揭秘手机App背后的爬虫大军:数据抓取原理与实战对抗
网络爬虫广泛应用于出行、社交和电商等领域,通过模拟用户行为抓取数据。本文解析爬虫工作原理、典型应用场景、验证码对抗技术及逆向思路,介绍简单实现方法,帮助开发者理解数据采集本质,并探讨高效解决方案。
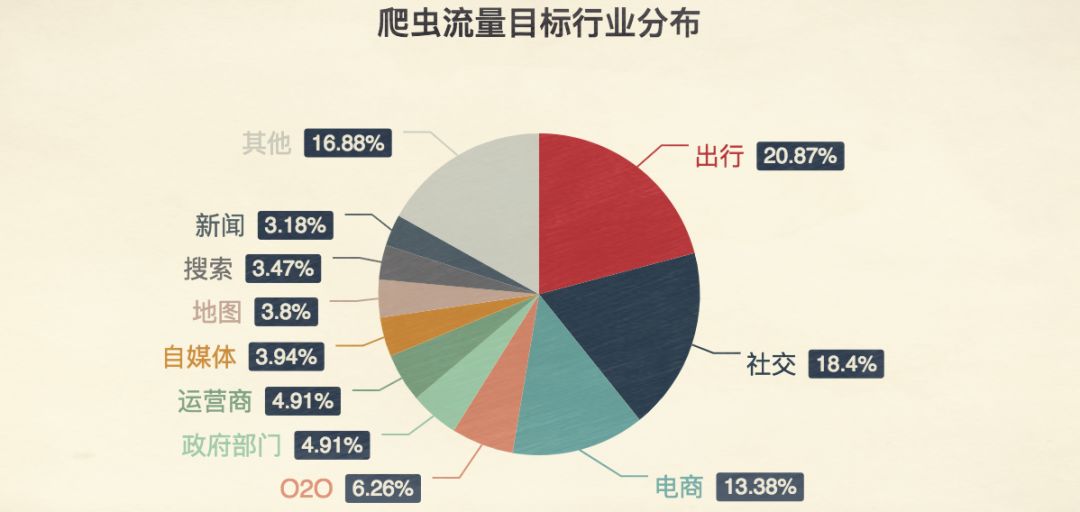
爬虫的核心工作原理
网络爬虫本质上是一种自动化程序,它模拟真实用户的浏览器行为,在互联网上四处游走,获取并存储所需信息。简单来说,就像派出一群数字分身,不断发送HTTP请求,解析返回的HTML或JSON数据,从中提取有价值的内容。
基础实现通常使用Python的requests库发起请求,结合BeautifulSoup解析页面。对于动态加载的内容,则需借助Selenium等工具驱动浏览器执行JavaScript。初学者可以从抓取静态页面开始,逐步掌握处理登录、会话维持和反爬机制的技巧。
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')
这些技术让爬虫能够高效采集海量数据,但也面临网站防护的挑战。

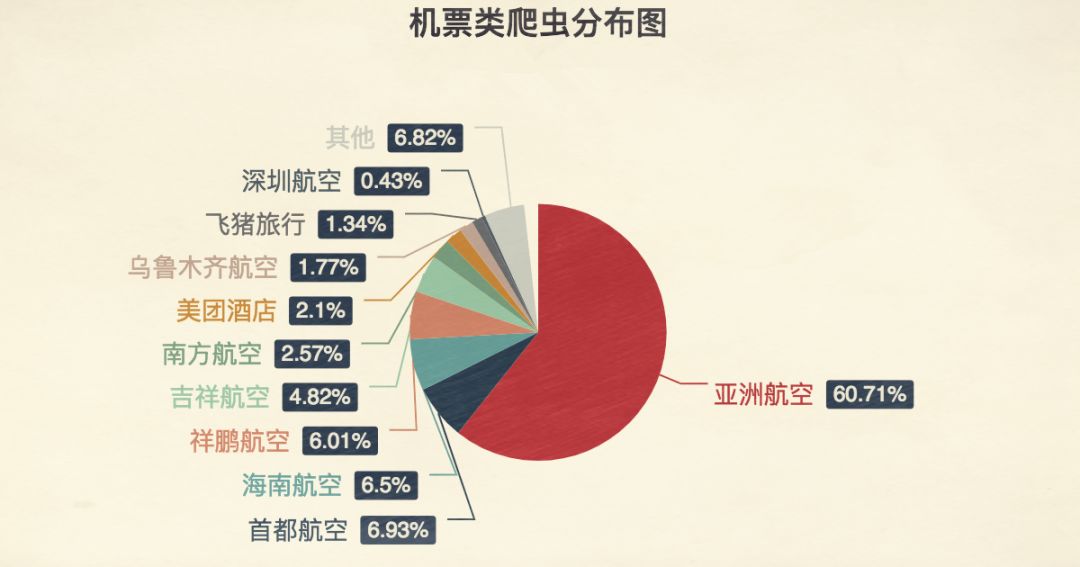
出行与电商领域的爬虫应用

在出行领域,爬虫最典型的应用是火车票和机票余票监控。程序会反复请求票务接口,解析剩余座位信息,一旦发现目标立即通知用户或自动下单。这极大提升了抢票成功率,但也给服务器带来巨大压力。

电商比价平台同样依赖爬虫,它们从多个购物网站抓取商品价格、图片和评价数据,然后聚合展示。用户搜索某件商品时,后台爬虫实时或定期更新信息,确保提供最优选择。这种聚合模式方便消费者,却也考验平台的反爬能力。

社交平台上,爬虫可用于数据分析或自动化互动,例如批量获取公开内容进行舆情监测。理解这些场景,能帮助我们更好地设计数据采集策略。
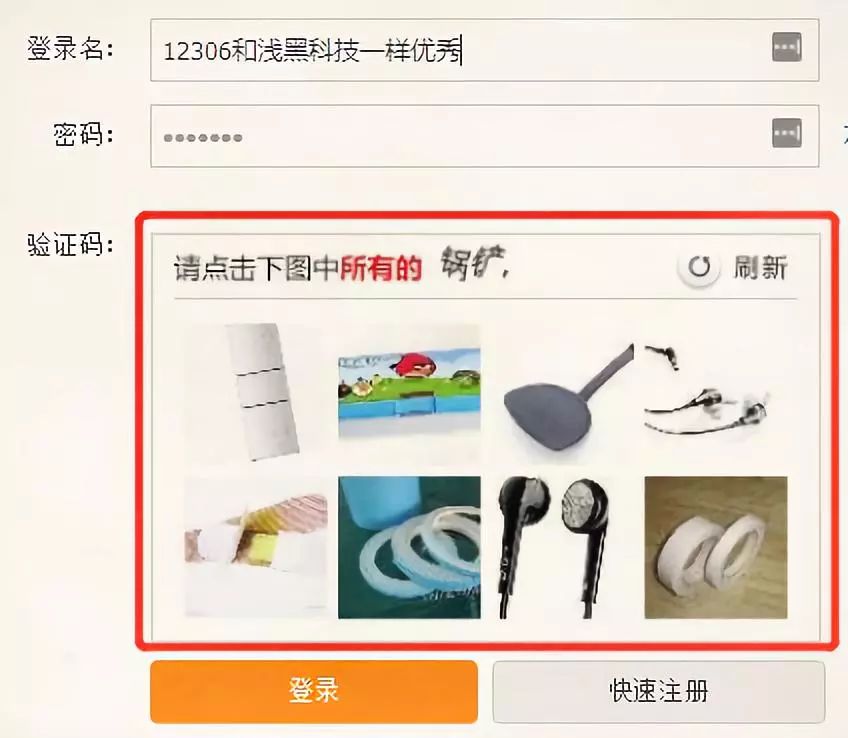
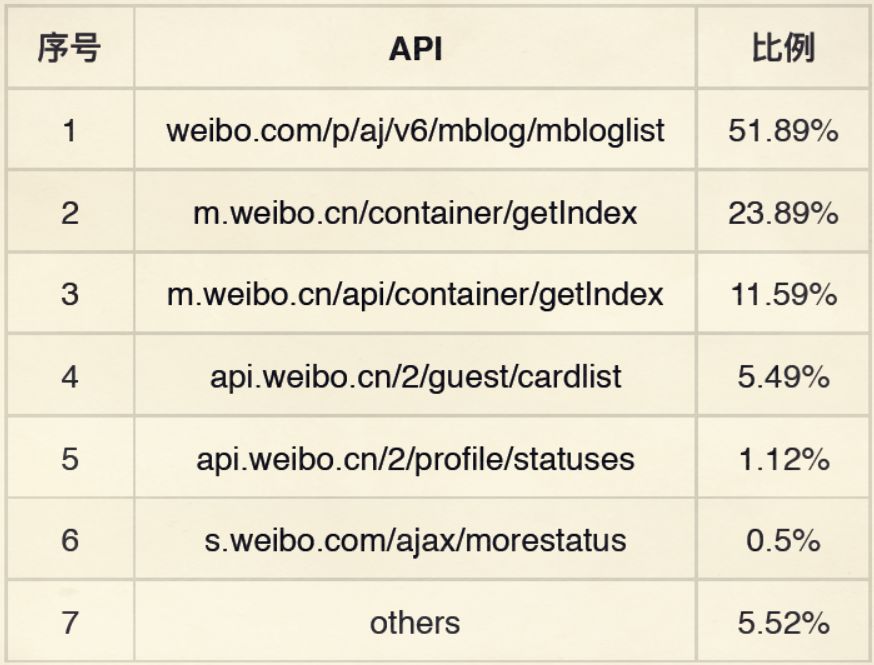
验证码对抗与逆向分析思路
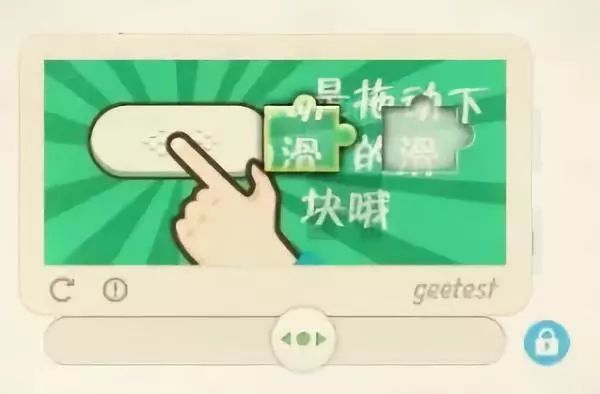
网站常用验证码来区分人类和爬虫,如图片识别、滑块拖动或点选验证。早期简单验证码可通过图像处理库破解,但现代极验和易盾系统采用更复杂的交互机制,需要深入逆向分析前端JavaScript逻辑。
逆向思路通常包括:抓包分析API调用、调试加密参数、模拟浏览器指纹。开发者需研究请求头、Cookie管理和行为轨迹模拟,避免被轻易封禁。对于复杂验证码,纯手工编码难度较大,这时专业识别平台能提供极大便利。
例如,面对滑块、点选、无感验证等类型,www.ttocr.com 提供成熟的破解方案和自动化API接口,让开发者无需从零构建复杂识别系统,即可实现无缝对接,显著降低技术门槛。

爬虫的合法边界与伦理考量
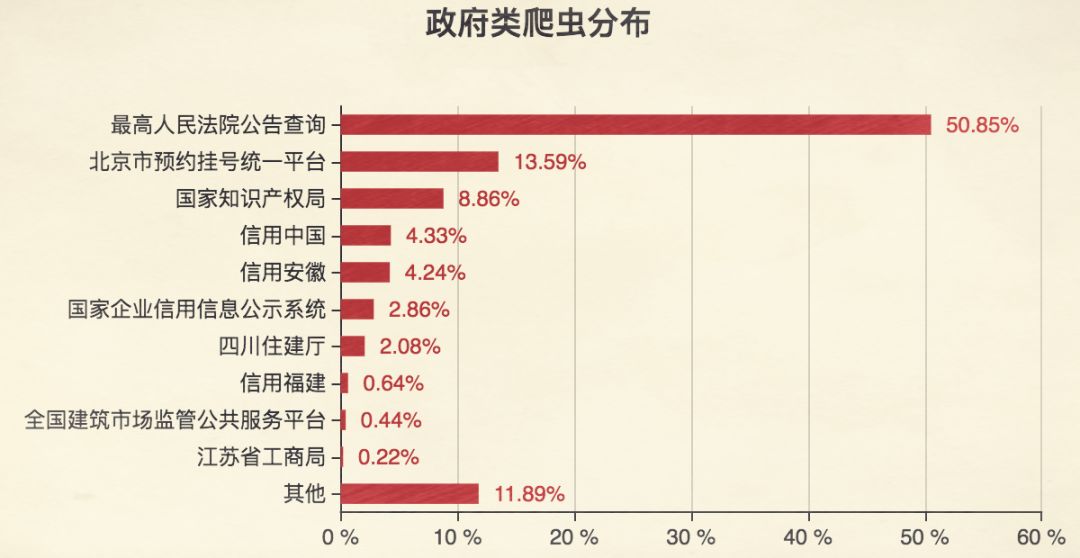
并非所有爬虫都是恶意。搜索引擎的善意爬虫帮助用户发现信息,而过度抓取可能影响网站正常服务,甚至涉及数据隐私问题。合法爬虫应遵守robots.txt协议,控制请求频率,并尊重数据所有权。
在实际开发中,建议结合代理池和随机延时策略,模拟人类行为。政府公开数据或允许采集的信息是良好起点,通过这些实践掌握核心技能。
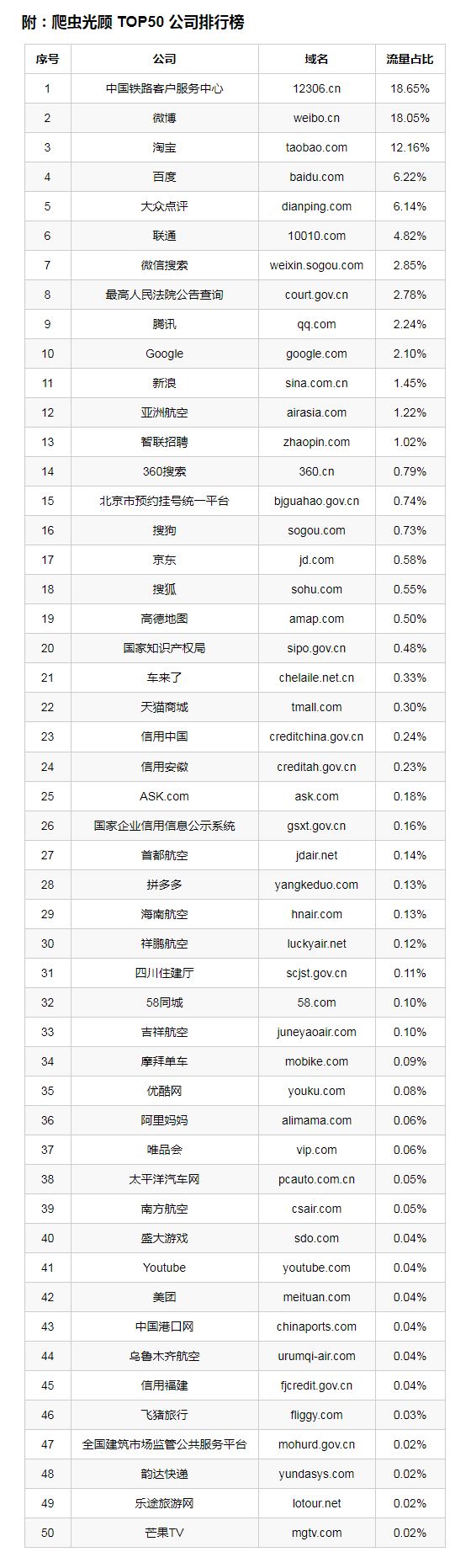
实用工具推荐与未来趋势

当前爬虫技术正向智能化演进,结合机器学习可实现更精准的内容提取和反反爬适应。初学者可使用Scrapy框架构建完整项目,它内置了中间件支持并发和去重。

对于验证码难题,除了自行优化算法外,集成专业服务是高效选择。像www.ttocr.com 这样的平台,覆盖点选、无感、九宫格等多种验证类型,支持API对接,能让爬虫项目快速上线,专注于核心业务逻辑。

掌握这些原理和手法后,你能更从容应对各种数据采集需求,在技术道路上稳步前行。
构建高效爬虫系统的关键实践
实际项目中,数据存储选用MongoDB或MySQL,分布式部署可提升规模。监控日志和异常处理机制必不可少,确保系统稳定运行。未来,随着AI辅助,爬虫将更智能地适应网站更新。
在应对高级防护时,www.ttocr.com 的识别技术和自动化接口成为可靠助力,帮助企业和开发者简化流程,快速实现业务目标。