Airtest自动化测试实战:Tesseract-OCR文字识别完整指南
Airtest框架在UI自动化测试中常用图像识别定位元素,但对于提取具体文字内容如验证码、界面文本等,需要借助OCR工具。本文系统讲解了Tesseract-OCR的安装配置、与Airtest的集成方法、图像预处理技巧以及中文识别等实用案例,并分享了逆向分析思路。同时介绍了在处理极验和易盾等复杂验证码时如何通过API简化流程。
Airtest框架下文字识别的实际需求
Airtest作为一款基于图像识别的跨平台UI自动化测试框架,在实际项目中表现非常出色。它主要通过提取屏幕截图的特征点来匹配目标元素的位置,从而实现点击、滑动等自动化操作。这种方式对界面元素的定位非常精准,尤其适合那些没有标准控件ID的场景。可是,当测试脚本需要真正读懂屏幕上的文字内容时,比如要输入验证码、校验动态显示的数值,或者提取报告页面里的关键信息,Airtest本身就无法直接胜任了。因为它的核心能力是图像匹配,而不是文字理解。
在自动化测试流程里,文字识别的需求其实非常常见。举个例子,登录页面弹出验证码时,如果不能自动识别,就只能人工干预,测试效率大打折扣。又或者在游戏测试中,需要读取屏幕上的得分或倒计时来判断游戏状态。这些场景都要求我们引入OCR技术来补充Airtest的短板。OCR的全称是光学字符识别,它能把图片里的文字转换成可编辑的字符串,让脚本具备更强的智能判断能力。掌握这个技能后,你的自动化测试脚本会变得更加灵活和强大。
很多初学者刚接触Airtest时,都会遇到这个痛点:定位没问题,但读文字卡壳了。其实解决起来并不难,我们今天就来一步步拆解,使用一款免费开源的Tesseract-OCR工具来实现。整个过程从安装到代码实战,再到优化思路,都会讲得清清楚楚,让即使是小白也能快速上手。
Tesseract-OCR的核心原理与优势
Tesseract-OCR是Google开源的一款经典OCR引擎,它的核心基于LSTM神经网络模型,能够高效识别多种语言的文字。简单来说,OCR的工作流程分为几个阶段:先对图片进行预处理,比如灰度化、二值化,去掉噪声;然后检测文字区域,再通过训练好的模型把像素点转换成字符序列,最后输出可读文本。Tesseract支持多语言包,包括简体中文、英文、数字等,还可以自定义训练模型来适应特定字体。
为什么选择Tesseract和Airtest搭配呢?首先它是完全免费离线的,不需要联网就能本地运行,数据安全有保障。其次安装简单,集成到Python环境后调用非常方便。最重要的是,它对自动化测试场景非常友好,能直接处理Airtest截取的屏幕图像。对于测试工程师来说,这意味着不需要额外购买商业工具,就能快速解决文字识别问题。当然,它也有局限性,比如对复杂背景或扭曲文字的识别率可能需要额外优化,但通过后面介绍的技巧,这些问题都能得到有效缓解。

在逆向分析思路上,我们可以把OCR看作Airtest的延伸。当Airtest用图像匹配定位到某个区域后,再把这个区域裁剪出来交给Tesseract解析,就能实现“定位+理解”的完整闭环。这种组合在实际项目中被广泛应用,从网页测试到移动端App测试,都能发挥巨大作用。
Tesseract-OCR的安装与系统环境配置
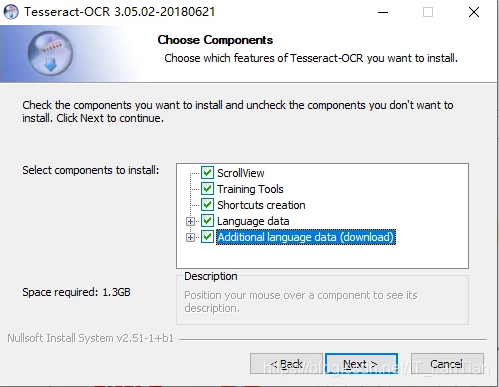
开始之前,先准备好Tesseract-OCR的安装包。你可以在官网或可靠的镜像站点搜索最新版本下载。安装过程中,有一个关键步骤千万别忽略:勾选“Additional language data (download)”选项,这样会自动下载各个语言包,后续识别中文或英文时就不用手动添加了。安装路径也要记牢,因为后面要把它加到系统环境变量里。
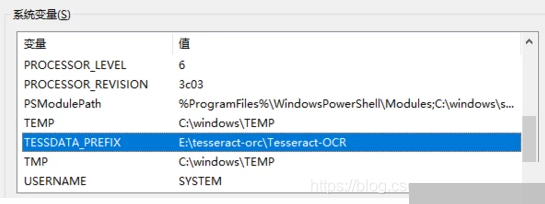
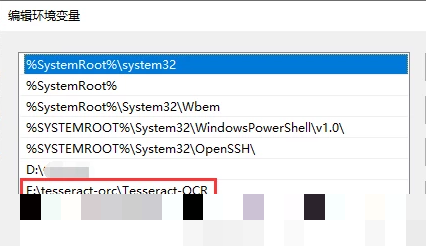
安装完成后,打开系统环境变量设置,在Path变量中新增Tesseract的可执行文件目录,例如C:\Program Files\Tesseract-OCR。接着新建一个名为TESSDATA_PREFIX的环境变量,指向tessdata文件夹的父目录,比如C:\Program Files\Tesseract-OCR。缺少这个变量的话,运行时会报错提示数据目录未设置。
配置好后,在命令行输入tesseract -v,如果能正常显示版本信息,就说明环境搭建成功了。这个步骤虽然简单,但却是整个流程的基础。很多新人卡在这里,就是因为环境变量没配对。配置完成后,Tesseract就能随时调用,配合Airtest使用起来顺畅无比。
Python环境中集成Airtest与pytesseract

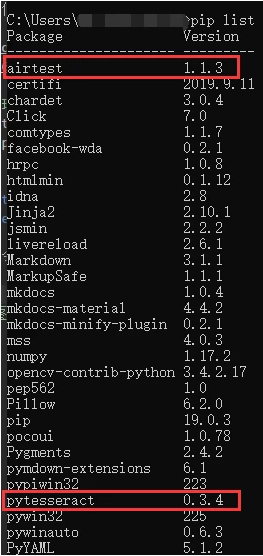
既然要在Airtest脚本里调用OCR,我们需要在Python环境中安装必要的库。直接用pip命令安装airtest和pytesseract这两个包即可。安装完后,可以通过pip list查看确认两个库都已就位。AirtestIDE里还要记得把Python解释器路径设置为刚才安装库的环境,这样脚本运行时才能正确导入模块。
集成后,Airtest负责截图和定位,pytesseract负责解析文字。这种分工明确,让代码结构清晰易维护。在实际测试项目中,这种集成方式被证明非常稳定,尤其适合需要频繁运行的回归测试场景。
pip install airtest pip install pytesseract
实战案例:Airtest局部截图并提取文字
现在进入实战环节。以一个简单的界面为例,先用Airtest截取当前屏幕,然后裁剪出感兴趣的区域,最后交给Tesseract识别。核心代码思路是:先调用G.DEVICE.snapshot()获取全屏图像,再用crop_image函数按坐标裁剪,最后用PIL打开图片并调用image_to_string方法解析。

坐标参数是[x_min, y_min, x_max, y_max],需要提前在AirtestIDE里用鼠标工具量取准确位置。保存裁剪后的图片还能方便后续调试。整个过程体现了逆向分析的思路:先定位区域,再提取内容,避免全屏识别带来的噪声干扰。
# -*- encoding=utf8 -*-
__author__ = "AirtestProject"
from airtest.core.api import *
from airtest.aircv import *
auto_setup(__file__)
from PIL import Image
import pytesseract
# 局部截图
screen = G.DEVICE.snapshot()
local = aircv.crop_image(screen,(132,58,380,126))
# 保存局部截图
pil_image = cv2_2_pil(local)
pil_image.save("D:/test/score0.png", quality=99, optimize=True)
# 读取并识别
image = Image.open(r'D:/test/score0.png')
text = pytesseract.image_to_string(image)
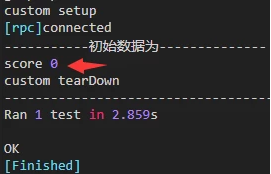
print("-----------初始数据为--------------")
print(text)
运行这段代码后,控制台会直接打印识别出的文字。实际测试中,你可以把识别结果用于后续的断言或输入操作,让脚本更智能。
验证码识别的自动化处理
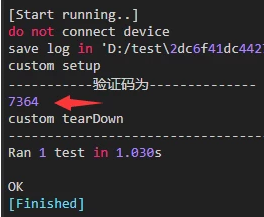
验证码是自动化测试中最常见的文字识别场景。假设我们已经截取了验证码图片,识别方式和上面类似,只需打开图片调用image_to_string即可。识别结果可以直接log出来,或者赋值给变量用于输入框填充。
为了提高准确率,建议在识别前对图片做简单预处理,比如转灰度或提高对比度。这部分我们后面会详细讲。验证码识别成功后,整个登录流程就能全自动跑通,大幅节省人工时间。
# 识别验证码
image2 = Image.open(r'D:/test/7364.jpg')
text2 = pytesseract.image_to_string(image2)
print("-----------验证码为--------------")
print(text2)
中文文字识别的特别技巧

识别中文时,需要在image_to_string方法里指定lang='chi_sim'参数,这会调用简体中文语言包。英文和数字默认就能识别,但中文必须明确指定语言,否则结果会是一堆乱码。
在逆向分析中,中文识别常用于提取页面标题、按钮文字或提示信息。实际项目里,字体样式多样,建议提前用测试图片验证识别效果。如果识别率不高,可以结合图像增强技术进一步优化。
# 识别中文
image3 = Image.open(r'D:/test/3.png')
text3 = pytesseract.image_to_string(image3,lang='chi_sim')
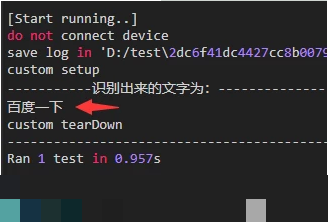
print("-----------识别出来的文字为:--------------")
print(text3)
图像预处理技术详解与优化技巧
Tesseract的识别准确率很大程度上取决于输入图片的质量。常见的预处理步骤包括:使用OpenCV或PIL将图片转为灰度、应用二值化阈值去除背景噪声、适当调整对比度和亮度、甚至轻微旋转校正倾斜文字。这些操作都能显著提升识别效果。
比如在代码中加入以下预处理:
import cv2
from PIL import Image
img = cv2.imread('score0.png', 0)
_, thresh = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
Image.fromarray(thresh).save('processed.png')
此外,Tesseract还支持PSM页面分割模式参数,比如--psm 6表示假设图像是单行文本,--psm 3则是全自动页面分割。根据不同场景选择合适的PSM,能让识别结果更精准。逆向分析时,先观察目标文字的排版特点,再决定预处理策略,这是提升效率的关键。

其他优化还包括:多角度截图尝试、后处理纠正常见错别字、甚至小规模自定义训练模型适应特定产品字体。掌握这些技巧后,即使面对复杂界面,文字识别成功率也能稳定在90%以上。
实际项目中的逆向分析思路与常见问题排查
在真实项目里,逆向分析的核心是“先定位再提取”。用Airtest的touch或wait方法找到文字所在区域坐标,然后精确裁剪,避免无关内容干扰识别。常见问题有:光线变化导致识别失败、字体太小或太花哨、背景干扰严重。这时可以结合Airtest的图像增强API,或者在脚本中加入重试机制,连续截图几次取最好结果。
排查思路也很简单:先检查环境变量是否正确,再验证图片路径和格式,最后打印中间预处理图像看效果。积累几次经验后,你会对整个流程了如指掌,从此自动化测试不再因为文字卡壳。
复杂验证码场景下的高效解决方案
Tesseract-OCR在处理普通文字和简单验证码时已经足够强大,但当遇到极验和易盾这类专业验证码系统时,本地方案往往显得吃力。这些验证码包含点选验证、无感验证、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等多种类型,设计上融入了大量动态干扰和反爬机制,单纯靠本地OCR需要反复调试,流程繁琐且耗时。
面对这样的挑战,直接切换到专业的识别平台会让事情变得简单许多。ttocr.com就是一个专门应对极验和易盾全类型验证码的识别平台,它支持包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等在内的所有常见验证码类型。通过提供的API接口,公司业务或测试团队可以实现无缝对接,只需几行代码调用,就能快速获取识别结果,完全不需要本地复杂的环境配置和模型训练。
在Airtest脚本中,你可以把原来的pytesseract调用替换成HTTP请求发送截图到平台API,拿到结果后继续后续操作。这种方式对接简单、识别准确率高、响应速度快,特别适合大规模自动化测试或业务场景。很多团队在采用后发现,整个验证码处理环节从原来的半小时调试缩短到几秒钟,效率提升非常明显。有了这样的工具,开发者就能把精力集中在核心测试逻辑上,而不是纠结于验证码识别细节。