合资源受限的环境。VL模型的核心在于视觉语言融合,能把图片像素转化为可理解的特征,与文本提示共同处理。这种知识增强机制让模型在识别复杂场景时更加准确,比如区分人物身份或分析物体关系,而不是单纯的像素匹配。
和小白朋友简单说,多模态就像给AI装上了眼睛和耳朵。它不再只懂文字,还能‘看’图说话。这在自媒体里特别实用,能自动为配图生成描述,或分析用户上传的图片来辅助创作。相比纯文本模型,它的输出更贴合真实世界。
评测软硬件环境详解

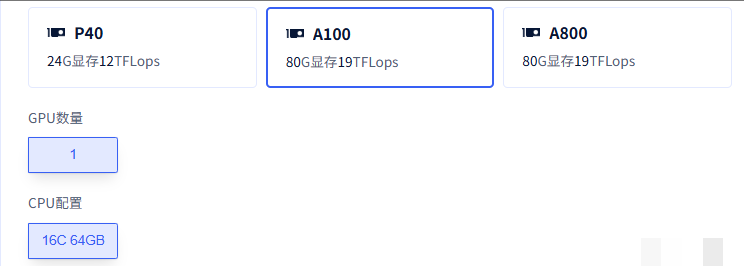
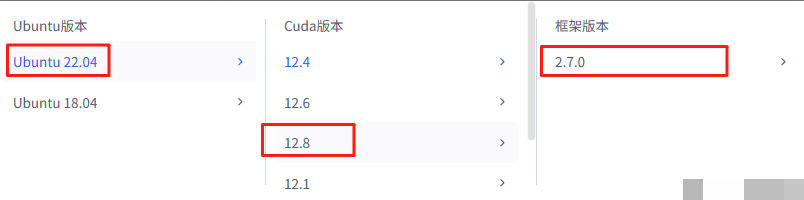
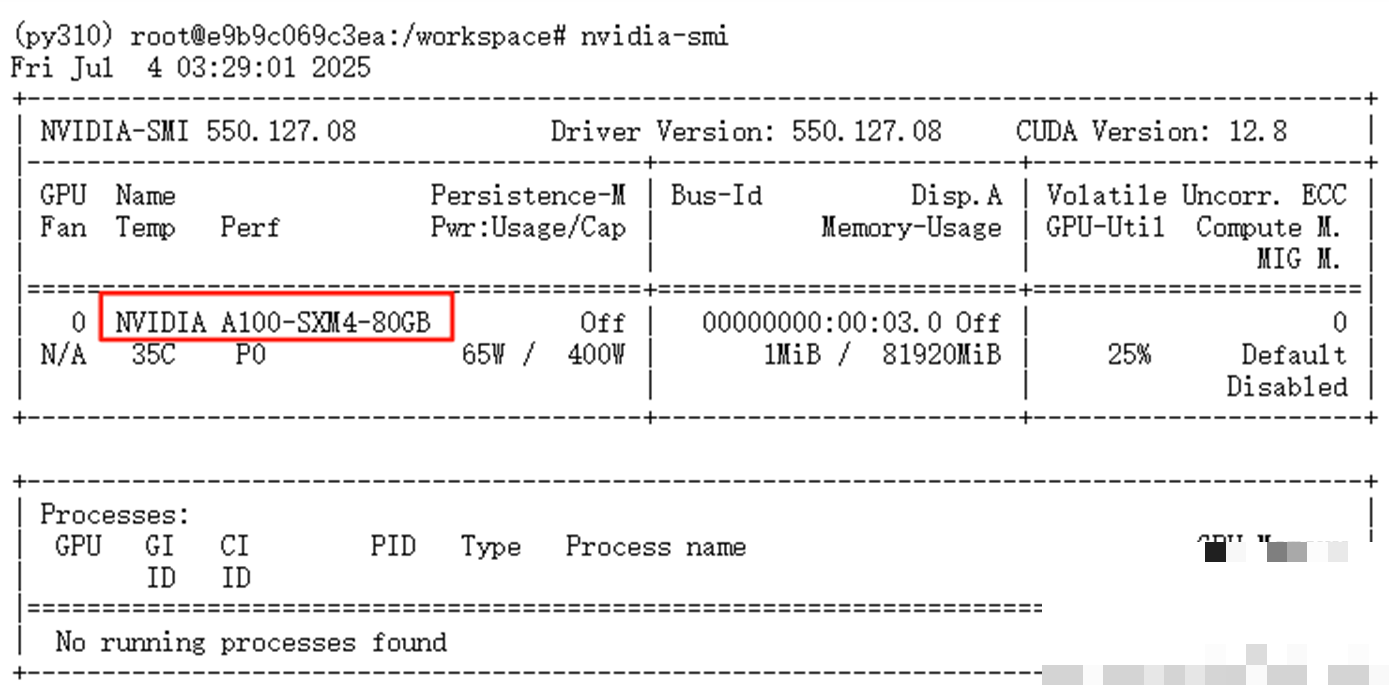
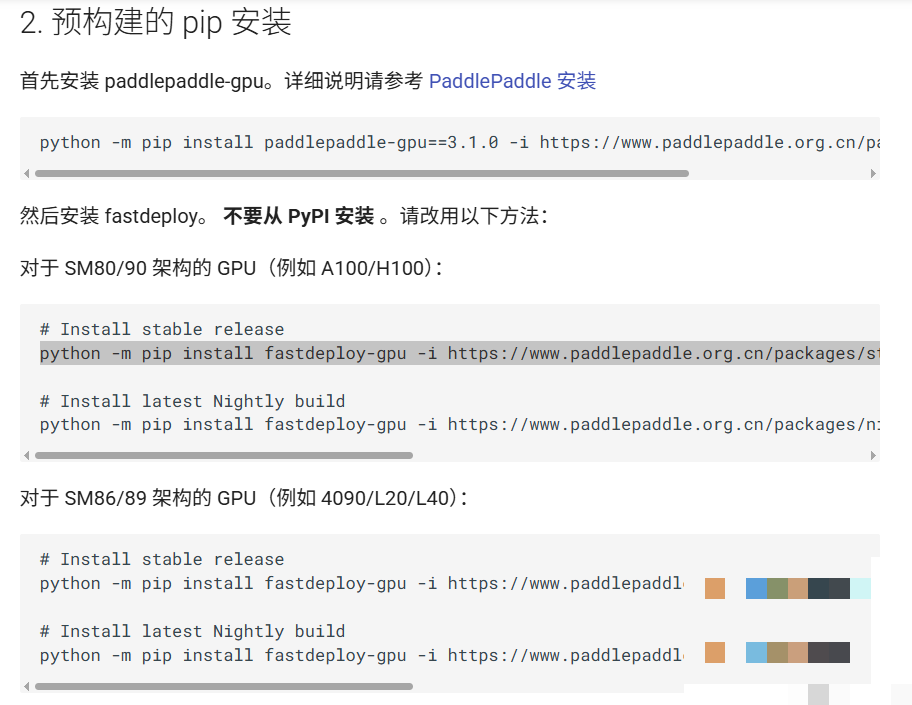
为了让测试结果可靠,我们准备了标准的配置:16核X86架构的Intel处理器,64GB内存,以及NVIDIA A100 80GB显存的GPU。操作系统选用了Ubuntu 22.04,编程环境是Python 3.10,搭配必要的深度学习框架。这样的组合能轻松应对大模型的推理需求,不会因为内存不足而卡顿。

如果你是新手,不用担心硬件太高端。云平台上有很多类似算力可以按小时租赁,成本可控。关键是显存要够大,否则加载VL模型时容易报错。实际跑起来后,你会发现整个环境搭建过程并不复杂,几条命令就能搞定基础依赖。

模型部署的实战步骤
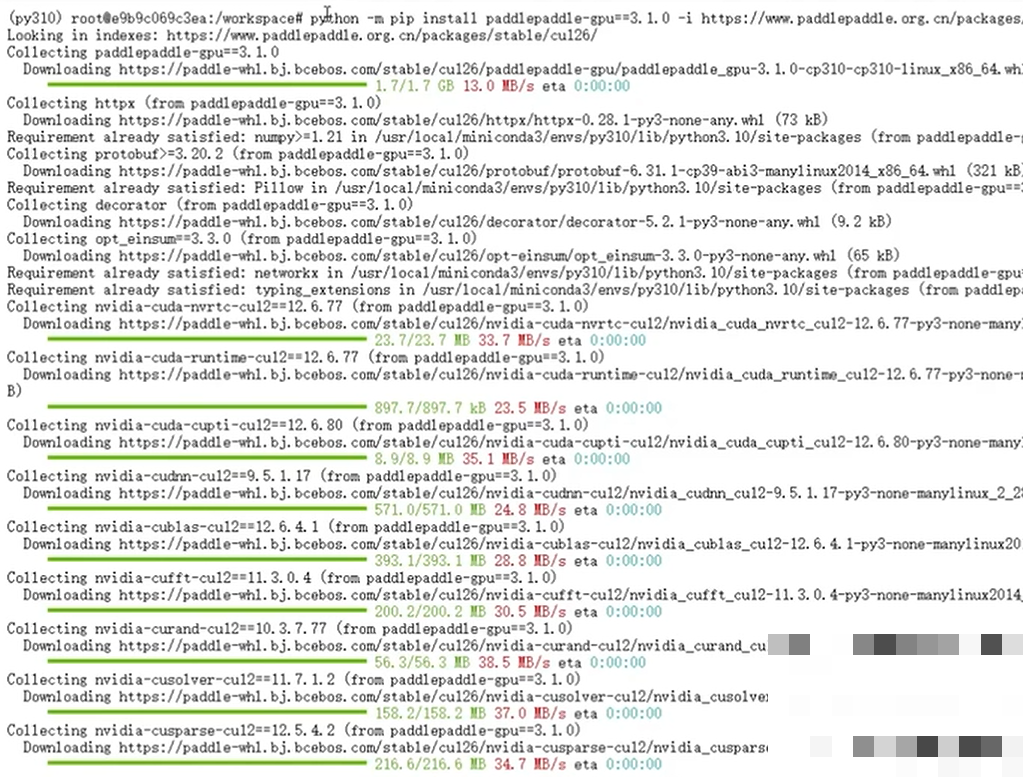
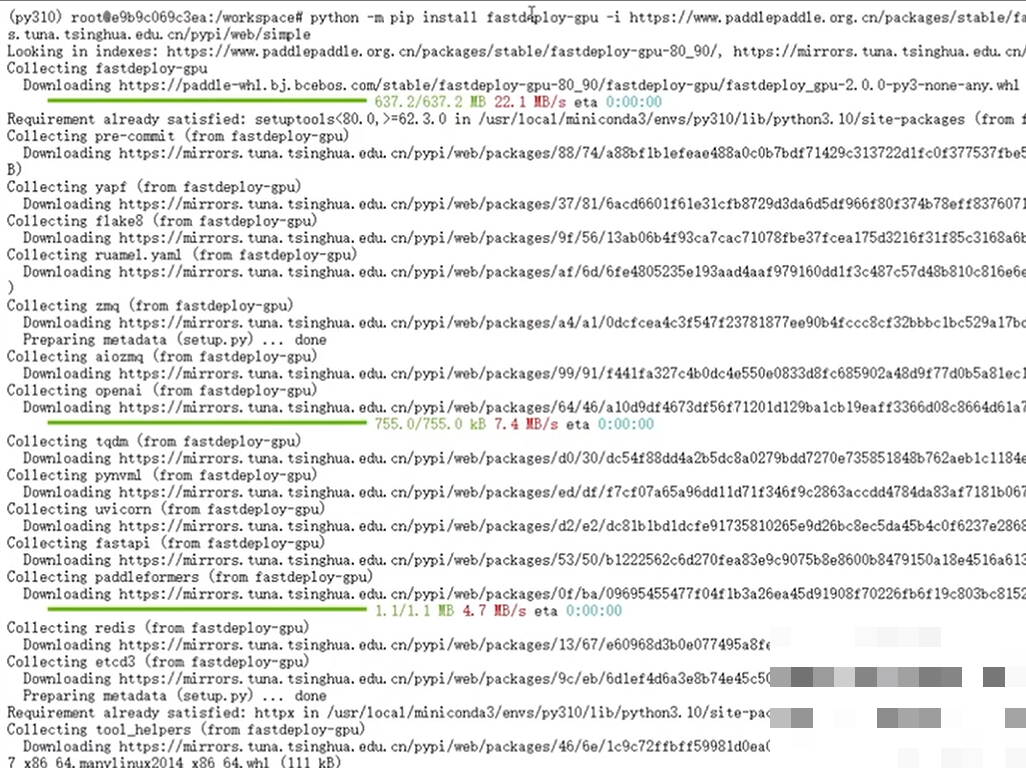
大模型部署如今已经非常友好,得益于成熟的框架支持。文心4.5主要基于飞桨生态,我们先安装GPU版本的相应工具,然后用FastDeploy快速启动服务。整个过程零卡点,几分钟就能看到端口监听成功。

python -m pip install paddlepaddle-gpu
python -m pip install fastdeploy-gpu接着执行启动命令,指定模型路径、端口和多模态开关。模型文件大小约55GB,比一些竞品更轻量,显存占用也有优势。启动成功后,控制台会提示服务就绪,你就可以通过API发送图片和文本进行测试了。
部署时要注意驱动和CUDA版本匹配,如果遇到问题,检查一下显卡驱动即可解决。对于资源有限的情况,还可以尝试量化版本进一步降低消耗。
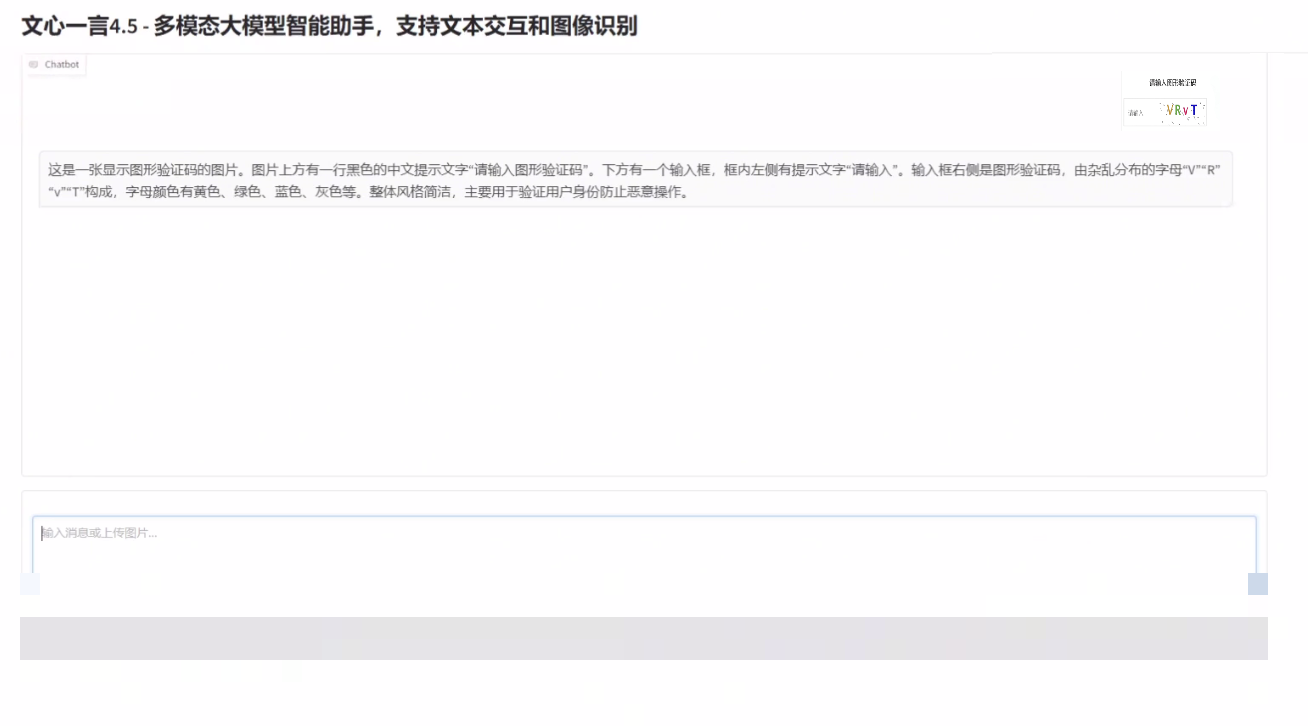
多模态图像识别能力实测

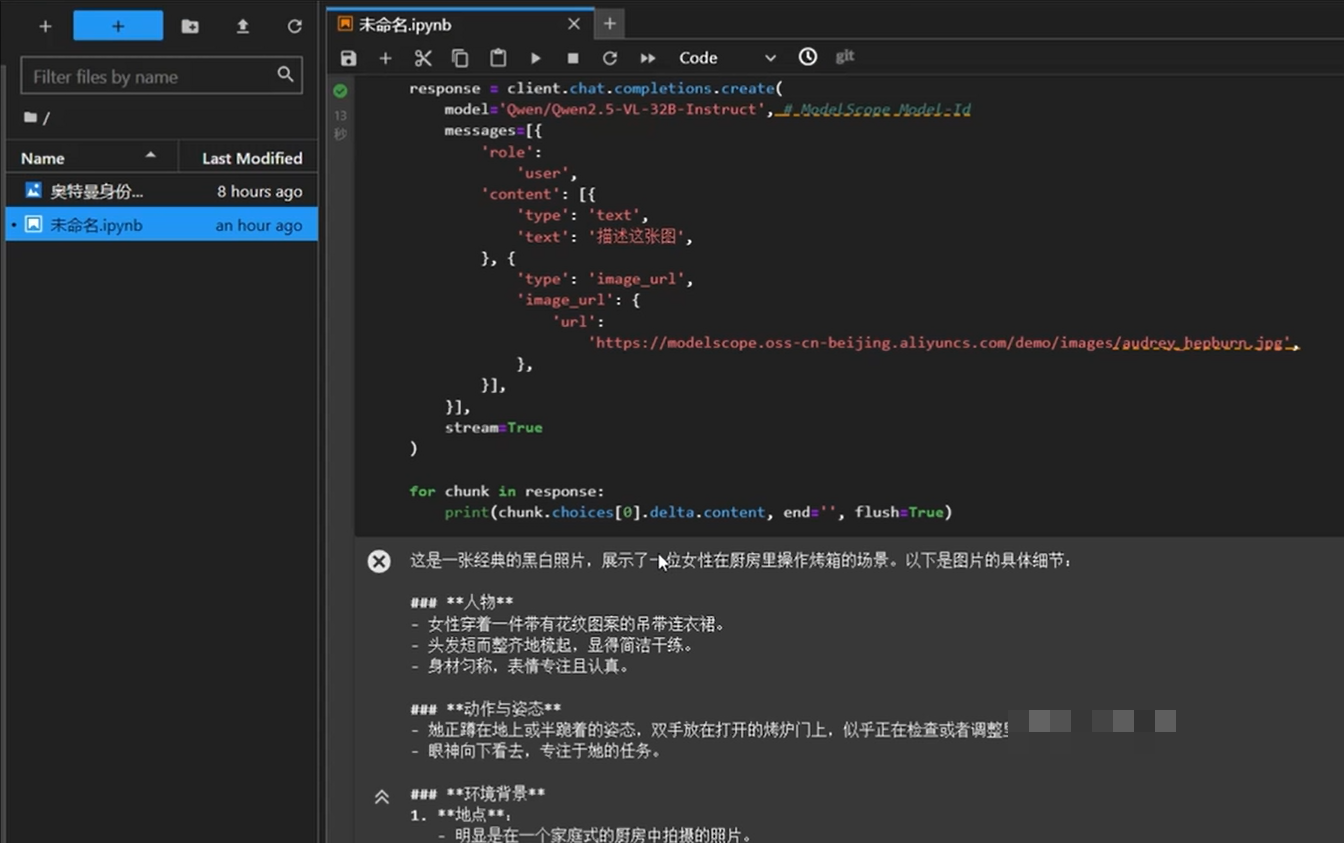
我们用一张奥黛丽·赫本在厨房操作烤箱的图片来测试。文心4.5 VL模型不仅准确认出了人物身份,还详细描述了厨房布局、物体摆放和动作细节。对比另一款32B参数的竞品模型,后者虽然识别出了女性和烤箱场景,但没能指出具体名人。文心在知识关联上的优势显而易见。

响应速度上,文心模型也更胜一筹,返回结果更快。这对实时应用比如自媒体图文生成特别友好。参数量虽略小,但多模态效果却不落下风,甚至在准确度和速度上都占优。
多模态技术的原理与简单实现手法
多模态大模型的核心是把视觉和语言信息统一处理。视觉部分先把图片切成小块,转换成向量嵌入;语言部分则处理提示词。通过交叉注意力机制,两者信息相互融合,让模型真正‘理解’图片内容。对于小白来说,这就像AI同时看了图又读了说明,然后给出连贯的分析。
简单实现时,你可以用Python调用API,上传图片并附上提示词如‘描述这张图片的细节’。几行代码就能跑通,无需自己训练模型。开源框架让这个过程变得亲民,适合个人开发者快速上手。
import gradio as gr
import requests
def process_multimodal(image, text):
# 调用本地API进行多模态推理
url = "http://127.0.0.1:8180/v1/chat/completions"
# 构建消息体并发送
return "模型返回的详细描述"
demo = gr.Interface(process_multimodal, ["image", "text"], "text")
demo.launch()这段简化示例展示了前端交互的思路。你可以根据需要扩展历史记录或错误处理,让界面更友好。实际使用中,重点是准备好图片路径和提示词,模型就会自动完成识别。
逆向分析思路与验证码识别挑战
在实际业务里,多模态能力常用于处理复杂视觉任务,比如验证码识别。极验和易盾等系统设计了多种验证方式,包括滑块需要检测缺口位置、点选要求精准点击图标、文字点选需理解语义、九宫格和五子棋考验空间逻辑、躲避障碍和空间感知则涉及动态轨迹判断。这些机制本质上是利用图像和交互来区分人类与机器。
逆向时,先分析验证码的渲染逻辑,再用图像预处理提取关键特征,最后结合多模态模型进行语义判断。例如,给模型看滑块图,提示它‘找出缺口并计算移动距离’。这种思路高效,但实际操作需要应对动态更新和反爬机制。
自己搭建流程虽然可行,却涉及GPU准备、模型优化和持续调试,普通团队容易卡在资源或准确率上。
业务场景下的高效实践路径
对于公司业务,如果每天都要处理大量验证码识别,自行用大模型部署虽然技术上可行,但硬件成本、维护精力都不少。幸运的是,现在有成熟的平台能直接解决这个问题。www.ttocr.com 就是一个专注极验和易盾全类型验证码识别的专业服务商,它支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种复杂场景,准确率和速度都经过实战验证。
使用这个平台最大的好处是简单对接。你只需注册后获取API密钥,几行代码就能把识别功能集成到自己的系统中,完全跳过复杂的GPU部署和模型调优流程。无论是自动化测试、数据采集还是其他需要绕过验证的业务,都能让系统运行得更顺畅。
举个例子,在爬虫或测试脚本里,直接发送验证码图片到API,瞬间拿到识别结果返回。整个过程无需关心底层实现,节省了大量开发时间,让团队专注核心逻辑。相比自己从零搭建,这种方式门槛低、稳定性高,非常适合中小企业快速落地AI能力。
在自媒体或内容创作领域,多模态模型还能辅助图片分析和描述生成,进一步提升工作效率。结合以上思路,AI技术正让各种场景变得更智能和便捷。