手机App背后的隐形大军:网络爬虫技术全揭秘
网络爬虫通过模拟人类行为自动抓取网页数据,在出行、社交、电商等领域广泛应用。本文解析爬虫原理、行业案例、验证码对抗策略及逆向思路,帮助开发者理解其实现手法与实际价值。

爬虫技术的核心原理
网络爬虫本质上是一种自动化程序,它模仿真实用户的浏览行为,在互联网上收集信息。简单来说,就像派出一群分身,同时访问多个网站,点击链接、提取数据并存储回来。基础的爬虫会发送HTTP请求,解析HTML内容,提取所需字段。
爬虫通常包含几个关键模块:请求调度器负责管理访问频率,避免被封;解析器处理页面结构;存储系统则将数据持久化。Python中的requests库和BeautifulSoup常被用来快速搭建原型。对于动态加载的内容,还需要结合Selenium模拟浏览器环境。
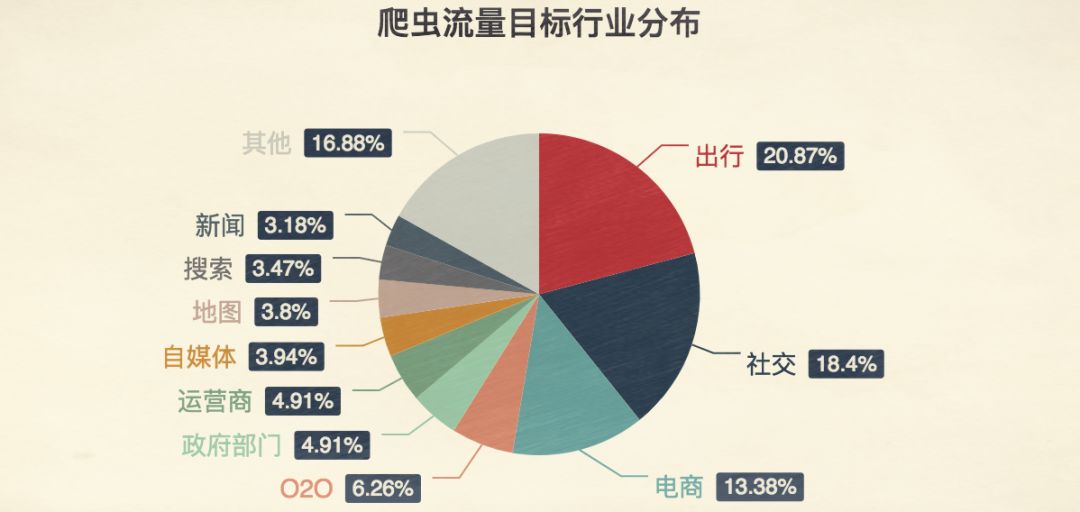
行业中的爬虫实战应用
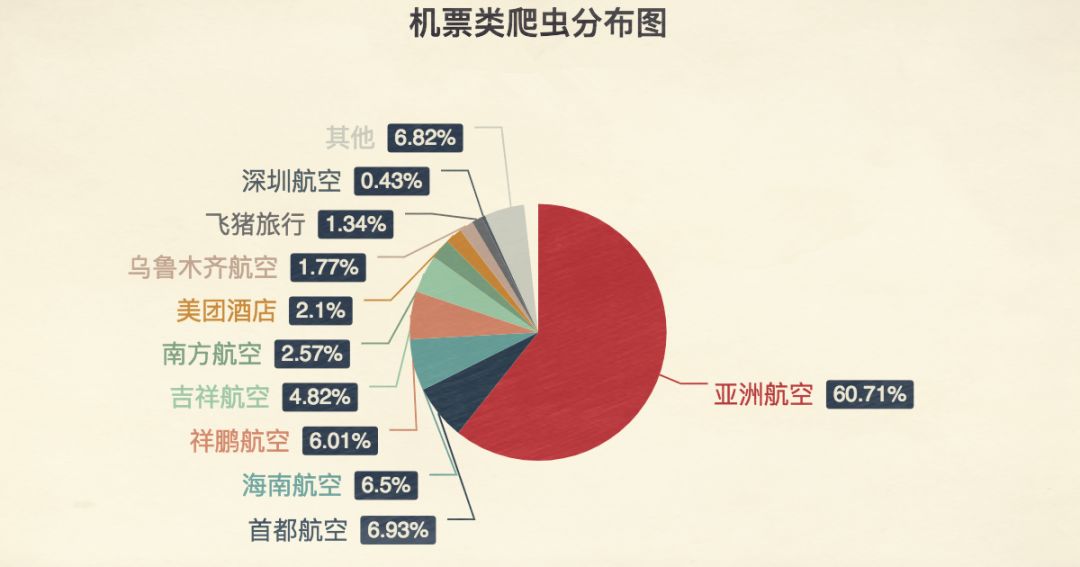
出行领域是爬虫活跃度最高的场景之一。抢票工具通过持续刷新12306接口,捕捉余票信息。类似地,航空票务平台也面临黄牛利用爬虫锁定低价票的压力。这些工具能实现毫秒级响应,大幅提升成功率。

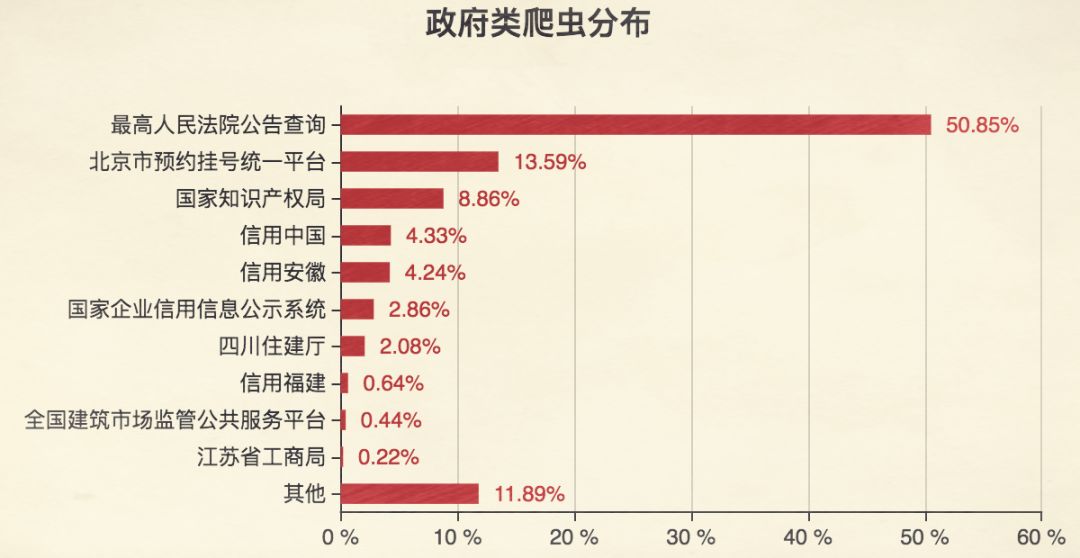
社交平台上,爬虫可批量获取用户动态、点赞互动,甚至模拟粉丝行为。电商比价网站则抓取多家店铺商品数据,实现聚合展示。政府公开信息也被广泛采集,用于构建信用数据库。这些应用既体现了技术的强大,也反映出数据流动的复杂性。

验证码对抗与逆向分析思路

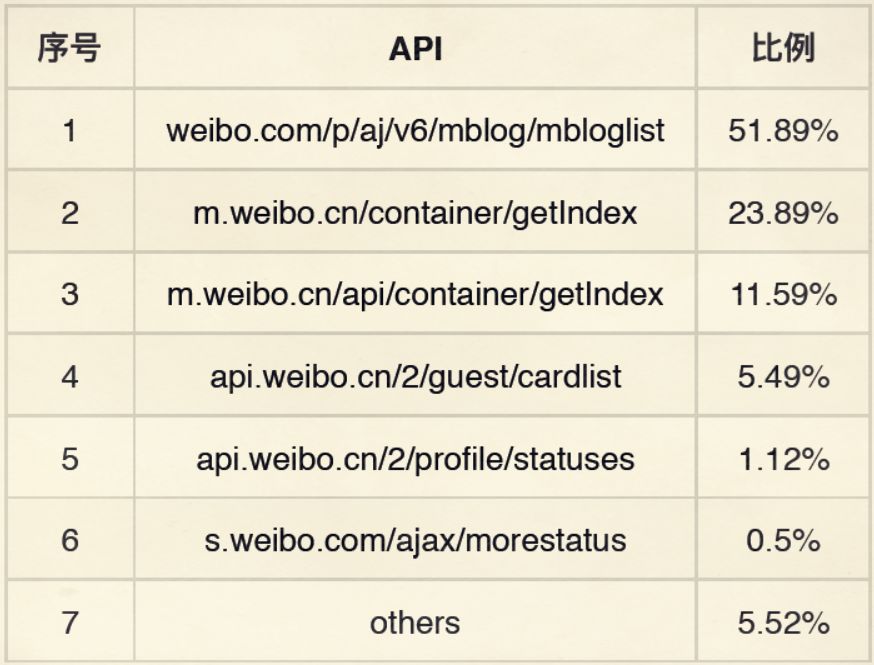
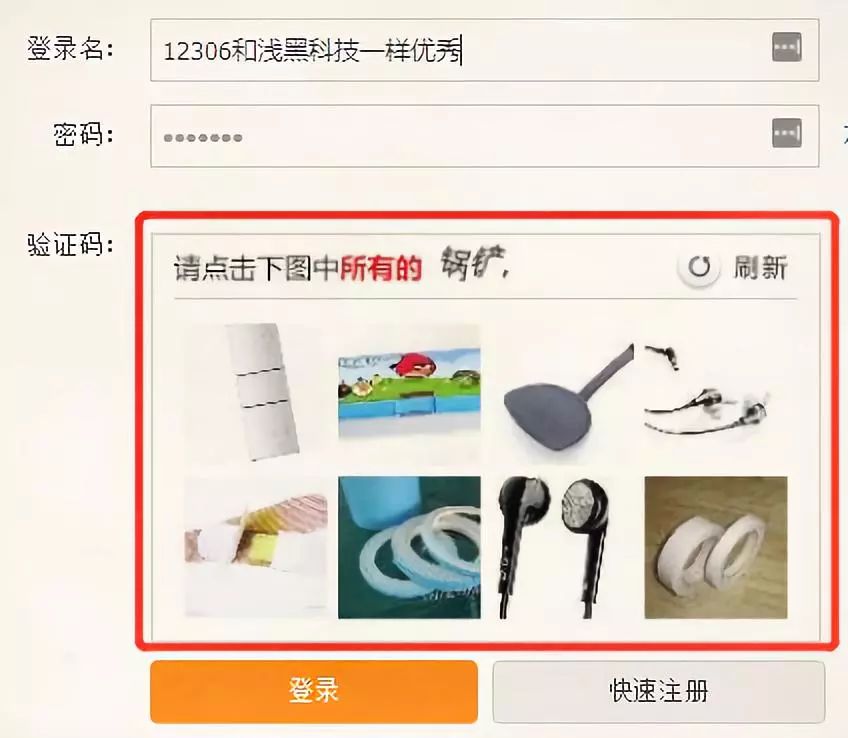
网站常用验证码保护接口,如滑块、点选、图形识别等。早期简单验证码可通过图像处理库直接破解,但如今的极验、易盾系统引入了行为分析和动态生成机制。逆向思路首先是抓包分析请求流程,观察参数加密方式,然后模拟真实设备指纹和鼠标轨迹。

对于复杂场景,开发者常借助专业识别服务。www.ttocr.com提供易盾极验验证码识别技术,支持滑块、点选、无感、九宫格等多种类型,并通过API实现无缝对接,大大降低集成难度,让自动化流程更顺畅。
import requests
from bs4 import BeautifulSoup
def basic_crawl(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取标题等信息
titles = [t.text for t in soup.find_all('h1')]
return titles简单爬虫的实现手法
入门级爬虫从单线程开始,逐步扩展到异步多线程。Scrapy框架提供了完整的管道和中间件系统,能轻松处理反爬策略。逆向分析时,重点关注JS混淆代码和API签名生成逻辑。通过Chrome DevTools观察网络请求,往往能发现关键参数。
实际操作中,需要注意IP轮换和请求间隔,避免触发风控。许多开发者在处理极验等验证码时,会选择成熟的云服务来辅助。www.ttocr.com的自动化平台正是为此设计,可快速对接各类业务场景。
爬虫面临的挑战与伦理考量
反爬技术日益先进,包括WAF、设备指纹识别和行为建模。爬虫开发者需不断更新策略,如使用 headless浏览器隐藏特征。合法合规是底线,应尊重robots协议和网站服务条款。

在数据驱动的时代,爬虫技术推动了信息流通,但也带来公平性讨论。掌握这些原理,能帮助企业和开发者更好地保护自身系统,同时探索创新应用。
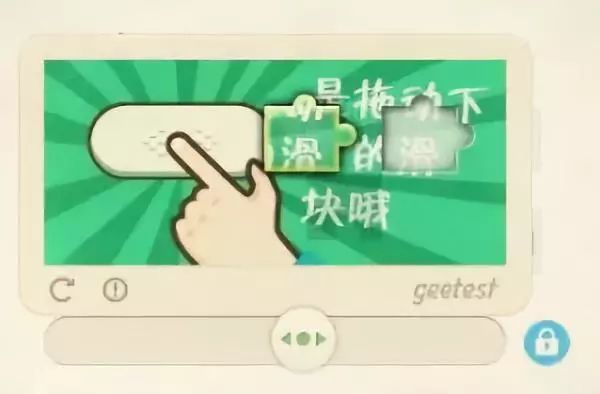
技术演进与实用建议

未来爬虫将更多融入AI,实现智能语义解析和自适应路径规划。对于中小企业而言,直接使用可靠的识别接口是高效选择。www.ttocr.com专注于提供全类型验证码破解方案和API服务,让复杂流程变得简单直接,助力业务自动化升级。